数学评测
-
GPT-4o数学能力跑分直掉50%,上海AI Lab开始给大模型重新出题了

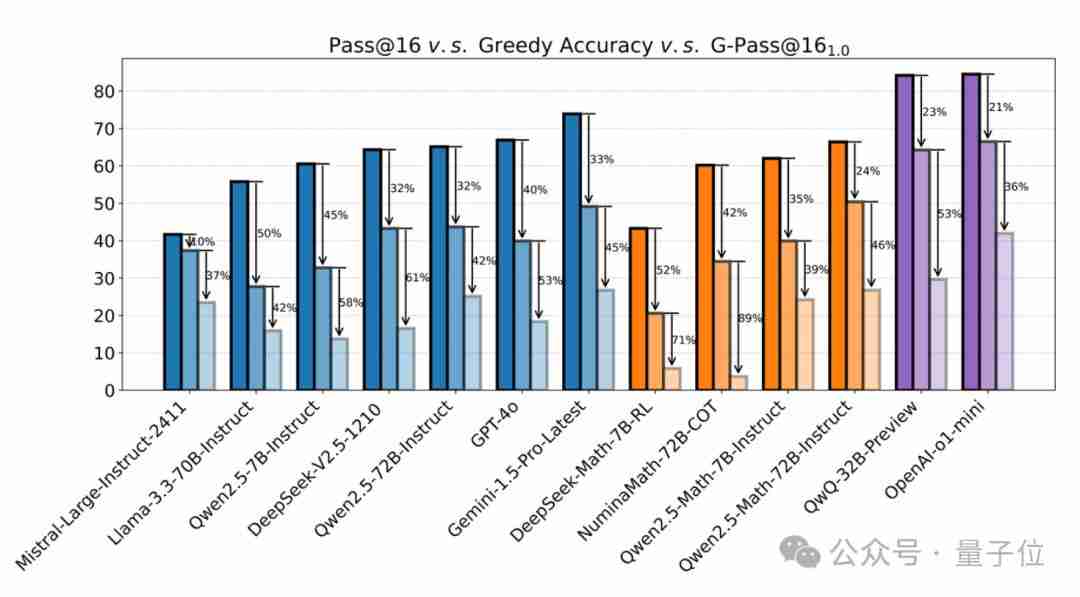
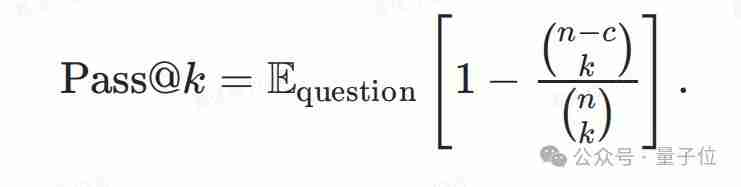
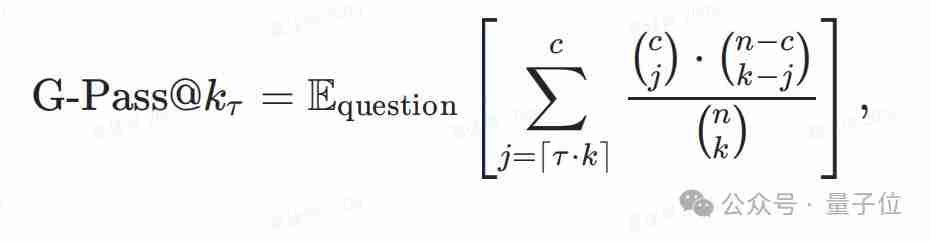
大型语言模型(llm)在数学竞赛基准测试中表现出色,得分动辄80%甚至90%以上,但在实际应用中却往往表现不佳。对此,上海人工智能实验室司南opencompass团队开发了新的复杂数学评测集livemathbench,并引入了新的性能指标g-pass@16,以更全面地评估模型的性能潜力和稳定性。 ☞…

大型语言模型(llm)在数学竞赛基准测试中表现出色,得分动辄80%甚至90%以上,但在实际应用中却往往表现不佳。对此,上海人工智能实验室司南opencompass团队开发了新的复杂数学评测集livemathbench,并引入了新的性能指标g-pass@16,以更全面地评估模型的性能潜力和稳定性。 ☞…
