本文介绍Swin Transformer相关知识,对比其与ViT的区别:Swin采用窗口理念和不同下采样倍数,减少计算量且提升性能。还讲解了其Patch层、PatchMerging层、Mlp层及Swin Transformer Block层的实现,包括各层作用、代码和参数等。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

前情提要
大家好呀,VIsion Transformer已经到第六天了随着时间的推移,难度也是在也来越大的,相信大家已经从ResNet学习到了ViT Transformer再到Diet,今天更是学习到了2021的ICCV最佳论文Swin Transformer,Swin Transformer今年在各大磅单上更是直接屠榜,COCO验证集前8全是使用Swin刷榜,而Swin原本的论文才是第八,前七全是Swin的再创新,https://paperswithcode.com/sota/object-detection-on-coco-minival?p=end-to-end-semi-supervised-object-detection 。如果今天的笔记能够帮助到你那么绝对是我莫大的荣幸。
Swin 与 VIT 的区别
Swin 与 Vit 的区别可以用一张图来说明
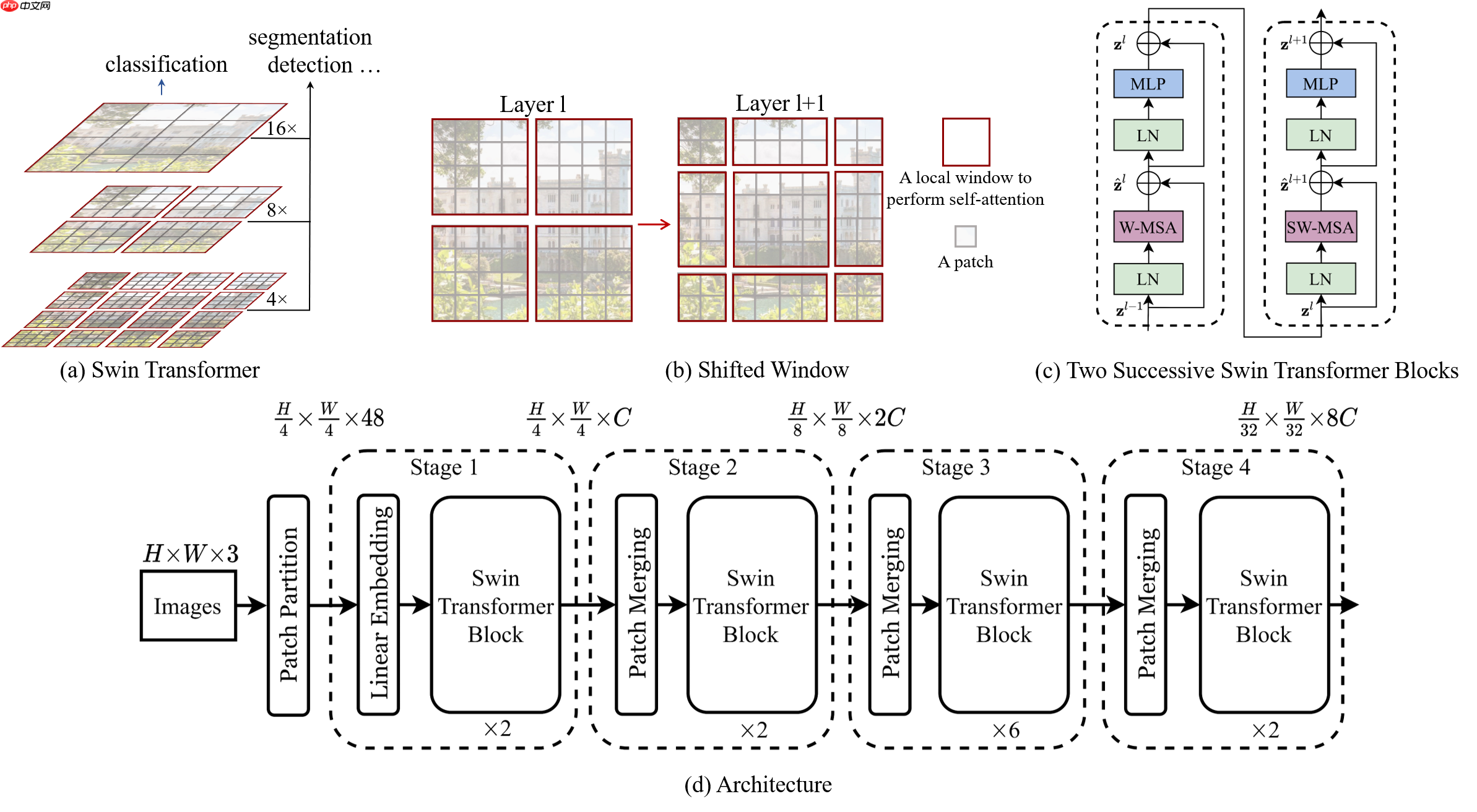
相比较Vit直接下采样16倍,Swin使用了窗口的理念,并使用不同的下采样倍数,并且不同的窗口的计算是互不干扰的,这样相比较Vit,大大减少了计算量并有效的获得了性能上的提升
Patch层讲解
如果你已经学过ViT的话,你应该知道VIT拥有一个PatchEmbedding层它负责将一批RGB图像由四维映射成为三维
[B,C,H,W]->[B,H*W/N/N,C*N*N]
而Swin中PatchEmbedding 的职责由Patch Partition承担,由于朱老师的PPT暂未放出所以这里引用的B站up霹雳吧啦Wz的PPT。
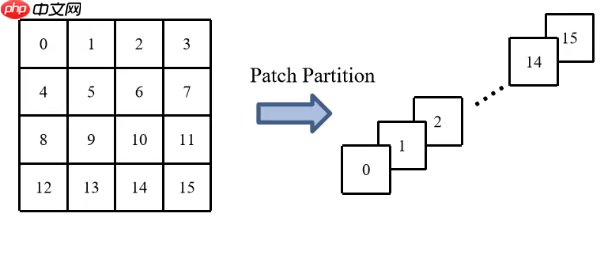
由于Swin Transformer不像VIt一样,Swin Fransformer是多次下采样,第一次下采样使用的是4×4的卷积核
之后会通过一个全链接层也叫Linear Embedding层将通道数由48转换为C,而其全貌则为。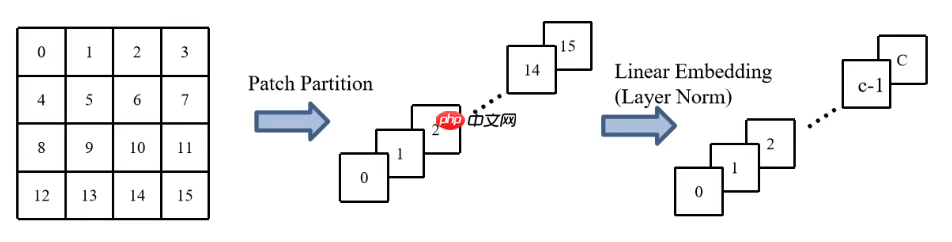
但是在Swin Transformer的代码实现中是直接将Patch Partition与Linear Embedding合而为一,直接使用一个卷积核4×4大小 stride为4的卷积核直接将通道数由3转换为C。
In [1]
import paddleimport paddle.nn as nn
In [2]
class PatchEmbed(nn.Layer): """ 2D Image to Patch Embedding """ def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=nn.LayerNorm): super().__init__() patch_size = (patch_size, patch_size) self.patch_size = patch_size self.in_chans = in_c self.embed_dim = embed_dim self.proj = nn.Conv2D(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() def forward(self, x): _, _, H, W = x.shape # # padding # # 如果输入图片的H,W不是patch_size的整数倍,需要进行padding # pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0) # if pad_input: # # to pad the last 3 dimensions, # # (W_left, W_right, H_top,H_bottom, C_front, C_back) # x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1], # 0, self.patch_size[0] - H % self.patch_size[0], # 0, 0)) # 下采样patch_size倍 x = self.proj(x) _, _, H, W = x.shape # flatten: [B, C, H, W] -> [B, C, HW] # transpose: [B, C, HW] -> [B, HW, C] x = paddle.transpose(x.flatten(2),(0,2,1)) x = self.norm(x) print(x.shape) return x, H, W
In [3]
model = PatchEmbed()paddle.summary(model,(8,3,224,224))
[8, 3136, 96]--------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # =========================================================================== Conv2D-1 [[8, 3, 224, 224]] [8, 96, 56, 56] 4,704 LayerNorm-1 [[8, 3136, 96]] [8, 3136, 96] 192 ===========================================================================Total params: 4,896Trainable params: 4,896Non-trainable params: 0---------------------------------------------------------------------------Input size (MB): 4.59Forward/backward pass size (MB): 36.75Params size (MB): 0.02Estimated Total Size (MB): 41.36---------------------------------------------------------------------------
{'total_params': 4896, 'trainable_params': 4896}
PatchMerging讲解
由于Swin需要经理四次下采样,而第一次下采样是由patchemmedding 层进行处理,而之后还有三次就是由PatchMerging进行。PatchMerging会将特征图的宽和高再次下采样两倍,并且使得通道数Cx2。这里引用的图解也是引用的B站up霹雳吧啦Wz的PPT。
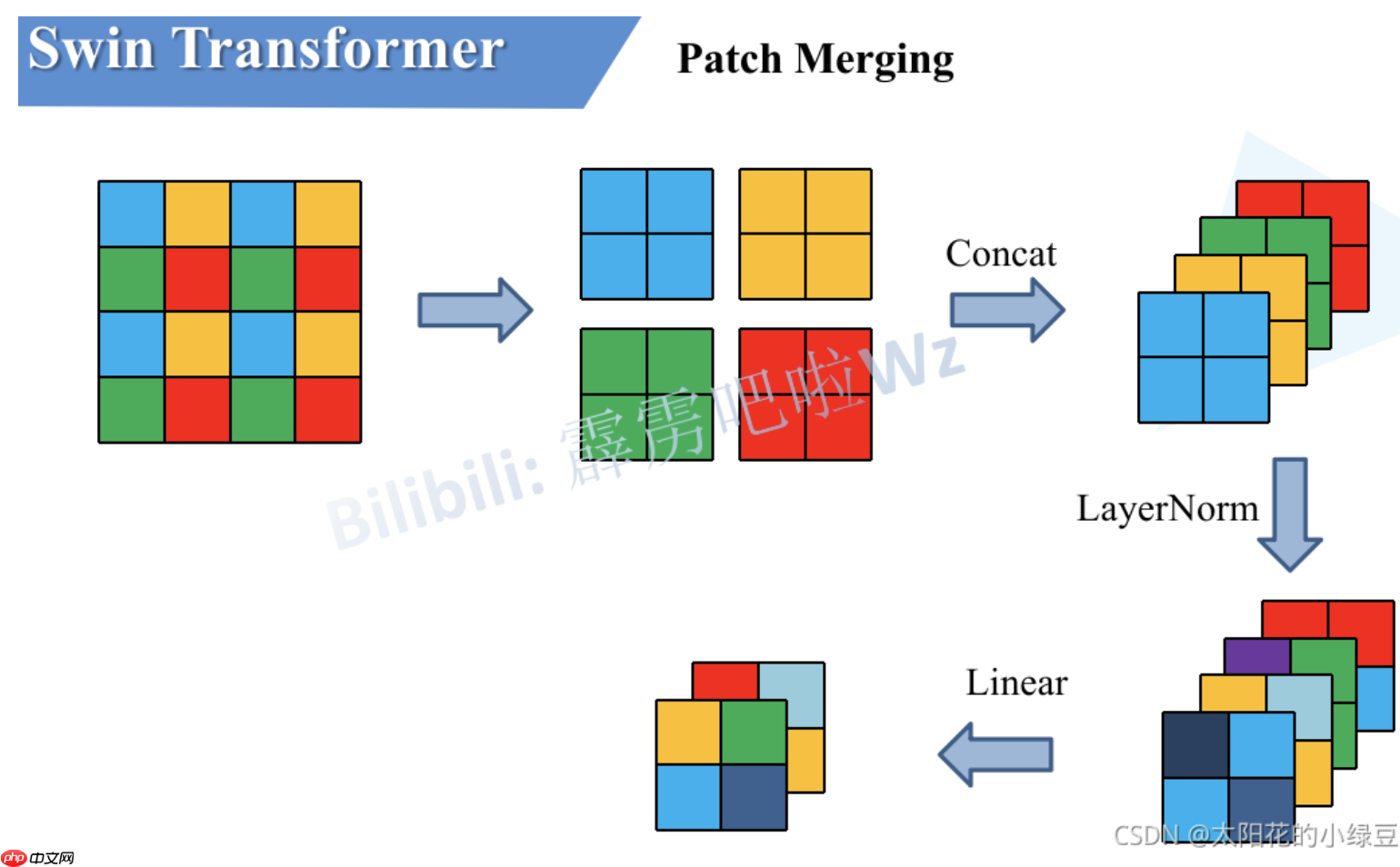
首先我们使用一个2×2大小的卷积核作为窗口,每个窗口都有四个像素,那么我就就把每个窗口相同位置的像素取出,并得到如第二个一样的四个特征矩阵,之后会对这四个特征矩阵在C纬度进行拼接也就得到了4xC,之后再进行一个LinearNorm层,最后通过一个Linear层进行一个线性映射变为2xC。这样 X的shape就变成了
[H/4,W/4,C]->[H/8,W/8,2*C]
In [4]
class PatchMerging(nn.Layer): r""" Patch Merging Layer. Args: dim (int): Number of input channels. norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm """ def __init__(self, dim, norm_layer=nn.LayerNorm): super().__init__() self.dim = dim self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False) self.norm = norm_layer(4 * dim) def forward(self, x, H=224//4, W=224//4): """ x: B, H*W, C """ B, L, C = x.shape print(x.shape) assert L == H * W, "input feature has wrong size" x = paddle.reshape(x,(B, H, W, C)) # # padding # # 如果输入feature map的H,W不是2的整数倍,需要进行padding # pad_input = (H % 2 == 1) or (W % 2 == 1) # if pad_input: # # to pad the last 3 dimensions, starting from the last dimension and moving forward. # # (C_front, C_back, W_left, W_right, H_top, H_bottom) # # 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同 # x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2)) x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C] x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C] x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C] x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C] x = paddle.concat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C] x = paddle.reshape(x,(B, -1, 4 * C)) # [B, H/2*W/2, 4*C] x = self.norm(x) x = self.reduction(x) # [B, H/2*W/2, 2*C] print(x.shape) return x
In [5]
model = PatchMerging(96)paddle.summary(model,(8,3136,96))
[8, 3136, 96][8, 784, 192]--------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # =========================================================================== LayerNorm-2 [[8, 784, 384]] [8, 784, 384] 768 Linear-1 [[8, 784, 384]] [8, 784, 192] 73,728 ===========================================================================Total params: 74,496Trainable params: 74,496Non-trainable params: 0---------------------------------------------------------------------------Input size (MB): 9.19Forward/backward pass size (MB): 27.56Params size (MB): 0.28Estimated Total Size (MB): 37.03---------------------------------------------------------------------------
{'total_params': 74496, 'trainable_params': 74496}
Swin TansFormer Block 讲解
与VIT TransFormer的Block层相似,Swin TransFormer与之不同的就是使用了S-MSA与SW-MSA来代替MSA,其他都没有改变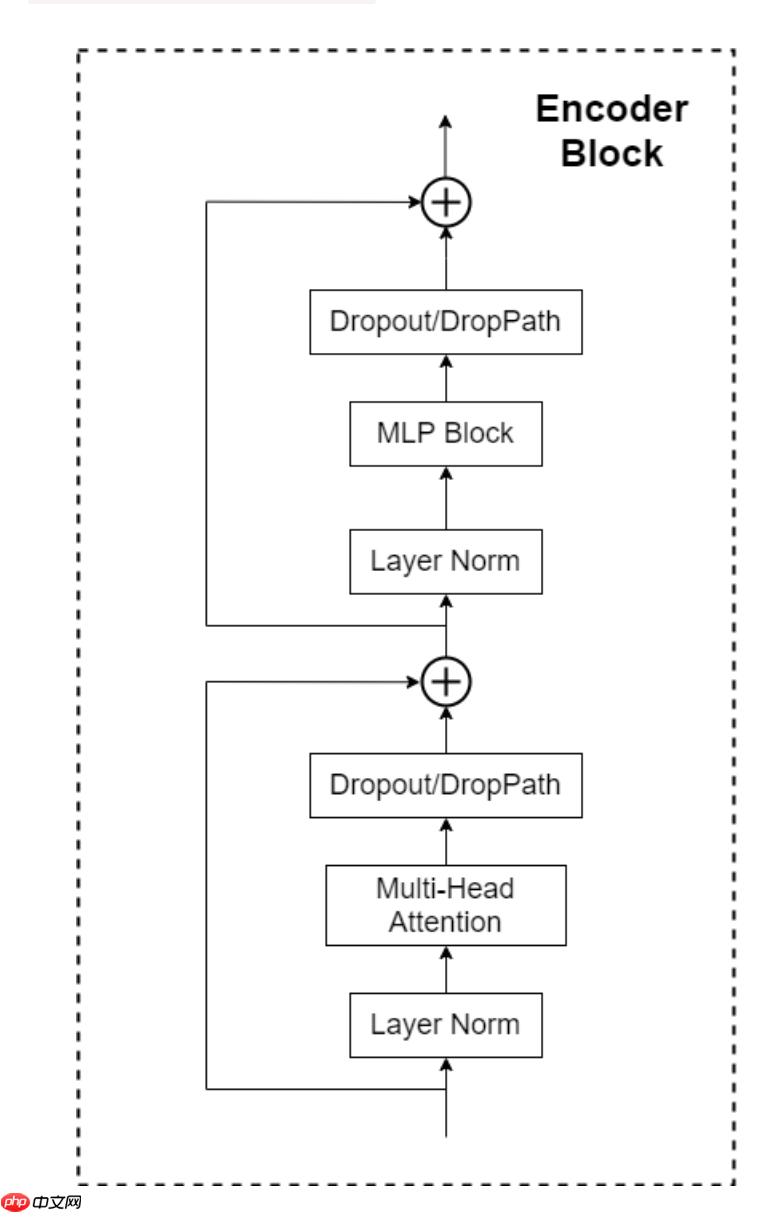
S-SMA与SW-MSA暂时有点难,咱们分到明天再去进行讲解,今天咱们先把整个Block模块进行实现
可以看到Block层是先经过一个LayerNorm然后经过S-MSA或者SW-MSA然后在进过一个Dropout或者是DropPath层,然后进行一个短接,然后再进行一个LayerNrom之后再进行一个Mlp再接一个Dropout或者是DropPath层,然后再来一个短接,这样一个Block层就实现了。
下面我先先来实现之前已经讲过Mlp层。
Mlp讲解
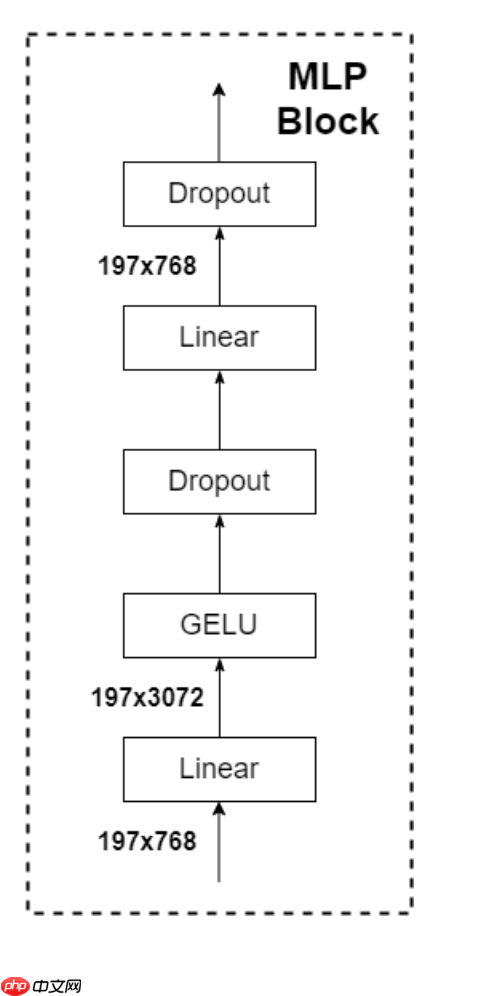
Mlp之前朱老师已经讲的很清楚了就是一个Linear层将通道数×4,然后经过GELU激活函数,然后再经过一个Dropout层再经过一个Linear层将通道数变回到原来的通道数,之后再接一个Dropout层
In [6]
class Mlp(nn.Layer): """ MLP as used in Vision Transformer, MLP-Mixer and related networks """ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.drop1 = nn.Dropout(drop) self.fc2 = nn.Linear(hidden_features, out_features) self.drop2 = nn.Dropout(drop) def forward(self, x): print(x.shape) x = self.fc1(x) x = self.act(x) x = self.drop1(x) x = self.fc2(x) x = self.drop2(x) print(x.shape) return x
In [7]
model = Mlp(768)paddle.summary(model,(8,197,768))
[8, 197, 768][8, 197, 768]--------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # =========================================================================== Linear-2 [[8, 197, 768]] [8, 197, 768] 590,592 GELU-1 [[8, 197, 768]] [8, 197, 768] 0 Dropout-1 [[8, 197, 768]] [8, 197, 768] 0 Linear-3 [[8, 197, 768]] [8, 197, 768] 590,592 Dropout-2 [[8, 197, 768]] [8, 197, 768] 0 ===========================================================================Total params: 1,181,184Trainable params: 1,181,184Non-trainable params: 0---------------------------------------------------------------------------Input size (MB): 4.62Forward/backward pass size (MB): 46.17Params size (MB): 4.51Estimated Total Size (MB): 55.29---------------------------------------------------------------------------
{'total_params': 1181184, 'trainable_params': 1181184}
SwinTransformerBlock层实现
下面就是Block层的实现,这里有一个WindowAttention就是S-MSA与SW-MSA的实现,这里就先简单定义一下,没有任何内容。
In [8]
class WindowAttention(nn.Layer): def __init__(self,dim, window_size, num_heads, qkv_bias,attn_drop, proj_drop): super().__init__() pass def forward(self,x): return x,x
In [9]
class SwinTransformerBlock(nn.Layer): """ Swin Transformer Block. dim (int): Number of input channels. num_heads (int): Number of attention heads. window_size (int): Window size. shift_size (int): Shift size for SW-MSA. mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True drop (float, optional): Dropout rate. Default: 0.0 attn_drop (float, optional): Attention dropout rate. Default: 0.0 drop_path (float, optional): Stochastic depth rate. Default: 0.0 act_layer (nn.Module, optional): Activation layer. Default: nn.GELU norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm """ def __init__(self, dim, num_heads, window_size=7, shift_size=0, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm): super().__init__() self.dim = dim self.num_heads = num_heads self.window_size = window_size self.shift_size = shift_size self.mlp_ratio = mlp_ratio assert 0 <= self.shift_size 0. else nn.Identity() self.norm2 = norm_layer(dim) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) def forward(self, x): H, W = 56, 56 B, L, C = x.shape assert L == H * W, "input feature has wrong size" shortcut = x x = self.norm1(x) x = paddle.reshape(x,(B, H, W, C)) # # pad feature maps to multiples of window size # # 把feature map给pad到window size的整数倍 # pad_l = pad_t = 0 # pad_r = (self.window_size - W % self.window_size) % self.window_size # pad_b = (self.window_size - H % self.window_size) % self.window_size # x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b)) _, Hp, Wp, _ = x.shape#--------------------------------------------------------------------------------------------------## S-MSA暂不处理,下次再说#--------------------------------------------------------------------------------------------------# # # cyclic shift # if self.shift_size > 0: # shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) # else: # shifted_x = x # attn_mask = None # # partition windows # x_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C] # x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C] # # W-MSA/SW-MSA # attn_windows = self.attn(x_windows, mask=attn_mask) # [nW*B, Mh*Mw, C] # # merge windows # attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C] # shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C] # # reverse cyclic shift # if self.shift_size > 0: # x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2)) # else: # x = shifted_x # if pad_r > 0 or pad_b > 0: # # 把前面pad的数据移除掉 # x = x[:, :H, :W, :].contiguous()#--------------------------------------------------------------------------------------------------# x = paddle.reshape(x,(B,H*W,C)) x = shortcut + self.drop_path(x) x = x + self.drop_path(self.mlp(self.norm2(x))) return x
In [10]
model = SwinTransformerBlock(96,3)paddle.summary(model,(8,3136,96))
[8, 3136, 96][8, 3136, 96]--------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # =========================================================================== LayerNorm-3 [[8, 3136, 96]] [8, 3136, 96] 192 Dropout-3 [[8, 3136, 96]] [8, 3136, 96] 0 LayerNorm-4 [[8, 3136, 96]] [8, 3136, 96] 192 Linear-4 [[8, 3136, 96]] [8, 3136, 384] 37,248 GELU-2 [[8, 3136, 384]] [8, 3136, 384] 0 Dropout-4 [[8, 3136, 384]] [8, 3136, 384] 0 Linear-5 [[8, 3136, 384]] [8, 3136, 96] 36,960 Dropout-5 [[8, 3136, 96]] [8, 3136, 96] 0 Mlp-2 [[8, 3136, 96]] [8, 3136, 96] 0 ===========================================================================Total params: 74,592Trainable params: 74,592Non-trainable params: 0---------------------------------------------------------------------------Input size (MB): 9.19Forward/backward pass size (MB): 330.75Params size (MB): 0.28Estimated Total Size (MB): 340.22---------------------------------------------------------------------------
{'total_params': 74592, 'trainable_params': 74592}
以上就是屠榜CV!Swin TransFromer 你又该换Backbone了!的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/39979.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫