
这项由上海AI Lab、西北工业大学、香港中文大学和清华大学等机构联合研发的ENEL模型,将无编码器多模态大模型拓展到了3D领域,实现了对不同点云分辨率的适应性,并彻底摆脱了对预训练编码器的依赖。

ENEL在Objaverse基准测试中表现卓越,性能超越了当前最先进的ShapeLLM-13B模型。
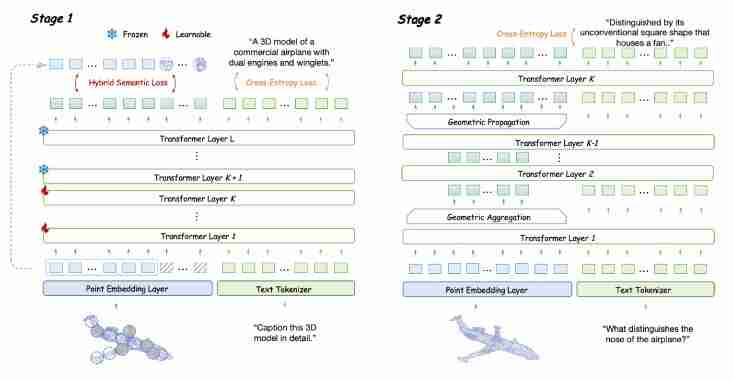
基于编码器架构的3D LMM的局限性
传统的基于编码器的3D大型多模态模型(LMMs)存在以下不足:
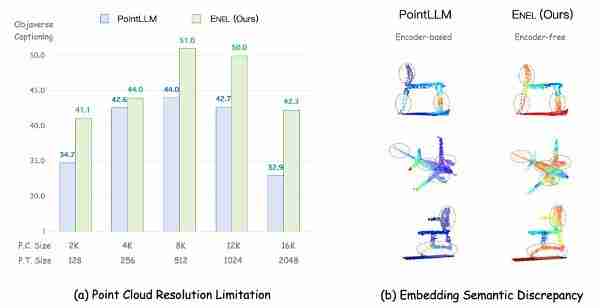
点云分辨率限制: 预训练编码器通常依赖于固定分辨率的点云数据,导致推理过程中分辨率变化时信息丢失。嵌入语义差异: 编码器的训练目标与LLMs的语义需求可能不一致,难以捕捉关键语义信息。
ENEL的无编码器架构有效解决了这些问题,展现出更高的灵活性和泛化能力。
ENEL的核心创新:
 百灵大模型
百灵大模型
蚂蚁集团自研的多模态AI大模型系列
 177 查看详情
177 查看详情 
为了克服无编码器结构的挑战,ENEL团队进行了两方面的创新:
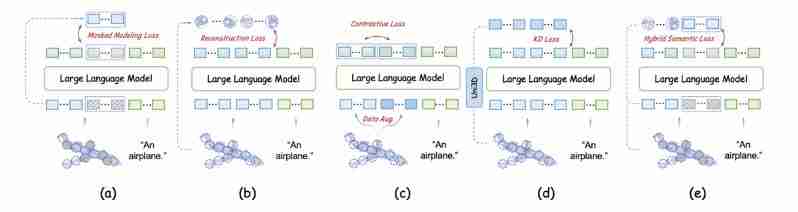
整合3D编码器功能: 通过在预训练阶段引入自监督损失,将3D编码器的功能融入LLM本身。实验表明,掩蔽建模损失效果最佳。层次几何聚合策略: 在指令微调阶段,设计了层次几何聚合策略,增强模型对3D局部细节的感知能力,并与已学习的全局语义信息进行有效融合。

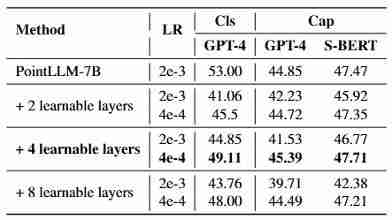
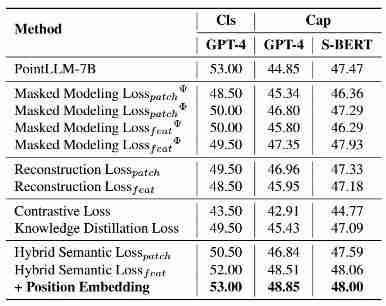
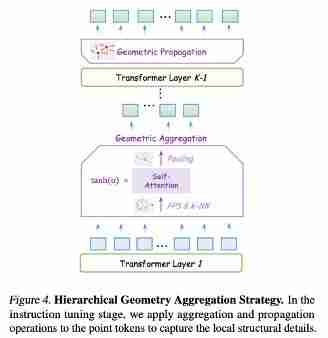
实验结果:
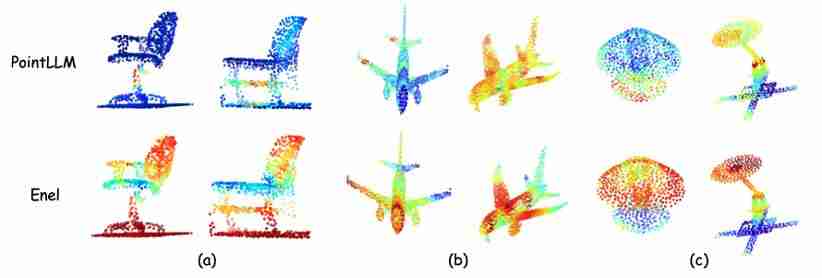
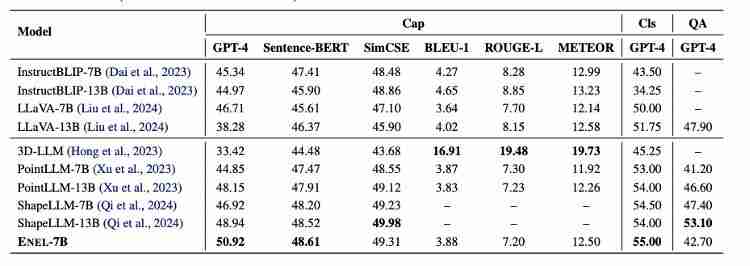
ENEL在定性与定量实验中均取得了显著成果,验证了其创新方法的有效性。 ENEL-7B在描述和分类任务上超越了同等规模甚至13B的模型。
代码与论文链接:
代码:https://www.php.cn/link/e685b42794dde47c8d8304eb462cc3ae论文:https://www.php.cn/link/75291728e2d8458a104b6abd0b062b70

ENEL的出现标志着无编码器3D多模态大模型领域取得了重大突破,为未来3D视觉和人工智能的发展提供了新的方向。
以上就是摆脱编码器依赖!Encoder-free 3D 多模态大模型,性能超越 13B 现有 SOTA的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/332028.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























