
斯坦福大学研究团队提出全新多模态语言模型,实现逼真3d人体动作生成与理解。该模型突破性地整合了语音、文本和动作三种模态,能够根据语音和文本指令生成自然流畅的动作,并支持动作编辑。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
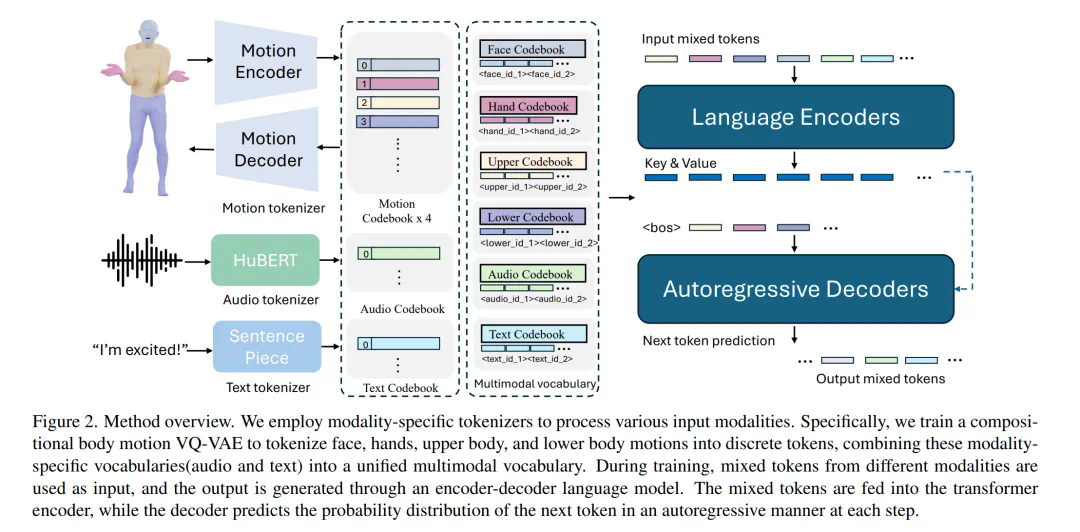
研究人员指出,利用语言模型统一人类动作的言语和非言语表达至关重要,因为它能自然地与其他模态连接,并具备强大的语义推理和理解能力。 该模型采用两阶段训练:首先进行预训练,对齐不同模态,然后进行下游任务训练,使其遵循各种指令。
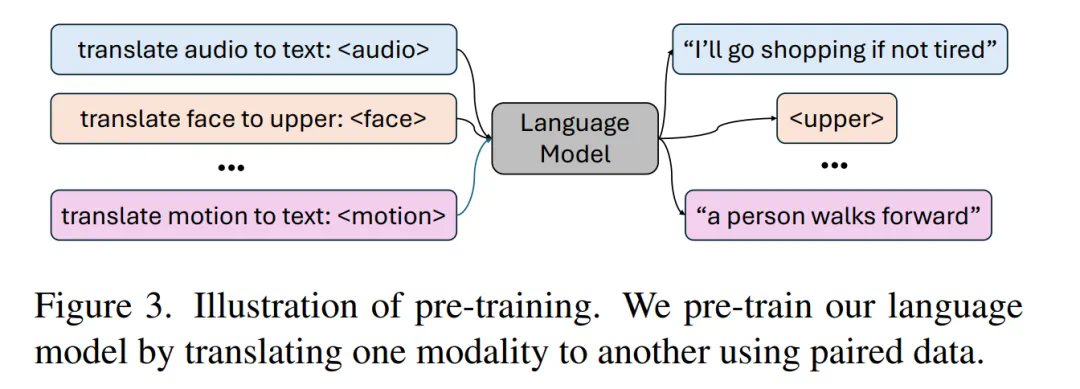
该模型将动作分解为面部、手部、上半身和下半身等不同部位进行token化,再结合文本和语音token化策略,实现多模态输入的统一表示。预训练阶段包含组合动作对齐(空间和时间)和音频-文本对齐两种任务,以学习动作的时空先验和模态间关联。


 百灵大模型
百灵大模型
蚂蚁集团自研的多模态AI大模型系列
 177 查看详情
177 查看详情 
实验结果表明,该模型在伴语手势生成等任务上超越现有SOTA模型,尤其在数据稀缺的情况下优势显著。 它能够根据语音和文本指令生成协调一致的动作,并支持将“绕圈走”等动作替换为其他动作序列,保持动作的自然流畅。

此外,该模型还展现了出色的泛化能力和在动作情绪预测任务中的潜力。这项研究为李飞飞教授的“空间智能”研究目标做出了重要贡献。
论文标题:The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion论文地址:https://www.php.cn/link/c5b3966bd2d4c690da368b3ecbece868项目页面:https://www.php.cn/link/f9ab9a0f7c56435e35dc4dadf0eb6945
以上就是李飞飞团队统一动作与语言,新的多模态模型不仅超懂指令,还能读懂隐含情绪的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/385340.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















