
大型语言模型(llm)在数学竞赛基准测试中表现出色,得分动辄80%甚至90%以上,但在实际应用中却往往表现不佳。对此,上海人工智能实验室司南opencompass团队开发了新的复杂数学评测集livemathbench,并引入了新的性能指标g-pass@16,以更全面地评估模型的性能潜力和稳定性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

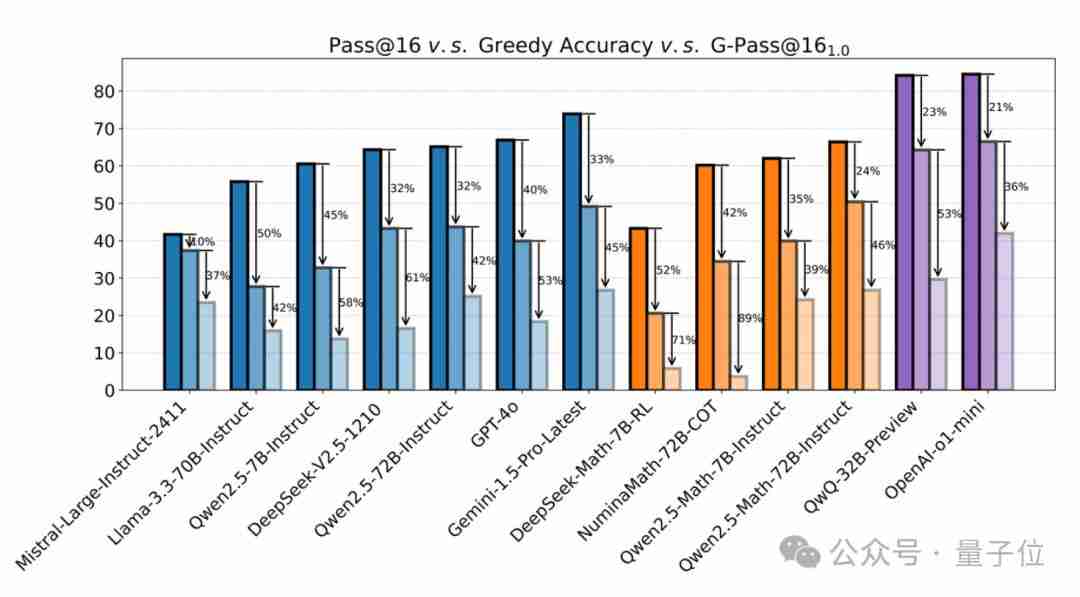
该团队通过模拟真实用户使用场景,对多个LLM进行了多次测试,结果显示:大多数模型的性能平均下降超过50%,即使是最强的推理模型o1-mini也下降了36%。有些模型的性能下降甚至高达90%。
G-Pass@k:兼顾性能潜力与稳定性的新指标
研究团队对传统指标如Pass@k、Best-of-N和Majority Voting进行了改进,这些指标主要关注模型的潜在能力,而忽略了鲁棒性。在实际应用中,模型常采用采样解码,这会引入随机性,影响模型的性能。用户期望模型在真实场景中表现稳定可靠。
因此,团队提出了G-Pass@k指标,它通过引入阈值,评估模型在多次生成中至少给出一定数量正确答案的概率。 当阈值较低时,G-Pass@k反映模型的性能潜力;当阈值较高时,它反映模型的稳定性。 Pass@k实际上是G-Pass@k在阈值为1时的特例。
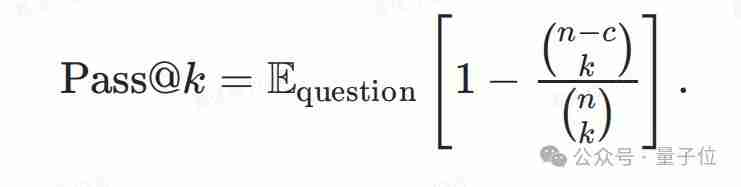
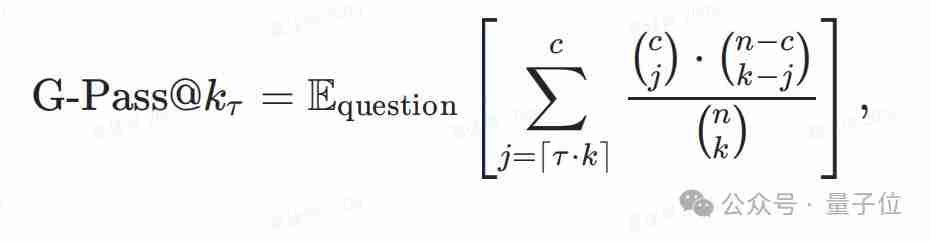
团队还定义了mG-Pass@k,它是G-Pass@k曲线的面积,用于整体评估模型性能,尤其关注0.5到1.0之间的阈值范围。
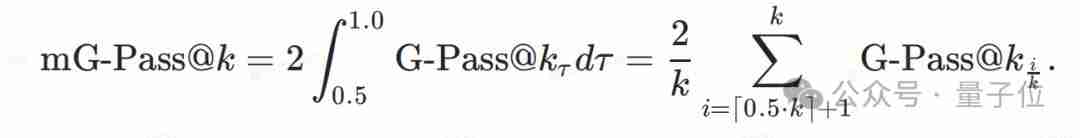
LiveMathBench:一个更真实的评测集
为了进行更客观的评估,团队构建了LiveMathBench,该数据集包含来自中国数学奥林匹克、中国高考模拟题、美国数学竞赛和普特南数学竞赛的题目,尽可能减少数据污染。 LiveMathBench (202412版本) 包含238道题目,提供中英文双版本。 团队计划持续更新该数据集。 实验还涵盖了MATH500-L5和AIME2024-45两个公开基准数据集。
 百川大模型
百川大模型
百川智能公司推出的一系列大型语言模型产品
 62 查看详情
62 查看详情 
实验结果与分析
实验中,每个题目进行了48次(16次采样*3次重复)生成,并报告G-Pass@16分数。结果显示:
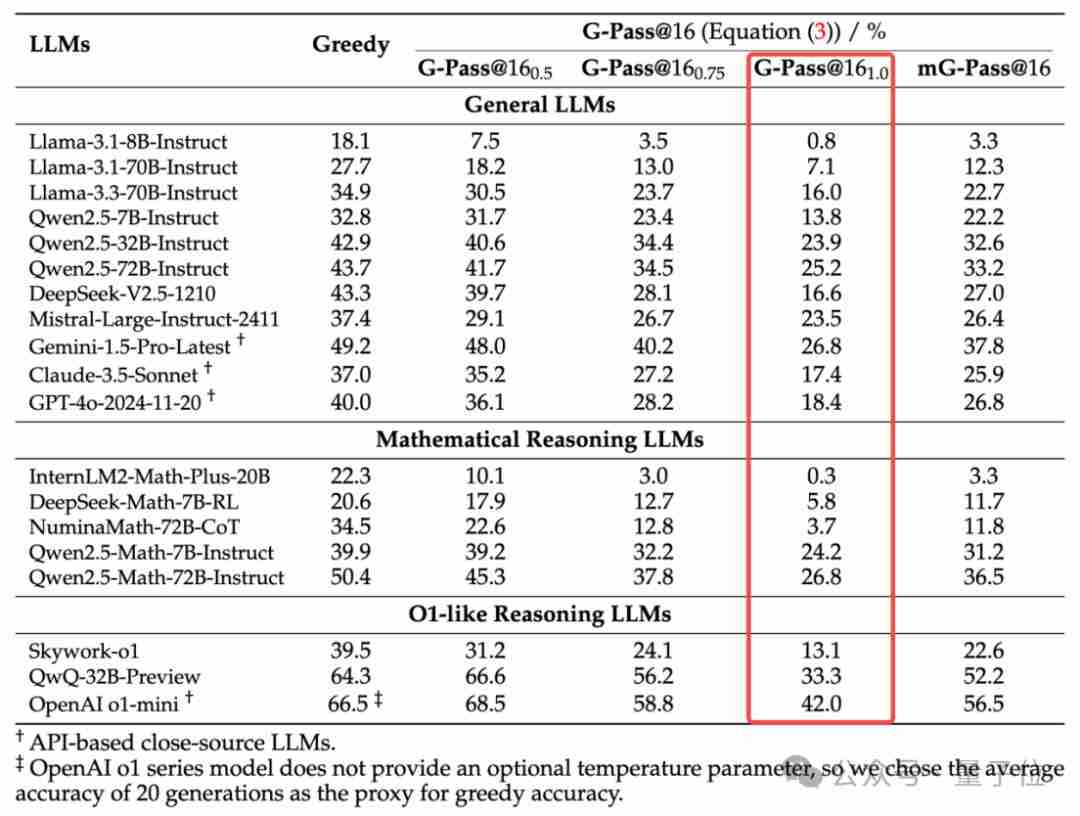
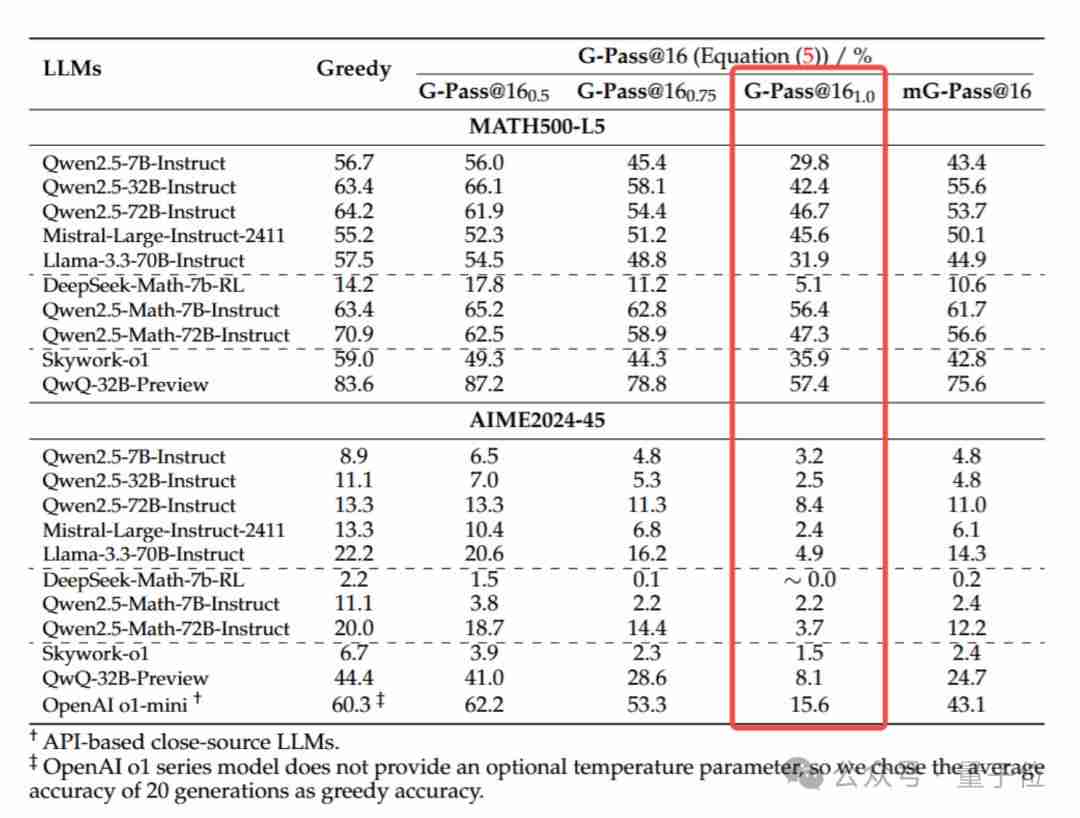
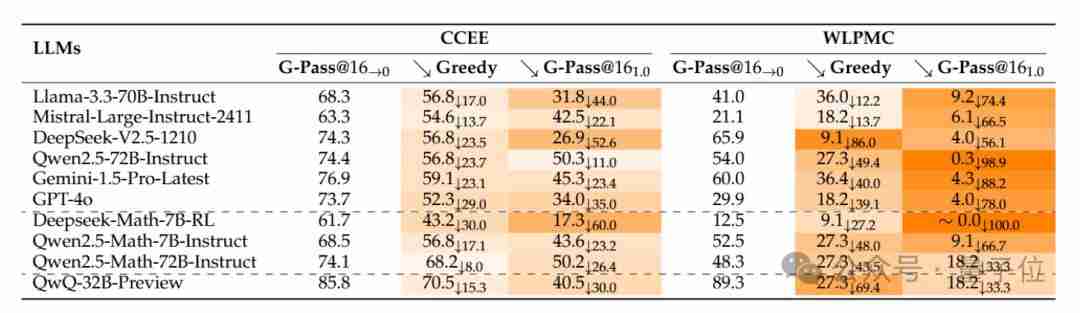
主要观察结果:
稳定性差: 闭源和开源模型在复杂推理任务中的稳定性都非常差,G-Pass@16(1.0) 的分数普遍很低,性能下降幅度巨大。
规模并非万能: 增大模型规模对推理能力的提升有限,甚至可能导致性能下降。
潜力与实际表现差距大: 模型的潜在能力(例如Greedy Accuracy)与实际稳定表现(G-Pass@16(1.0))之间存在巨大差距。
结论
这项研究揭示了当前LLM在复杂数学推理方面的局限性,尤其是在稳定性和鲁棒性方面。 G-Pass@16指标和LiveMathBench数据集为更全面地评估LLM的数学推理能力提供了新的工具,也为未来的研究指明了方向。 研究人员呼吁学术界和工业界关注LLM推理能力的鲁棒性问题。
以上就是GPT-4o数学能力跑分直掉50%,上海AI Lab开始给大模型重新出题了的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/385088.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























