
模态
-
显著超越 SFT,o1/DeepSeek-R1 背后秘诀也能用于多模态大模型了
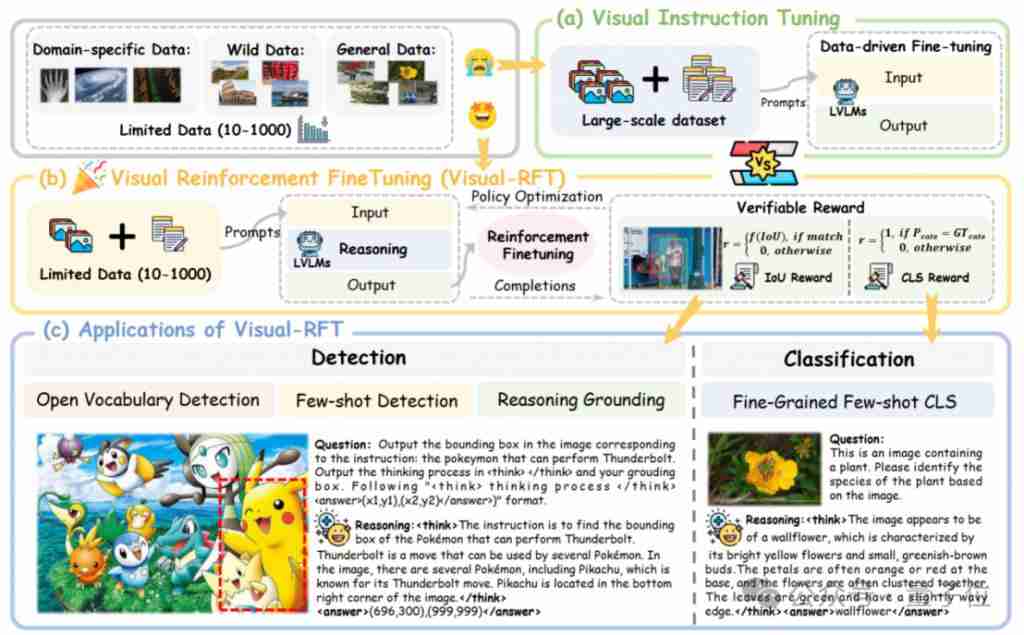

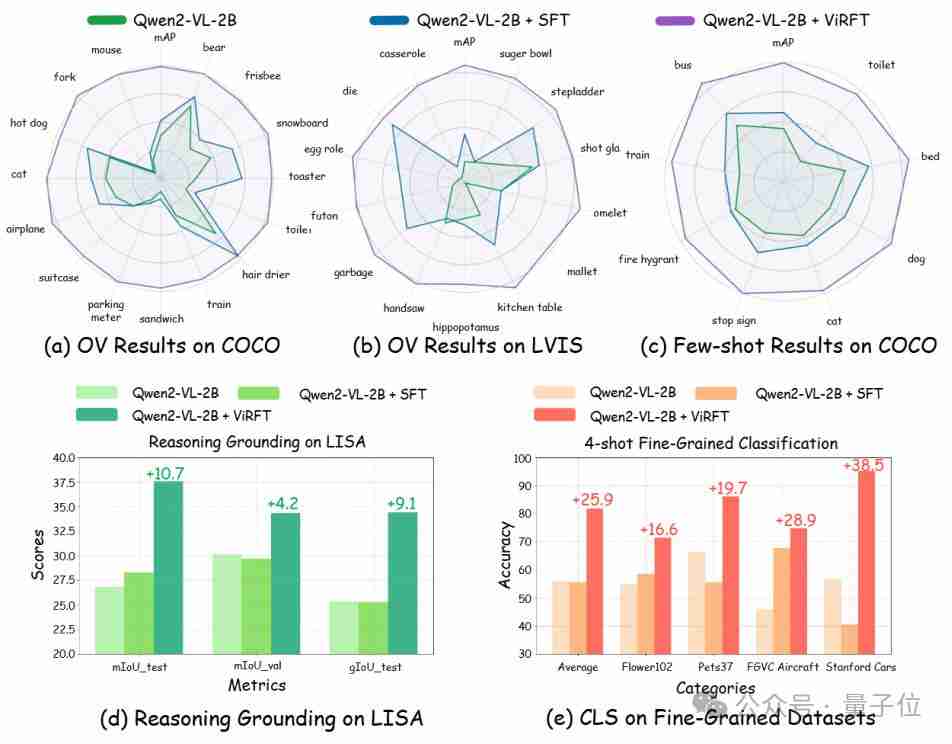
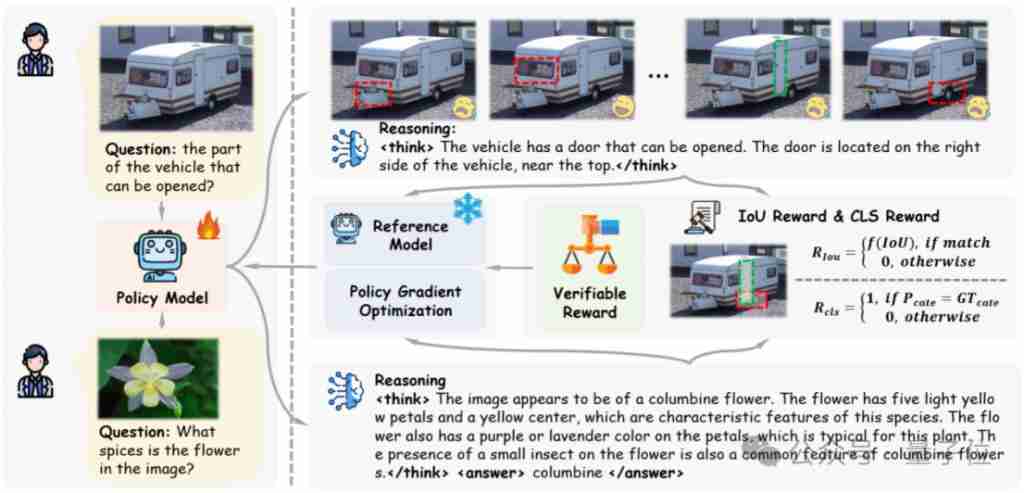
上海交大、上海ai lab和港中文大学的研究人员推出visual-rft(视觉强化微调)开源项目,该项目仅需少量数据即可显著提升视觉语言大模型(lvlm)性能。visual-rft巧妙地将deepseek-r1的基于规则奖励的强化学习方法与openai的强化微调(rft)范式相结合,成功地将这一方法…
-
多模态 AI+ 折叠形态!三星 Galaxy AI 体验沙龙速览


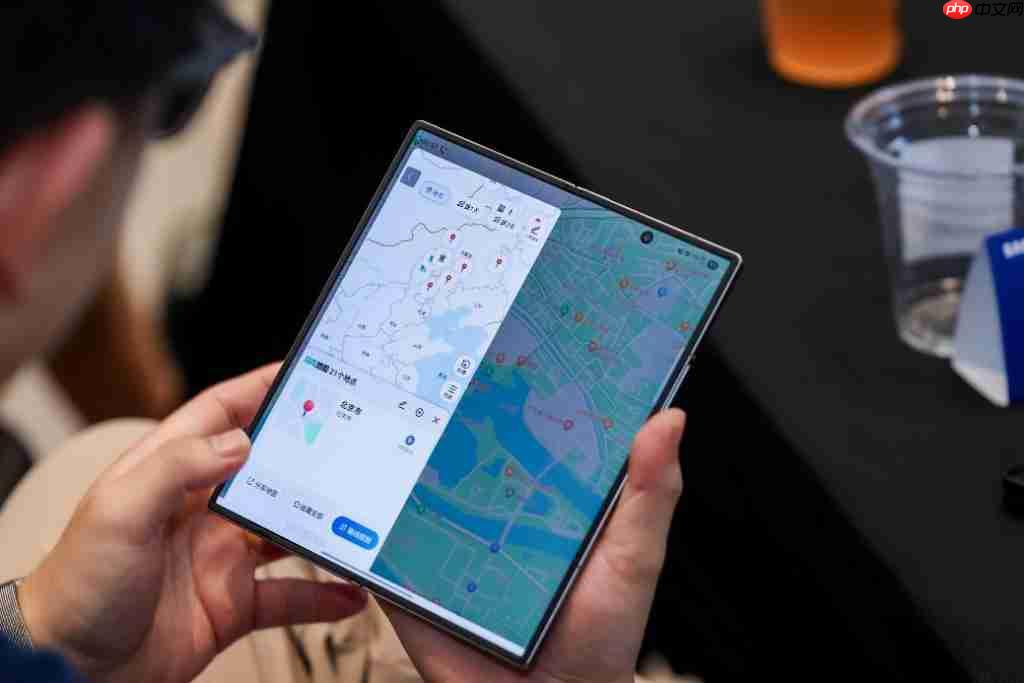
7 月 29 日,三星在广州举办了一场 galaxy ai 体验沙龙,集中呈现了 galaxy z 系列新品在 ai 功能方面的最新进展,深入探讨 ai 技术如何融入并优化用户的日常生活场景。作为特邀体验官,pconline 亲临现场,实地感受了多款新品搭载的前沿 ai 能力。 折叠屏设计,如何激发…
-
4 秒看完 2 小时电影!阿里发布通用多模态大模型 mPLUG-Owl3

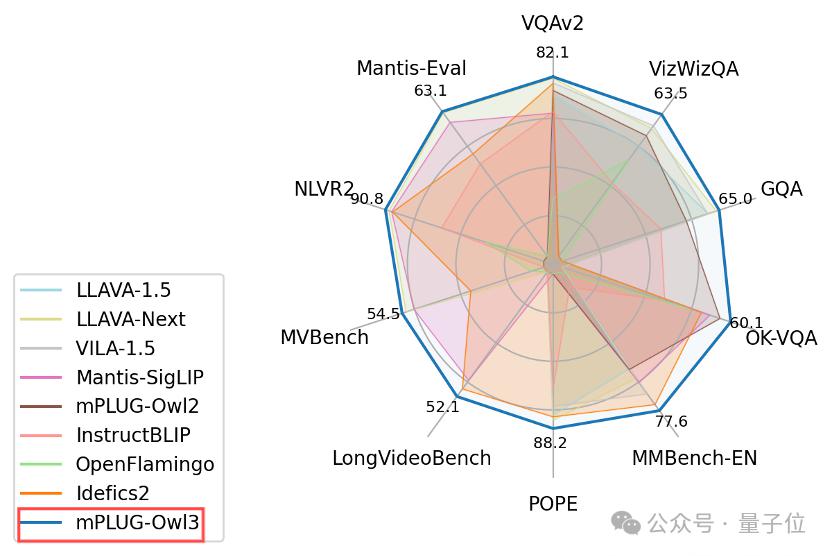


4 秒看完 2 小时电影,阿里团队新成果正式亮相—— 推出通用多模态大模型 mPLUG-Owl3,专门用来理解多图、长视频。 具体来说,以 LLaVA-Next-Interleave 为基准,mPLUG-Owl3 将模型的First Token Latency 缩小了 6 倍,且单张 A100 能建…
-
摆脱编码器依赖!Encoder-free 3D 多模态大模型,性能超越 13B 现有 SOTA

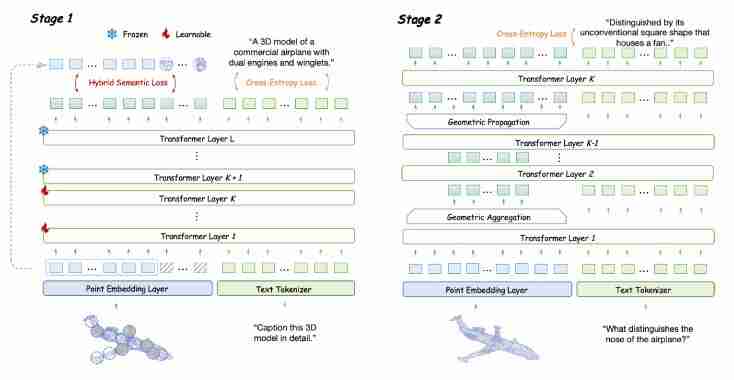
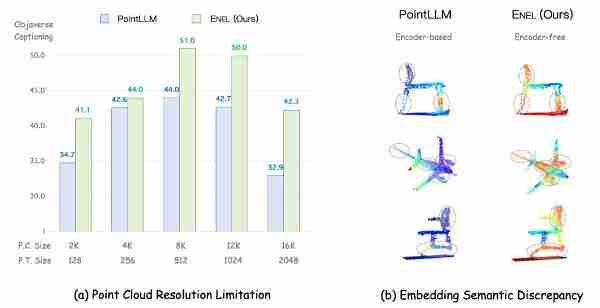

突破性进展:无编码器3d多模态大模型enel问世! 这项由上海AI Lab、西北工业大学、香港中文大学和清华大学等机构联合研发的ENEL模型,将无编码器多模态大模型拓展到了3D领域,实现了对不同点云分辨率的适应性,并彻底摆脱了对预训练编码器的依赖。 ENEL在Objaverse基准测试中表现卓越,性…
