根据 Gimlet Labs 的最新研究成果,AI 已能够自动生成高度优化的 Metal 内核,使 PyTorch 的推理速度提升了87%。这项技术突破不仅显著增强了性能表现,还在测试涵盖的215个 PyTorch 模块上实现了平均1.87倍的加速效果,部分特定工作负载甚至达到了数百倍的速度提升。
研究团队选用了来自 Anthropic、DeepSeek 和 OpenAI 等领先人工智能机构的八个先进模型,利用它们为苹果设备定制高效的 GPU 内核代码。整个过程无需更改用户原有代码,也不依赖新框架的引入,即可在苹果硬件平台上直接实现性能飞跃。
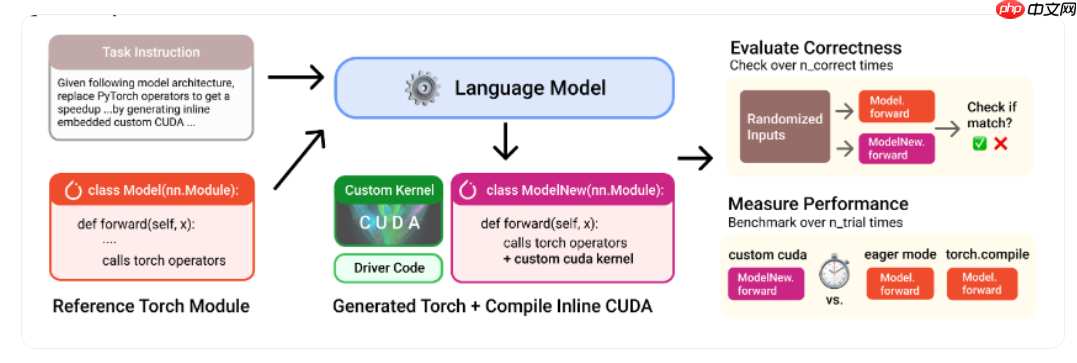
实验平台采用搭载 Apple M4 Max 芯片的 Mac Studio,以 PyTorch 的 eager 模式作为性能基准。测试使用的 KernelBench 数据集包含215个典型 PyTorch 模块,覆盖从基础的矩阵乘法运算到完整神经网络架构等多种场景。
测试流程包括接收输入参数和原始 PyTorch 代码、自动生成对应的 Metal 内核,并验证其功能正确性。数据表明,随着生成尝试次数增加,AI 输出内核的准确性持续提升。例如,在第五次尝试时,正确实现的比例已达到94%。值得注意的是,尽管部分非专为推理设计的模型也具备生成有效内核的能力,显示出跨任务适应的潜力。
 百度妙笔
百度妙笔
百度旗下AI创意生成平台
 443 查看详情
443 查看详情 
实验结果显示,GPT-5 在某些模块中实现了高达4.65倍的性能提升。更引人注目的是,o3 模型在个别任务中将延迟降低了惊人的9000倍。研究还发现,并非单一模型在所有任务中都表现最优,结合多个模型的优势可进一步提升内核质量与执行效率。
为进一步增强生成效果,研究人员引入了额外上下文信息,如 CUDA 实现代码和 gputrace 提供的性能追踪数据。该策略使平均加速比提升至1.87倍,相较仅使用基础智能体的1.31倍,性能增益提升了约三成。
研究团队特别指出,本项目的核心目标并非追求极致性能上限,而是验证 AI 在自动内核生成方面的可行性,旨在通过智能化手段减轻开发者的底层优化负担。总体来看,这一成果标志着人工智能在硬件级系统优化方向迈出的关键一步。
以上就是AI 生成优化 Metal 内核,PyTorch 推理速度提升 87%的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/358681.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫