
本文围绕声呐图像识别展开,指出现有侧扫声呐人工识别耗时且易误判的问题,介绍用PaddleDetection处理数据集(修改源码适配VOC格式、转换前视声呐数据为COCO格式),并改进YOLO模型(结合PPYOLOV2与YOLO-X解耦头,ResNet加入注意力机制),以提升检测速度与精度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

正文
背景
或许你会对海底拥有美好的幻想,你所幻想的海底或者在电视看到的海底可能是这样的

但是非常抱歉我可能要打破你的幻想了,这种样子的海底只是存在太阳光能照见的地方,如果是太阳光无法照到的地方可能也就是一片黑吧。那么有没有什么能有效探测海底或深海的设备呢,那么这需要声呐设备设备上线了
声呐是英文缩写“SONAR”的音译,其中文全称为:声音导航与测距,Sound Navigation And Ranging”是一种利用声波在水下的传播特性,通过电声转换和信息处理,完成水下探测和通讯任务的电子设备。它有主动式和被动式两种类型,属于声学定位的范畴。声呐是利用水中声波对水下目标进行探测、定位和通信的电子设备,是水声学中应用最广泛、最重要的一种装置。
而声呐中最常见的就是侧扫声纳和前视声呐,下面分别是侧扫声呐与前视声呐图像。


侧扫声呐在探索似雷物体,海底样貌,沉船打捞,失事飞机的搜寻等方面的探测和识别方面具有重要的应用价值,目前传统的搜寻方法是使用侧扫声纳对目标海域进行大规模的扫描,待将所有的区域扫描完成后,再由人工进行区域图像识别,此种方式造成了大量的时间浪费,同时由于人工判读的情况,不可避免的会造成误判错判,如何提高声呐识别的检测速度与检测精度就成为了改进的工作点。
那么这个时候就要请到深度学习目标检测模型来帮助人工进行识别了,但是有一个问题是我们该选择什么工具来进行训练和部署呢?
这里我们就用到了PaddleDetection
PaddleDetection为基于飞桨PaddlePaddle的端到端目标检测套件,提供多种主流目标检测、实例分割、跟踪、关键点检测算法,配置化的网络模块组件、数据增强策略、损失函数等,推出多种服务器端和移动端工业级SOTA模型,并集成了模型压缩和跨平台高性能部署能力,帮助开发者更快更好完成端到端全开发流程。
数据集介绍
侧扫声呐数据集
大家已经看过了侧扫和前视声呐的图像,但是相比较已经很离谱的图像,更加离谱的是他们的数据集
下面我们先看一下正常的 VOC 数据集
VOC2007 test100.mp4_3380.jpeg 1280 720 3 0
下面是侧扫声呐的数据集
flv13
相比较正常的 VOC标注格式可以看到侧扫声呐的数据集标注像 VOC 但又不像 VOC 因为 PaddleDetection 只能接收标准的 VOC 格式,同时标注文件给的所有的 size 与照片的真实 size 是不同的,所以我对 PaddleDetection的读取 VOC 标注文件的源码进行了修改
首先是解决 读取 size 不正常的问题,当size 不一致时便会发出 warning,1到2个还好但是多了就就无法正常工作了,因此我们直接把下段代码更改为
if 'h' not in sample: sample['h'] = im.shape[0] elif sample['h'] != im.shape[0]: logger.warning( "The actual image height: {} is not equal to the " "height: {} in annotation, and update sample['h'] by actual " "image height.".format(im.shape[0], sample['h'])) sample['h'] = im.shape[0]
sample['h'] = im.shape[0]
上面是 h 的处理 w 的处理也是同理
而标注格式与 VOC 不同问题就是在 ppdet/data/sources/voc.py 进行修改
前视声呐
这就是前视声呐数据集的标注格式,跟着侧扫声呐数据集的标注格式一样的『清新脱俗』,但还好,因为前视声呐的目标较难识别,所以直接用 VOC 评价格式稍微修改一下 PaddleDetection 的源码就可以了。但是前视声呐不同,因为前视声呐识别率过高因此采用 COCO评价指标,那么就需要把前视声呐的标注格式给改成 COCO 格式的。
Tritech 1200ik 1 15.0003 120 20 1474.3 720k log_2021-03-15-104935annotaion log_2021-03-15-104935_annotaion_14.xml /Users/kim_shally/Desktop/sonar_annotation/20210315/Ball_SquareCage_Tyre/log_2021-03-15-104935_annotaion/log_2021-03-15-104935_annotaion_14.bmp 512 1840 3
但是问题就来了。我试了一下 PaddleDetection 自带的但是完全不能用,因此在 github 上我找到了一个 voc2coco 的项目,用他的文件做了修改才把前视声呐的标注数据改成了 COCO 数据集格式。
源码
#!/usr/bin/python# pip install lxmlimport sysimport osimport jsonimport xml.etree.ElementTree as ETimport globSTART_BOUNDING_BOX_ID = 1PRE_DEFINE_CATEGORIES = None# If necessary, pre-define category and its id# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,# "motorbike": 14, "person": 15, "pottedplant": 16,# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}def get(root, name): vars = root.findall(name) return varsdef get_and_check(root, name, length): vars = root.findall(name) if len(vars) == 0: raise ValueError("Can not find %s in %s." % (name, root.tag)) if length > 0 and len(vars) != length: raise ValueError( "The size of %s is supposed to be %d, but is %d." % (name, length, len(vars)) ) if length == 1: vars = vars[0] return varsdef get_filename_as_int(filename): try: filename = filename.replace("", "/") filename = os.path.splitext(os.path.basename(filename))[0] return int(filename) except: raise ValueError("Filename %s is supposed to be an integer." % (filename))def get_categories(xml_files): """Generate category name to id mapping from a list of xml files. Arguments: xml_files {list} -- A list of xml file paths. Returns: dict -- category name to id mapping. """ classes_names = [] for xml_file in xml_files: tree = ET.parse(xml_file) root = tree.getroot() for member in root.findall("object"): classes_names.append(member[0].text) classes_names = list(set(classes_names)) classes_names.sort() return {name: i for i, name in enumerate(classes_names)}def convert(xml_files, json_file): json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []} if PRE_DEFINE_CATEGORIES is not None: categories = PRE_DEFINE_CATEGORIES else: categories = get_categories(xml_files) bnd_id = START_BOUNDING_BOX_ID for xml_file in xml_files: tree = ET.parse(xml_file) root = tree.getroot() path = get(root, "path") if len(path) == 1: filename = os.path.basename(path[0].text) elif len(path) == 0: filename = get_and_check(root, "filename", 1).text else: raise ValueError("%d paths found in %s" % (len(path), xml_file)) ## The filename must be a number image_id = get_filename_as_int(filename) size = get_and_check(root, "size", 1) width = int(get_and_check(size, "width", 1).text) height = int(get_and_check(size, "height", 1).text) image = { "file_name": filename, "height": height, "width": width, "id": image_id, } json_dict["images"].append(image) ## Currently we do not support segmentation. # segmented = get_and_check(root, 'segmented', 1).text # assert segmented == '0' for obj in get(root, "object"): category = get_and_check(obj, "name", 1).text if category not in categories: new_id = len(categories) categories[category] = new_id category_id = categories[category] bndbox = get_and_check(obj, "bndbox", 1) xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1 ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1 xmax = int(get_and_check(bndbox, "xmax", 1).text) ymax = int(get_and_check(bndbox, "ymax", 1).text) assert xmax > xmin assert ymax > ymin o_width = abs(xmax - xmin) o_height = abs(ymax - ymin) ann = { "area": o_width * o_height, "iscrowd": 0, "image_id": image_id, "bbox": [xmin, ymin, o_width, o_height], "category_id": category_id, "id": bnd_id, "ignore": 0, "segmentation": [], } json_dict["annotations"].append(ann) bnd_id = bnd_id + 1 for cate, cid in categories.items(): cat = {"supercategory": "none", "id": cid, "name": cate} json_dict["categories"].append(cat) os.makedirs(os.path.dirname(json_file), exist_ok=True) json_fp = open(json_file, "w") json_str = json.dumps(json_dict) json_fp.write(json_str) json_fp.close()if __name__ == "__main__": import argparse parser = argparse.ArgumentParser( description="Convert Pascal VOC annotation to COCO format." ) parser.add_argument("xml_dir", help="Directory path to xml files.", type=str) parser.add_argument("json_file", help="Output COCO format json file.", type=str) args = parser.parse_args() xml_files = glob.glob(os.path.join(args.xml_dir, "*.xml")) # If you want to do train/test split, you can pass a subset of xml files to convert function. print("Number of xml files: {}".format(len(xml_files))) convert(xml_files, args.json_file) print("Success: {}".format(args.json_file))
…..这里非常抱歉。我当时修改完就给删了。。只能找到未修改的源码了。
这里给出转换的 github 项目的链接 https://github.com/Tony607/voc2coco
训练部分
正如同YOLO系列的全程“You can only look once”,YOLO在不断提升目标检测精度的同时,一贯保持着检测速度快的特性。但由于YOLO系列原作者Joe Redmon由于种种原因决定停止YOLO系列的改进,至此YOLO系列产生出两种不同的改进策略,一类是由Alexey Bochkovskiy为第一作者的YOLOV4(Joe Redmon未参与其中),YOLOV5,以及最新的由Caleb Ge所推出的YOLO-X系列;另一类是由百度飞桨推出的PPYOLO,以及最新的PPYOLOV2系列。
YOLO数字系列,一直并未对YOLO系列的整体框架做出较大改变。而最新的YOLO-X着重与于将YOLO-Head进行更改,由于YOLO系列需要通过聚类方法设置先验框,适用性较差,因此YOLO-X通过Acnhor-Free算法来不再设定先验框这样对于适用性较差的问题也就迎刃热解,并且通过解耦头的方式,将原来YOLO系列通过一个3X3卷积来同时预测位置调整参数、是否包含物体参数、以及物体类别参数,改为通过三个卷积来分别预测位置调整参数、是否包含物体参数、以及物体类别参数,通过解耦头的方式能有效的提高检测精度,同时由于使用的anchor-free算法原先需要预测3个先验框的数据现在只需要预测一个先验框的数据,从而一定程度上将少参数量,提高了检测速度。
PPYOLO系列则是通过更换特征提取网络同时增加合理的trick进行改进。最新的PPYOLOV使用更大的训练Batch size :8GPU ,每个GPU batch size=24,并对应调整学习略和迭代轮数,同时引入Drop Block、Exponential Moving Average技术、在Loss方面使用IoU Loss、并在NMS方面采用Matrix NMS。同时加入IoU aware loss甚至将Backbone又原本的DarkNet53换为适用范围更广,性能更优的ResNet50-DCN加入可变性卷积,,以及教师学习模型(SSLD)等一系列合理的Trick,在COCO数据集上达到了val达到49.7%,test达到50.3%并且检测速度达到49.5FPS!
改进策略
由于YOLO主要分为 Backbone,PAN,HEAD三层,因此我们选择将以PPYOLOV2为蓝本,将ResNet进一步改进,同时将PPYOLOV2的HEAD层借鉴YOLO-X的解耦头方式进行改进,由于PAN部分目前业界也并未有太多能够提升目标检测准确度的同时能保证不降低检测速度的trick因此我们并未做出改进!
Backbone 的改进
神经网络由原本的全连接层发展到卷积网络,以及最新的图神经网络,但由于目前图神经网络并未在CV方向展现出优越与卷积网络的领域,因此,目前CV仍是以堆叠大量卷积网络进行特征提取,但如同人的视觉一样,当人的瞳孔聚焦与当前画面时,更多的是去聚焦我们所感兴趣的区域,其他区域会适当性的舍弃。由此有人思考神经网络能否想人一样去思考事物呢,借鉴于此注意力机制(Self Attention)由此诞生,Attention机制最早是在视觉图像领域提出来的,在九几年思想就以被提出,但由于历史相关因素并未在被提出之后就被广泛应用,反而是在近几年NLP方向使用Attention技术解决了一大批技术难题,真正在CV方向的火爆是由今年的《Vision Transformer》引起了CV方向的注意力网络大火,并且有微软提出的SWIN-Transformer更是获得了ICCV的最佳论文奖。因此我们决定将ResNet与注意力机制相结合,打造由于ResNet50-DCN的Backbone,先前我们使用swin-transformer进行先期验证,如把Backbone全面替换为注意力机制效果反而不如ResNet,这是因为注意力机制需要通过不断的叠加增加网络深度和参数量才能更好的进行特征提取,我们所选用的swin-tiny由于层数限制导致效果反而不如ResNet,但如果想采用更深的网络,则会导致参数增多,检测速度大幅下降,我们认为得不偿失,因此最后选择在ResNet网络中部分添加注意力机制,这样在不大幅影响检测速度的同时还能更好的提取特征。最终我们选择了由谷歌实验室推出的BottleNeck Transformer结构,并将其应用于ResNet50的Layer5层中。
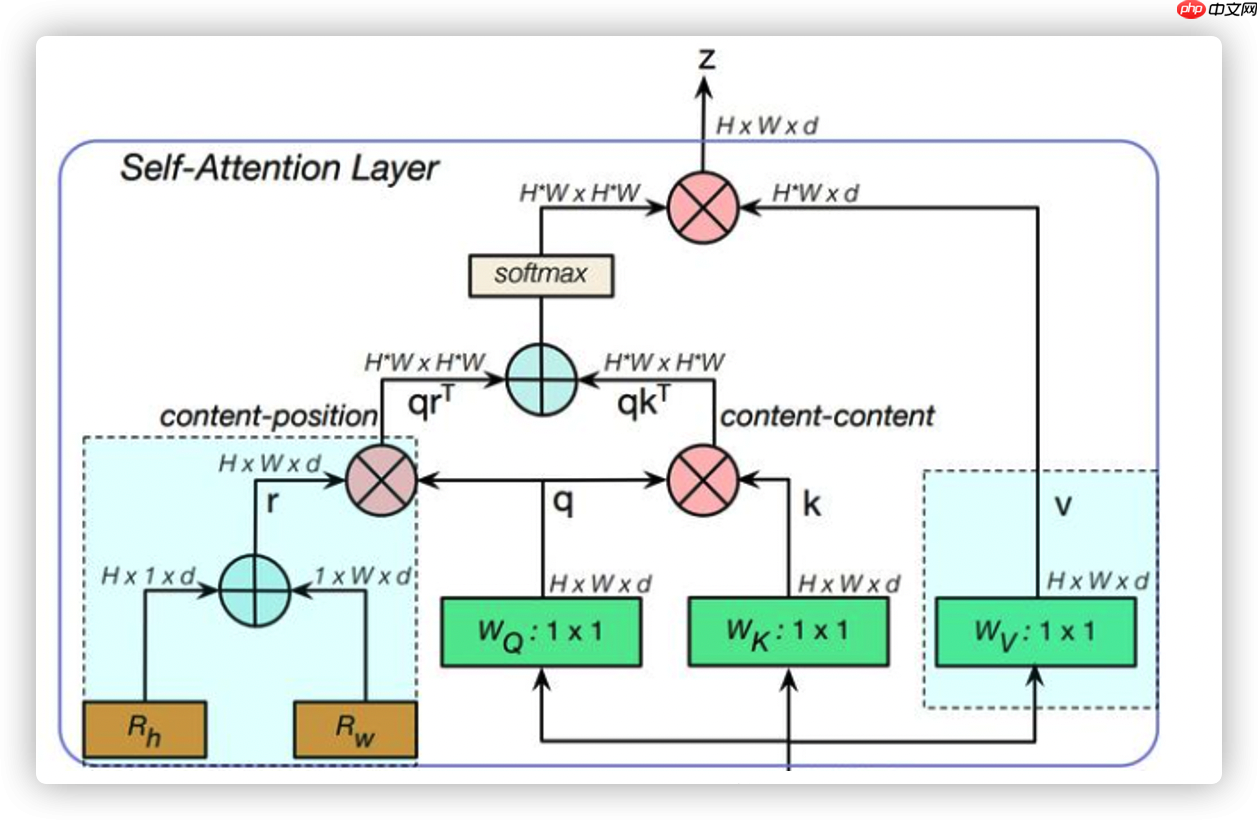
CNN由于卷积核大小限制只能提取部分特征而不能很好的提取到全局的特征,更多的是对局部信息的关注,而Self-Attention使得网络能够获取图像全局特征的能力。谷歌实验室将BottleNeck Transformer结构应用于ResNet50的Layer5层中,首先通过CNN来获取局部信息并通过网络的重叠使得感受野更大,提取的特征更为广泛,最后通过注意力机制感知全局,这是一种局部与全局的结合,是我们认为目前在兼顾速度与精度的有效解决方案。
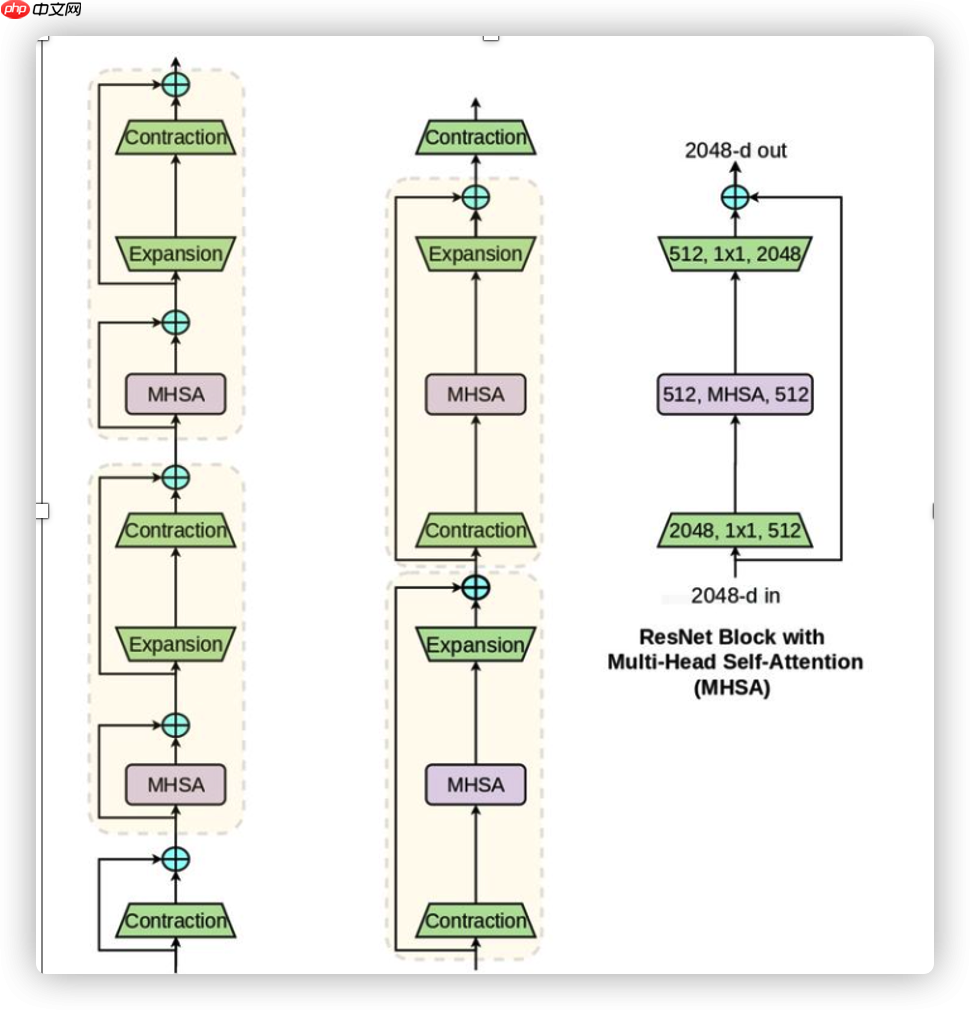
上图为三种对比左边是目前较为传统的Transformer,中间是此次改进的BottleNeck Transformer,右图是将BottleNeck Transformer加入到ResNet中形成的BoT Block层。值得注意的是传统的Transformer模型中normalization层用的是layer normalization,而BoTNet中用的是batch normalization。并且相较于传统的Transformer BottleNeck Transformer使用了三个非线性激活。
由于self-attention需要计算空间纬度上的二次方需要大量的内存和显存,当使用高分辨率的图片进行训练时这个问题尤为突出。但BoTNet对这个问题做出了自己的解答,首先利用卷积来对图像进行特征提取,当通过足够深度的卷积网络提取后获得有效的feature map,之后再进行self-attention操作。
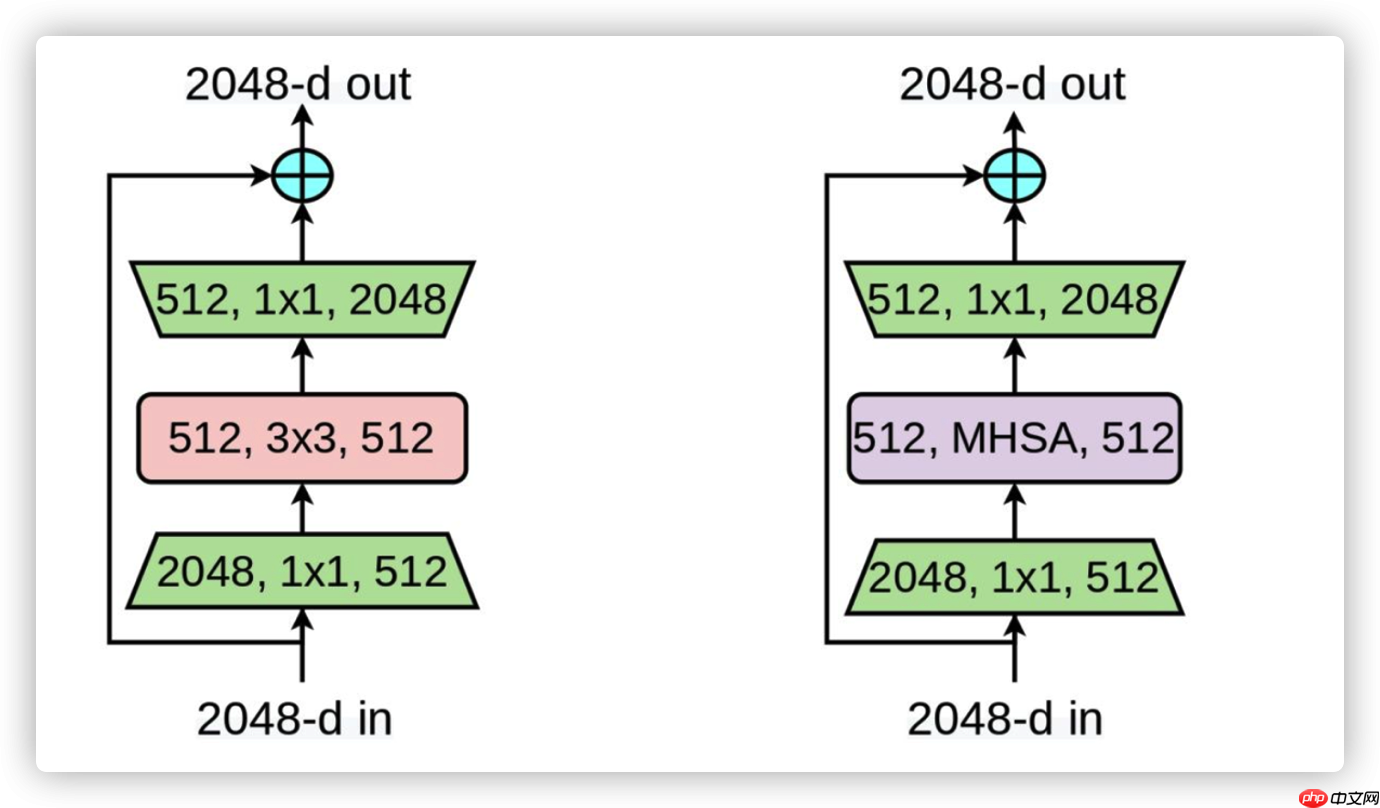
相较于做图中ResNet的Block网络,BotNet仅仅是将Layer5中的3个NormalyBlock中的3X3卷积更换为MHSA网络。
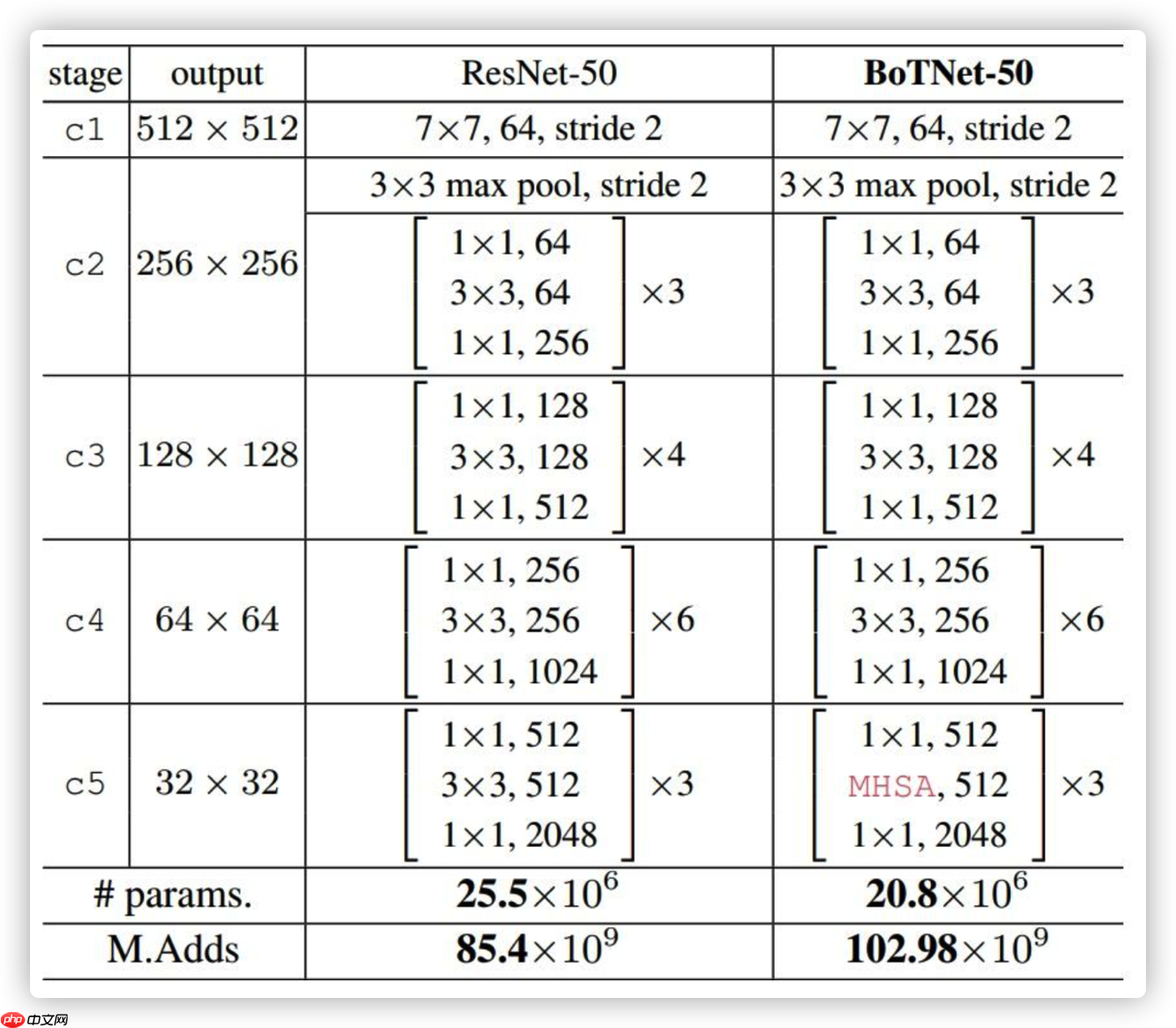
下图为ResNet-50和BoTNet-50的区别,唯一的不同在c5。而且BoTNe-50t的参数量只有ResNet-50的0.82倍,但是steptime略有增加。最终在ImageNet上高达84.7%的top-1精度,性能优于SENet、EfficientNet,并在目标检测等领域长点明显。
最终我们选择在BotNet的最后加入可变性卷积,卷积核存在的最大问题就是,对于未知的变化适应性差,泛化能力不强,但可变性卷积可以根据实际情况调整本身的形状,更好的提取输入的特征。
YOLO HEAD改进
yolov3中,YOLO HEAD首先会通过一个1X1的卷积来调整通道数量,然后使用3X3的卷积产生3X(1+4+Classes)个通道,这是因为每个YOLO HEAD需要负责预测三个Anchor的目标置信度也就是1,位置调整参数对应的就是4,以及各类别置信度也就是Classes,Classes取决于所要检测目标的数量,例如COCO数据集为80类YOLO HEAD就需要产生3X(1+4+80)通道。
而YOLO-X通过预测分支解耦的形式首先依旧是通过一个1X1的卷积调整通道数之后产生两个分支,两边都使用3X3的卷积,一边是预测目标种类置信度,另一边再分为两个分支,一个负责预测位置信息,另一边预测IoU。同时由于YOLO-X使用Anchor-Free算法,从原有一个特征图预测3组anchor减少成只预测1组。
我们将PPYOLOV2的YOLO HEAD借鉴于YOLO-X的预测分支解耦,但我们并未选择使用YOLO-X的Anchor Free算法,这是因为在使用Anchor Free算法之后,特征图的尺寸选择与选取策略也是一个问题,这是需要通过大量试验来进行确定的,而这就需要一些判断形式,会图增加推理时间,因此我们并未借鉴。
PPYOLOV2的YOLOHEAD是通过3X3卷积产生3X(1+4+1+Classes)个通道,多出来的一个1是用于计算IoU Aware Loss并更平滑的处理预测信息。因此我们选择在预测分支解耦的下端再分出一组用来与PPYOLOV2相贴合。
BotNet 第一版源码
In [ ]
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License.import mathfrom numbers import Integralimport paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom ppdet.core.workspace import register, serializablefrom paddle.regularizer import L2Decayfrom paddle.nn.initializer import Uniformfrom paddle import ParamAttrfrom paddle.nn.initializer import Constantfrom paddle.vision.ops import DeformConv2Dfrom .name_adapter import NameAdapterfrom ..shape_spec import ShapeSpecimport numpy as np# from paddle.nn import Conv2D, MaxPool2D, BatchNorm, Linearfrom paddle.nn import Conv2D, MaxPool2D, BatchNorm2D, Linear ,ReLUfrom einops import rearrange__all__ = ['ResNet', 'Res5Head', 'Blocks', 'BasicBlock', 'BottleNeck']ResNet_cfg = { 18: [2, 2, 2, 2], 34: [3, 4, 6, 3], 50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3],}def get_n_params(model): pp=0 for p in list(model.parameters()): nn=1 for s in list(p.size()): nn = nn*s pp += nn return ppclass MHSA(paddle.nn.Layer): def __init__(self, n_dims, width=38, height=38, heads=4): super(MHSA, self).__init__() self.heads = heads self.query = Conv2D(512, 512, kernel_size=1) self.key = Conv2D(512, 512, kernel_size=1) self.value = Conv2D(n_dims, n_dims, kernel_size=1) self.create_parameter([1,1]) self.rel_h = self.create_parameter(shape=[1,heads,n_dims // heads,1,height],default_initializer=paddle.nn.initializer.Normal(std=1e-4),dtype='float32') #[1,4,128,1,38] self.add_parameter('rel_h',self.rel_h) self.rel_w = self.create_parameter(shape=[1, heads, n_dims // heads, width, 1],default_initializer=paddle.nn.initializer.Normal(std=1e-4),dtype='float32')# [1,4,128,38,1] self.add_parameter('rel_w',self.rel_w) def forward(self, x): n_batch, C, width, height = x.shape q = self.query(x).reshape([n_batch, self.heads, C // self.heads, -1])#(1,4,128,1444) k = self.key(x).reshape([n_batch, self.heads, C // self.heads, -1])#(1 ,4 ,128 ,1444) v = self.value(x).reshape([n_batch, self.heads, C // self.heads, -1])#(1,4,128,1444) content_content = paddle.matmul(paddle.transpose(q,(0, 1, 3, 2)), k) # (1,4,1444,1444) content_position = paddle.transpose((self.rel_h + self.rel_w).reshape([1, self.heads, C // self.heads, -1]),[0, 1, 3, 2]) content_position = paddle.matmul(content_position, q) energy = content_content + content_position attention = paddle.nn.functional.softmax(energy) out = paddle.matmul(v, attention) out = paddle.reshape(out,[n_batch, C, width, height]) # [1,512,38,38] return outclass ConvNormLayer(nn.Layer): def __init__(self, ch_in, ch_out, filter_size, stride, groups=1, act=None, norm_type='bn', norm_decay=0., freeze_norm=True, lr=1.0, dcn_v2=False): super(ConvNormLayer, self).__init__() assert norm_type in ['bn', 'sync_bn'] self.norm_type = norm_type self.act = act self.dcn_v2 = dcn_v2 if not self.dcn_v2: self.conv = nn.Conv2D( in_channels=ch_in, out_channels=ch_out, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, groups=groups, weight_attr=ParamAttr(learning_rate=lr), bias_attr=False) else: self.offset_channel = 2 * filter_size**2 self.mask_channel = filter_size**2 self.conv_offset = nn.Conv2D( in_channels=ch_in, out_channels=3 * filter_size**2, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, weight_attr=ParamAttr(initializer=Constant(0.)), bias_attr=ParamAttr(initializer=Constant(0.))) self.conv = DeformConv2D( in_channels=ch_in, out_channels=ch_out, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, dilation=1, groups=groups, weight_attr=ParamAttr(learning_rate=lr), bias_attr=False) norm_lr = 0. if freeze_norm else lr param_attr = ParamAttr( learning_rate=norm_lr, regularizer=L2Decay(norm_decay), trainable=False if freeze_norm else True) bias_attr = ParamAttr( learning_rate=norm_lr, regularizer=L2Decay(norm_decay), trainable=False if freeze_norm else True) global_stats = True if freeze_norm else False if norm_type == 'sync_bn': self.norm = nn.SyncBatchNorm( ch_out, weight_attr=param_attr, bias_attr=bias_attr) else: self.norm = nn.BatchNorm( ch_out, act=None, param_attr=param_attr, bias_attr=bias_attr, use_global_stats=global_stats) norm_params = self.norm.parameters() if freeze_norm: for param in norm_params: param.stop_gradient = True def forward(self, inputs): if not self.dcn_v2: out = self.conv(inputs) else: offset_mask = self.conv_offset(inputs) offset, mask = paddle.split( offset_mask, num_or_sections=[self.offset_channel, self.mask_channel], axis=1) mask = F.sigmoid(mask) out = self.conv(inputs, offset, mask=mask) if self.norm_type in ['bn', 'sync_bn']: out = self.norm(out) if self.act: out = getattr(F, self.act)(out) return outclass SELayer(nn.Layer): def __init__(self, ch, reduction_ratio=16): super(SELayer, self).__init__() self.pool = nn.AdaptiveAvgPool2D(1) stdv = 1.0 / math.sqrt(ch) c_ = ch // reduction_ratio self.squeeze = nn.Linear( ch, c_, weight_attr=paddle.ParamAttr(initializer=Uniform(-stdv, stdv)), bias_attr=True) stdv = 1.0 / math.sqrt(c_) self.extract = nn.Linear( c_, ch, weight_attr=paddle.ParamAttr(initializer=Uniform(-stdv, stdv)), bias_attr=True) def forward(self, inputs): out = self.pool(inputs) out = paddle.squeeze(out, axis=[2, 3]) out = self.squeeze(out) out = F.relu(out) out = self.extract(out) out = F.sigmoid(out) out = paddle.unsqueeze(out, axis=[2, 3]) scale = out * inputs return scaleclass BasicBlock(nn.Layer): expansion = 1 def __init__(self, ch_in, ch_out, stride, shortcut, variant='b', groups=1, base_width=64, lr=1.0, norm_type='bn', norm_decay=0., freeze_norm=True, dcn_v2=False, std_senet=False): super(BasicBlock, self).__init__() assert dcn_v2 is False, "Not implemented yet." assert groups == 1 and base_width == 64, 'BasicBlock only supports groups=1 and base_width=64' self.shortcut = shortcut if not shortcut: if variant == 'd' and stride == 2: self.short = nn.Sequential() self.short.add_sublayer( 'pool', nn.AvgPool2D( kernel_size=2, stride=2, padding=0, ceil_mode=True)) self.short.add_sublayer( 'conv', ConvNormLayer( ch_in=ch_in, ch_out=ch_out, filter_size=1, stride=1, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr)) else: self.short = ConvNormLayer( ch_in=ch_in, ch_out=ch_out, filter_size=1, stride=stride, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.branch2a = ConvNormLayer( ch_in=ch_in, ch_out=ch_out, filter_size=3, stride=stride, act='relu', norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.branch2b = ConvNormLayer( ch_in=ch_out, ch_out=ch_out, filter_size=3, stride=1, act=None, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.std_senet = std_senet if self.std_senet: self.se = SELayer(ch_out) def forward(self, inputs): out = self.branch2a(inputs) out = self.branch2b(out) if self.std_senet: out = self.se(out) if self.shortcut: short = inputs else: short = self.short(inputs) out = paddle.add(x=out, y=short) out = F.relu(out) return outclass BottleNeck(nn.Layer): expansion = 4 def __init__(self, x, y, ch_in, # 1024 ch_out, #512 stride, # shortcut, variant='b', groups=1, base_width=4, lr=1.0, norm_type='bn', norm_decay=0., freeze_norm=True, dcn_v2=False, std_senet=False): super(BottleNeck, self).__init__() if variant == 'a': stride1, stride2 = stride, 1 else: stride1, stride2 = 1, stride # ResNeXt width = int(ch_out * (base_width / 64.)) * groups self.shortcut = shortcut if not shortcut: if variant == 'd' and stride == 2: self.short = nn.Sequential() self.short.add_sublayer( 'pool', nn.AvgPool2D( kernel_size=2, stride=2, padding=0, ceil_mode=True)) self.short.add_sublayer( 'conv', ConvNormLayer( ch_in=ch_in, ch_out=ch_out * self.expansion, filter_size=1, stride=1, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr)) else: self.short = ConvNormLayer( ch_in=ch_in, ch_out=ch_out * self.expansion, filter_size=1, stride=stride, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.branch2a = ConvNormLayer( ch_in=ch_in, ch_out=width, filter_size=1, stride=stride1, groups=1, act='relu', norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) if x and y: self.branch2b = paddle.nn.LayerList() self.branch2b.append(MHSA(512, width=int(48), height=int(48), heads=4)) self.branch2b.append(paddle.nn.AvgPool2D(2, 2)) self.branch2b = paddle.nn.Sequential(*self.branch2b) elif x and not y: self.branch2b = MHSA(512,width=24, height=24) else: self.branch2b = ConvNormLayer( ch_in=width, ch_out=width, filter_size=3, stride=stride2, groups=groups, act='relu', norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr, dcn_v2=dcn_v2) self.branch2c = ConvNormLayer( ch_in=width, ch_out=ch_out * self.expansion, filter_size=1, stride=1, groups=1, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.std_senet = std_senet if self.std_senet: self.se = SELayer(ch_out * self.expansion) def forward(self, inputs): out = self.branch2a(inputs) out = self.branch2b(out) out = self.branch2c(out) if self.std_senet: out = self.se(out) if self.shortcut: short = inputs else: short = self.short(inputs) out = paddle.add(x=out, y=short) out = F.relu(out) return outclass Blocks(nn.Layer): def __init__(self, block, x, ch_in, ch_out, count, name_adapter, stage_num, variant='b', groups=1, base_width=64, lr=1.0, norm_type='bn', norm_decay=0., freeze_norm=True, dcn_v2=False, std_senet=False): super(Blocks, self).__init__() self.blocks = [] for i in range(count): if i == 0: y = 1 else: y = 0 conv_name = name_adapter.fix_layer_warp_name(stage_num, count, i) layer = self.add_sublayer( conv_name, block( x, y, ch_in=ch_in, ch_out=ch_out, stride=2 if i == 0 and stage_num != 2 else 1, shortcut=False if i == 0 else True, variant=variant, groups=groups, base_width=base_width, lr=lr, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, dcn_v2=dcn_v2, std_senet=std_senet)) self.blocks.append(layer) if i == 0: ch_in = ch_out * block.expansion def forward(self, inputs): block_out = inputs for block in self.blocks: block_out = block(block_out) return block_out@register@serializableclass ResNet(nn.Layer): __shared__ = ['norm_type'] def __init__(self, depth=50, ch_in=64, variant='b', lr_mult_list=[1.0, 1.0, 1.0, 1.0], groups=1, base_width=64, norm_type='bn', norm_decay=0, freeze_norm=True, freeze_at=0, return_idx=[0, 1, 2, 3], dcn_v2_stages=[-1], # [3] num_stages=4, std_senet=False): """ Residual Network, see https://arxiv.org/abs/1512.03385 Args: depth (int): ResNet depth, should be 18, 34, 50, 101, 152. ch_in (int): output channel of first stage, default 64 variant (str): ResNet variant, supports 'a', 'b', 'c', 'd' currently lr_mult_list (list): learning rate ratio of different resnet stages(2,3,4,5), lower learning rate ratio is need for pretrained model got using distillation(default as [1.0, 1.0, 1.0, 1.0]). groups (int): group convolution cardinality base_width (int): base width of each group convolution norm_type (str): normalization type, 'bn', 'sync_bn' or 'affine_channel' norm_decay (float): weight decay for normalization layer weights freeze_norm (bool): freeze normalization layers freeze_at (int): freeze the backbone at which stage return_idx (list): index of the stages whose feature maps are returned dcn_v2_stages (list): index of stages who select deformable conv v2 num_stages (int): total num of stages std_senet (bool): whether use senet, default True """ super(ResNet, self).__init__() self._model_type = 'ResNet' if groups == 1 else 'ResNeXt' assert num_stages >= 1 and num_stages <= 4 self.depth = depth self.variant = variant self.groups = groups self.base_width = base_width self.norm_type = norm_type self.norm_decay = norm_decay self.freeze_norm = freeze_norm self.freeze_at = freeze_at if isinstance(return_idx, Integral): return_idx = [return_idx] assert max(return_idx) < num_stages, 'the maximum return index must smaller than num_stages, ' 'but received maximum return index is {} and num_stages ' 'is {}'.format(max(return_idx), num_stages) self.return_idx = return_idx self.num_stages = num_stages assert len(lr_mult_list) == 4, "lr_mult_list length must be 4 but got {}".format(len(lr_mult_list)) if isinstance(dcn_v2_stages, Integral): dcn_v2_stages = [dcn_v2_stages] assert max(dcn_v2_stages) < num_stages if isinstance(dcn_v2_stages, Integral): dcn_v2_stages = [dcn_v2_stages] assert max(dcn_v2_stages) = 50 else BasicBlock self._out_channels = [block.expansion * v for v in ch_out_list] self._out_strides = [4, 8, 16, 32] self.res_layers = [] for i in range(num_stages): if i == 3 : x = 1 else : x = 0 lr_mult = lr_mult_list[i] stage_num = i + 2 res_name = "res{}".format(stage_num) res_layer = self.add_sublayer( res_name, Blocks( block, x, self.ch_in, ch_out_list[i], count=block_nums[i], name_adapter=na, stage_num=stage_num, variant=variant, groups=groups, base_width=base_width, lr=lr_mult, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, dcn_v2=(i in self.dcn_v2_stages), std_senet=std_senet)) self.res_layers.append(res_layer) self.ch_in = self._out_channels[i] @property def out_shape(self): return [ ShapeSpec( channels=self._out_channels[i], stride=self._out_strides[i]) for i in self.return_idx ] def forward(self, inputs): x = inputs['image'] conv1 = self.conv1(x) x = F.max_pool2d(conv1, kernel_size=3, stride=2, padding=1) outs = [] for idx, stage in enumerate(self.res_layers): x = stage(x) if idx == self.freeze_at: x.stop_gradient = True if idx in self.return_idx: outs.append(x) return outs@registerclass Res5Head(nn.Layer): def __init__(self, depth=50): super(Res5Head, self).__init__() feat_in, feat_out = [1024, 512] if depth = 50 else BasicBlock self.res5 = Blocks( block, feat_in, feat_out, count=3, name_adapter=na, stage_num=5) self.feat_out = feat_out if depth < 50 else feat_out * 4 @property def out_shape(self): return [ShapeSpec( channels=self.feat_out, stride=16, )] def forward(self, roi_feat, stage=0): y = self.res5(roi_feat) return y
BotNet 第二版源码
In [ ]
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License.from cgitb import resetimport mathfrom numbers import Integralimport cv2import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom ppdet.core.workspace import register, serializablefrom paddle.regularizer import L2Decayfrom paddle.nn.initializer import Uniformfrom paddle import ParamAttrfrom paddle.nn.initializer import Constantfrom paddle.vision.ops import DeformConv2Dfrom .name_adapter import NameAdapterfrom ..shape_spec import ShapeSpecimport numpy as np# from paddle.nn import Conv2D, MaxPool2D, BatchNorm, Linearfrom paddle.nn import Conv2D, MaxPool2D, BatchNorm2D, Linear ,ReLUfrom einops import rearrange__all__ = ['BotNet', 'Bot5Head', 'Blocks', 'BasicBlock', 'BottleNeck']ResNet_cfg = { 18: [2, 2, 2, 2], 34: [3, 4, 6, 3], 50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3],}def expand_dim(t, dim, k): """ Expand dims for t at dim to k """ t = t.unsqueeze(axis=dim) expand_shape = [-1] * len(t.shape) expand_shape[dim] = k return paddle.expand(t, expand_shape)def rel_to_abs(x): """ x: [B, Nh * H, L, 2L - 1] Convert relative position between the key and query to their absolute position respectively. """ B, Nh, L, _ = x.shape # pad to shift from relative to absolute indexing col_pad = paddle.zeros([B, Nh, L, 1]) x = paddle.concat([x, col_pad], axis=3) flat_x = x.reshape([B, Nh, L * 2 * L]) flat_pad = paddle.zeros([B, Nh, L - 1]) flat_x = paddle.concat([flat_x, flat_pad], axis=2) # Reshape and slice out the padded elements final_x = flat_x.reshape([B, Nh, L + 1, 2 * L - 1]) return final_x[:, :, :L, L - 1 :]def relative_logits_1d(q, rel_k): """ q: [B, Nh, H, W, d] rel_k: [2W - 1, d] Computes relative logits along one dimension. """ B, Nh, H, W, _ = q.shape rel_logits = paddle.matmul(q, rel_k.transpose((1,0))) # Collapse height and heads rel_logits = rel_logits.reshape([-1, Nh * H, W, 2 * W - 1]) rel_logits = rel_to_abs(rel_logits) rel_logits = rel_logits.reshape([-1, Nh, H, W, W]) rel_logits = expand_dim(rel_logits, dim=3, k=H) return rel_logitsclass RelPosEmb(nn.Layer): '''Relative position encoding''' def __init__(self, height, width, dim_head): super().__init__() scale = dim_head ** -0.5 self.height = height self.width = width h_shape = [height * 2 - 1, dim_head] w_shape = [width * 2 - 1, dim_head] self.rel_height = paddle.create_parameter( shape=h_shape, dtype='float32', default_initializer=paddle.nn.initializer.Assign(paddle.randn(h_shape)*scale) ) self.rel_width = paddle.create_parameter( shape=w_shape, dtype='float32', default_initializer=paddle.nn.initializer.Assign(paddle.randn(w_shape)*scale) ) def forward(self, q): H = self.height W = self.width B, N, _, D = q.shape q = q.reshape([B, N, H, W, D]) # "B N (H W) D -> B N H W D" rel_logits_w = relative_logits_1d(q, self.rel_width) rel_logits_w = rel_logits_w.transpose(perm=[0, 1, 2, 4, 3, 5]) B, N, X, I, Y, J = rel_logits_w.shape rel_logits_w = rel_logits_w.reshape([B, N, X*Y, I*J]) # "B N X I Y J-> B N (X Y) (I J)" q = q.transpose(perm=[0, 1, 3, 2, 4]) # "B N H W D -> B N W H D" rel_logits_h = relative_logits_1d(q, self.rel_height) rel_logits_h = rel_logits_h.transpose(perm=[0, 1, 4, 2, 5, 3]) B, N, X, I, Y, J = rel_logits_h.shape rel_logits_h = rel_logits_h.reshape([B, N, Y*X, J*I]) # "B N X I Y J -> B N (Y X) (J I)" return rel_logits_w + rel_logits_hclass MHSA(nn.Layer): '''Multi-Head Self-Attention''' def __init__(self, dim, fmap_size, heads=4, dim_qk=128, dim_v=128): """ dim: number of channels of feature map fmap_size: [H, W] dim_qk: vector dimension for q, k dim_v: vector dimension for v (not necessarily the same with q, k) """ super().__init__() self.scale = dim_qk ** -0.5 self.heads = heads out_channels_qk = heads * dim_qk out_channels_v = heads * dim_v self.to_qk = nn.Conv2D(dim, out_channels_qk * 2, 1, bias_attr=False) self.to_v = nn.Conv2D(dim, out_channels_v, 1, bias_attr=False) self.softmax = nn.Softmax(axis=-1) height, width = fmap_size self.pos_emb = RelPosEmb(height, width, dim_qk) def transpose_multihead(self, x): B, N, H, W = x.shape x = x.reshape([B, self.heads, -1, H, W]) # "B (h D) H W -> B h D H W" x = x.transpose(perm=[0, 1, 3, 4, 2]) # "B h D H W -> B h H W D" x = x.reshape([B, self.heads, H*W, -1]) # "B h H W D -> B h (H W) D" return x def forward(self, featuremap): """ featuremap: [B, d_in, H, W] Output: [B, H, W, head * d_v] """ B, C, H, W = featuremap.shape q, k = self.to_qk(featuremap).chunk(2, axis=1) v = self.to_v(featuremap) q, k, v = map(self.transpose_multihead, [q, k, v]) q *= self.scale logits = paddle.matmul(q, k.transpose(perm=[0, 1, 3, 2])) logits += self.pos_emb(q) weights = self.softmax(logits) attn_out = paddle.matmul(weights, v) a_B, a_N, a_, a_D = attn_out.shape attn_out = attn_out.reshape([a_B, a_N, H, -1, a_D]) # "B N (H W) D -> B N H W D" attn_out = attn_out.transpose(perm=[0, 1, 4, 2, 3]) # "B N H W D -> B N D H W" attn_out = attn_out.reshape([a_B, a_N*a_D, H, -1]) # "B N D H W -> B (N D) H W" return attn_outclass ConvNormLayer(nn.Layer): def __init__(self, ch_in, ch_out, filter_size, stride, groups=1, act=None, norm_type='bn', norm_decay=0., freeze_norm=True, lr=1.0, dcn_v2=False): super(ConvNormLayer, self).__init__() assert norm_type in ['bn', 'sync_bn'] self.norm_type = norm_type self.act = act self.dcn_v2 = dcn_v2 if not self.dcn_v2: self.conv = nn.Conv2D( in_channels=ch_in, out_channels=ch_out, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, groups=groups, weight_attr=ParamAttr(learning_rate=lr), bias_attr=False) else: self.offset_channel = 2 * filter_size**2 self.mask_channel = filter_size**2 self.conv_offset = nn.Conv2D( in_channels=ch_in, out_channels=3 * filter_size**2, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, weight_attr=ParamAttr(initializer=Constant(0.)), bias_attr=ParamAttr(initializer=Constant(0.))) self.conv = DeformConv2D( in_channels=ch_in, out_channels=ch_out, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, dilation=1, groups=groups, weight_attr=ParamAttr(learning_rate=lr), bias_attr=False) norm_lr = 0. if freeze_norm else lr param_attr = ParamAttr( learning_rate=norm_lr, regularizer=L2Decay(norm_decay), trainable=False if freeze_norm else True) bias_attr = ParamAttr( learning_rate=norm_lr, regularizer=L2Decay(norm_decay), trainable=False if freeze_norm else True) global_stats = True if freeze_norm else False if norm_type == 'sync_bn': self.norm = nn.SyncBatchNorm( ch_out, weight_attr=param_attr, bias_attr=bias_attr) else: self.norm = nn.BatchNorm( ch_out, act=None, param_attr=param_attr, bias_attr=bias_attr, use_global_stats=global_stats) norm_params = self.norm.parameters() if freeze_norm: for param in norm_params: param.stop_gradient = True def forward(self, inputs): if not self.dcn_v2: out = self.conv(inputs) else: offset_mask = self.conv_offset(inputs) offset, mask = paddle.split( offset_mask, num_or_sections=[self.offset_channel, self.mask_channel], axis=1) mask = F.sigmoid(mask) out = self.conv(inputs, offset, mask=mask) if self.norm_type in ['bn', 'sync_bn']: out = self.norm(out) if self.act: out = getattr(F, self.act)(out) return outclass SELayer(nn.Layer): def __init__(self, ch, reduction_ratio=16): super(SELayer, self).__init__() self.pool = nn.AdaptiveAvgPool2D(1) stdv = 1.0 / math.sqrt(ch) c_ = ch // reduction_ratio self.squeeze = nn.Linear( ch, c_, weight_attr=paddle.ParamAttr(initializer=Uniform(-stdv, stdv)), bias_attr=True) stdv = 1.0 / math.sqrt(c_) self.extract = nn.Linear( c_, ch, weight_attr=paddle.ParamAttr(initializer=Uniform(-stdv, stdv)), bias_attr=True) def forward(self, inputs): out = self.pool(inputs) out = paddle.squeeze(out, axis=[2, 3]) out = self.squeeze(out) out = F.relu(out) out = self.extract(out) out = F.sigmoid(out) out = paddle.unsqueeze(out, axis=[2, 3]) scale = out * inputs return scaleclass BasicBlock(nn.Layer): expansion = 1 def __init__(self, ch_in, ch_out, stride, shortcut, variant='b', groups=1, base_width=64, lr=1.0, norm_type='bn', norm_decay=0., freeze_norm=True, dcn_v2=False, std_senet=False): super(BasicBlock, self).__init__() assert dcn_v2 is False, "Not implemented yet." assert groups == 1 and base_width == 64, 'BasicBlock only supports groups=1 and base_width=64' self.shortcut = shortcut if not shortcut: if variant == 'd' and stride == 2: self.short = nn.Sequential() self.short.add_sublayer( 'pool', nn.AvgPool2D( kernel_size=2, stride=2, padding=0, ceil_mode=True)) self.short.add_sublayer( 'conv', ConvNormLayer( ch_in=ch_in, ch_out=ch_out, filter_size=1, stride=1, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr)) else: self.short = ConvNormLayer( ch_in=ch_in, ch_out=ch_out, filter_size=1, stride=stride, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.branch2a = ConvNormLayer( ch_in=ch_in, ch_out=ch_out, filter_size=3, stride=stride, act='relu', norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.branch2b = ConvNormLayer( ch_in=ch_out, ch_out=ch_out, filter_size=3, stride=1, act=None, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.std_senet = std_senet if self.std_senet: self.se = SELayer(ch_out) def forward(self, inputs): out = self.branch2a(inputs) out = self.branch2b(out) if self.std_senet: out = self.se(out) if self.shortcut: short = inputs else: short = self.short(inputs) out = paddle.add(x=out, y=short) out = F.relu(out) return outclass BottleNeck(nn.Layer): expansion = 4 def __init__(self, x, y, z, ch_in, # 1024 ch_out, #512 stride, # shortcut, img_size=(640,640), variant='b', groups=1, base_width=4, lr=1.0, norm_type='bn', norm_decay=0., freeze_norm=True, dcn_v2=False, std_senet=False): super(BottleNeck, self).__init__() if variant == 'a': stride1, stride2 = stride, 1 else: stride1, stride2 = 1, stride # ResNeXt width = int(ch_out * (base_width / 64.)) * groups self.shortcut = shortcut if not shortcut: if variant == 'd' and stride == 2: self.short = nn.Sequential() self.short.add_sublayer( 'pool', nn.AvgPool2D( kernel_size=2, stride=2, padding=0, ceil_mode=True)) self.short.add_sublayer( 'conv', ConvNormLayer( ch_in=ch_in, ch_out=ch_out * self.expansion, filter_size=1, stride=1, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr)) else: self.short = ConvNormLayer( ch_in=ch_in, ch_out=ch_out * self.expansion, filter_size=1, stride=stride, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.branch2a = ConvNormLayer( ch_in=ch_in, ch_out=width, filter_size=1, stride=stride1, groups=1, act='relu', norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) if x and y: self.branch2b = paddle.nn.LayerList() self.branch2b.append(MHSA(512,[40, 40],4,128,128)) self.branch2b.append(paddle.nn.AvgPool2D(2, 2)) self.branch2b = paddle.nn.Sequential(*self.branch2b) elif x and not y: if z==0 : self.branch2b = MHSA(512,[20, 20],4,128,128) elif z==1: self.branch2b = ConvNormLayer( ch_in=width, ch_out=width, filter_size=3, stride=stride2, groups=groups, act='relu', norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr, dcn_v2=True) else: self.branch2b = ConvNormLayer( ch_in=width, ch_out=width, filter_size=3, stride=stride2, groups=groups, act='relu', norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr, dcn_v2=dcn_v2) self.branch2c = ConvNormLayer( ch_in=width, ch_out=ch_out * self.expansion, filter_size=1, stride=1, groups=1, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, lr=lr) self.std_senet = std_senet if self.std_senet: self.se = SELayer(ch_out * self.expansion) def forward(self, inputs): out = self.branch2a(inputs) out = self.branch2b(out) out = self.branch2c(out) if self.std_senet: out = self.se(out) if self.shortcut: short = inputs else: short = self.short(inputs) out = paddle.add(x=out, y=short) out = F.relu(out) return outclass Blocks(nn.Layer): def __init__(self, block, x, ch_in, ch_out, count, name_adapter, stage_num, img_size = (640,640), variant='b', groups=1, base_width=64, lr=1.0, norm_type='bn', norm_decay=0., freeze_norm=True, dcn_v2=False, std_senet=False): super(Blocks, self).__init__() self.blocks = [] for i in range(count): if i == 0: y = 1 z = 0 else: if i==count-1: y = 0 z = 1 else: y = 0 z = 0 conv_name = name_adapter.fix_layer_warp_name(stage_num, count, i) layer = self.add_sublayer( conv_name, block( x, y, z, ch_in=ch_in, ch_out=ch_out, stride=2 if i == 0 and stage_num != 2 else 1, shortcut=False if i == 0 else True, img_size=img_size, variant=variant, groups=groups, base_width=base_width, lr=lr, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, dcn_v2=dcn_v2, std_senet=std_senet)) self.blocks.append(layer) if i == 0: ch_in = ch_out * block.expansion def forward(self, inputs): block_out = inputs for block in self.blocks: block_out = block(block_out) return block_out@register@serializableclass BotNet(nn.Layer): __shared__ = ['norm_type'] def __init__(self, depth=50, img_size = [20,20], ch_in=64, variant='b', lr_mult_list=[1.0, 1.0, 1.0, 1.0], groups=1, base_width=64, norm_type='bn', norm_decay=0, freeze_norm=True, freeze_at=0, return_idx=[0, 1, 2, 3], dcn_v2_stages=[-1], # [3] num_stages=4, std_senet=False): """ Residual Network, see https://arxiv.org/abs/1512.03385 Args: depth (int): ResNet depth, should be 18, 34, 50, 101, 152. ch_in (int): output channel of first stage, default 64 variant (str): ResNet variant, supports 'a', 'b', 'c', 'd' currently lr_mult_list (list): learning rate ratio of different resnet stages(2,3,4,5), lower learning rate ratio is need for pretrained model got using distillation(default as [1.0, 1.0, 1.0, 1.0]). groups (int): group convolution cardinality base_width (int): base width of each group convolution norm_type (str): normalization type, 'bn', 'sync_bn' or 'affine_channel' norm_decay (float): weight decay for normalization layer weights freeze_norm (bool): freeze normalization layers freeze_at (int): freeze the backbone at which stage return_idx (list): index of the stages whose feature maps are returned dcn_v2_stages (list): index of stages who select deformable conv v2 num_stages (int): total num of stages std_senet (bool): whether use senet, default True """ super(BotNet, self).__init__() self._model_type = 'ResNet' if groups == 1 else 'ResNeXt' assert num_stages >= 1 and num_stages <= 4 self.depth = depth self.variant = variant self.groups = groups self.base_width = base_width self.norm_type = norm_type self.norm_decay = norm_decay self.freeze_norm = freeze_norm self.freeze_at = freeze_at if isinstance(return_idx, Integral): return_idx = [return_idx] assert max(return_idx) < num_stages, 'the maximum return index must smaller than num_stages, ' 'but received maximum return index is {} and num_stages ' 'is {}'.format(max(return_idx), num_stages) self.return_idx = return_idx self.num_stages = num_stages assert len(lr_mult_list) == 4, "lr_mult_list length must be 4 but got {}".format(len(lr_mult_list)) if isinstance(dcn_v2_stages, Integral): dcn_v2_stages = [dcn_v2_stages] assert max(dcn_v2_stages) < num_stages if isinstance(dcn_v2_stages, Integral): dcn_v2_stages = [dcn_v2_stages] assert max(dcn_v2_stages) = 50 else BasicBlock self._out_channels = [block.expansion * v for v in ch_out_list] self._out_strides = [4, 8, 16, 32] self.res_layers = [] for i in range(num_stages): if i == 3 : x = 1 else : x = 0 lr_mult = lr_mult_list[i] stage_num = i + 2 res_name = "res{}".format(stage_num) res_layer = self.add_sublayer( res_name, Blocks( block, x, self.ch_in, ch_out_list[i], count=block_nums[i], name_adapter=na, stage_num=stage_num, img_size = img_size, variant=variant, groups=groups, base_width=base_width, lr=lr_mult, norm_type=norm_type, norm_decay=norm_decay, freeze_norm=freeze_norm, dcn_v2=(i in self.dcn_v2_stages), std_senet=std_senet)) self.res_layers.append(res_layer) self.ch_in = self._out_channels[i] @property def out_shape(self): return [ ShapeSpec( channels=self._out_channels[i], stride=self._out_strides[i]) for i in self.return_idx ] def forward(self, inputs): # x = inputs['image'][:,0,:,:] x = inputs['image'] # x = paddle.unsqueeze(x,axis=1) conv1 = self.conv1(x) x = F.max_pool2d(conv1, kernel_size=3, stride=2, padding=1) outs = [] for idx, stage in enumerate(self.res_layers): x = stage(x) if idx == self.freeze_at: x.stop_gradient = True if idx in self.return_idx: outs.append(x) return outs@registerclass Bot5Head(nn.Layer): def __init__(self, depth=50): super(Bot5Head, self).__init__() feat_in, feat_out = [1024, 512] if depth = 50 else BasicBlock self.res5 = Blocks("" block, feat_in, feat_out, count=3, name_adapter=na, stage_num=5) self.feat_out = feat_out if depth < 50 else feat_out * 4 @property def out_shape(self): return [ShapeSpec( channels=self.feat_out, stride=16, )] def forward(self, roi_feat, stage=0): y = self.res5(roi_feat) return y
YOLO [X] HEAD源码
In [ ]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle import ParamAttrfrom paddle.regularizer import L2Decayfrom ppdet.core.workspace import registerdef _de_sigmoid(x, eps=1e-7): x = paddle.clip(x, eps, 1. / eps) x = paddle.clip(1. / x - 1., eps, 1. / eps) x = -paddle.log(x) return xclass SiLU(nn.Layer): @staticmethod def forward(x): return x * F.sigmoid(x)def mish(x): return x * paddle.tanh(F.softplus(x))class BaseConv(nn.Layer): def __init__(self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"): super().__init__() pad = (ksize - 1) // 2 self.conv = nn.Conv2D(in_channels, out_channels, kernel_size=ksize, stride=stride, padding=pad, groups=groups, bias_attr=bias) self.bn = nn.SyncBatchNorm( out_channels) self.act = mish def forward(self, x): return self.act(self.bn(self.conv(x)))class DWConv(nn.Layer): def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"): super().__init__() self.dconv = BaseConv(in_channels, in_channels, ksize=ksize, stride=stride, groups=in_channels, act=act,) self.pconv = BaseConv(in_channels, out_channels, ksize=1, stride=1, groups=1, act=act) def forward(self, x): x = self.dconv(x) return self.pconv(x)# def _de_sigmoid(x, eps=1e-7):# x = paddle.clip(x, eps, 1. / eps)# x = paddle.clip(1. / x - 1., eps, 1. / eps)# x = -paddle.log(x)# return x@registerclass YOLOvXHead(nn.Layer): __shared__ = ['num_classes', 'data_format'] __inject__ = ['loss'] def __init__(self, in_channels=[1024, 512, 256], anchors=[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]], anchor_masks=[[6, 7, 8], [3, 4, 5], [0, 1, 2]], num_classes=80, loss='YOLOv3Loss', iou_aware=False, iou_aware_factor=0.4, data_format='NCHW'): """ Head for YOLOv3 network Args: num_classes (int): number of foreground classes anchors (list): anchors anchor_masks (list): anchor masks loss (object): YOLOv3Loss instance iou_aware (bool): whether to use iou_aware iou_aware_factor (float): iou aware factor data_format (str): data format, NCHW or NHWC """ super(YOLOvXHead, self).__init__() assert len(in_channels) > 0, "in_channels length should > 0" self.in_channels = in_channels self.num_classes = num_classes self.loss = loss self.iou_aware = iou_aware self.iou_aware_factor = iou_aware_factor self.parse_anchor(anchors, anchor_masks) self.num_outputs = len(self.anchors) self.data_format = data_format self.yolo_outputs = [] self.stems = nn.LayerList() self.cls_convs = nn.LayerList() self.reg_convs = nn.LayerList() self.cls_preds = nn.LayerList() self.reg_preds = nn.LayerList() self.obj_preds = nn.LayerList() #self.iou = nn.LayerList() act = 'RELU' for i in range(len(self.anchors)): if self.iou_aware: num_filters = len(self.anchors[i]) * (self.num_classes + 6) else: num_filters = len(self.anchors[i]) * (self.num_classes + 5) self.stems.append(BaseConv(in_channels=int( in_channels[i]), out_channels=int(in_channels[i]), ksize=1, stride=1, act=act)) self.cls_convs.append(nn.Sequential(*[ BaseConv(in_channels=int(in_channels[i]), out_channels=int( in_channels[i]), ksize=3, stride=1, act=act), BaseConv(in_channels=int(in_channels[i]), out_channels=int( in_channels[i]), ksize=3, stride=1, act=act) ])) self.cls_preds.append( nn.Conv2D(in_channels=int(in_channels[i]), out_channels=( 1+self.num_classes)*3, kernel_size=1, stride=1, padding=0) ) self.reg_convs.append(nn.Sequential(*[ BaseConv(in_channels=int(in_channels[i]), out_channels=int( in_channels[i]), ksize=3, stride=1, act=act), BaseConv(in_channels=int(in_channels[i]), out_channels=int( in_channels[i]), ksize=3, stride=1, act=act) ])) self.reg_preds.append( nn.Conv2D(in_channels=int(in_channels[i]), out_channels=4 * 3, kernel_size=1, stride=1, padding=0) ) if self.iou_aware: self.obj_preds.append( nn.Conv2D(in_channels=int(in_channels[i]), out_channels=1 * 3, kernel_size=1, stride=1, padding=0) ) name = 'yolo_output.{}'.format(i) conv = nn.Conv2D( in_channels=self.in_channels[i], out_channels=num_filters, kernel_size=1, stride=1, padding=0, data_format=data_format, bias_attr=ParamAttr(regularizer=L2Decay(0.))) conv.skip_quant = True yolo_output = self.add_sublayer(name, conv) self.yolo_outputs.append(yolo_output) def parse_anchor(self, anchors, anchor_masks): self.anchors = [[anchors[i] for i in mask] for mask in anchor_masks] self.mask_anchors = [] anchor_num = len(anchors) for masks in anchor_masks: self.mask_anchors.append([]) for mask in masks: assert mask < anchor_num, "anchor mask index overflow" self.mask_anchors[-1].extend(anchors[mask]) def forward(self, feats, targets=None): #-------------------------------------# # feats 三层特征图 #-------------------------------------# #-------------------------------------# # targets # im_id # is_crowd # gt_bbox # curr_iter # image # im_shape # scale_factor # target0 # target1 # target2 #-------------------------------------# assert len(feats) == len(self.anchors) yolo_outputs = [] for i, feat in enumerate(feats): #---------------------------------------------------# # 利用1x1卷积进行通道整合 #---------------------------------------------------# x = self.stems[i](feat) #---------------------------------------------------# # 利用两个卷积标准化激活函数来进行特征提取 #---------------------------------------------------# cls_feat = self.cls_convs[i](x) #---------------------------------------------------# # 判断特征点所属的种类 # 80, 80, num_classes # 40, 40, num_classes # 20, 20, num_classes #---------------------------------------------------# cls_output = self.cls_preds[i](cls_feat) #---------------------------------------------------# # 利用两个卷积标准化激活函数来进行特征提取 #---------------------------------------------------# reg_feat = self.reg_convs[i](x) #---------------------------------------------------# # 特征点的回归系数 # reg_pred 80, 80, 4 # reg_pred 40, 40, 4 # reg_pred 20, 20, 4 #---------------------------------------------------# reg_output = self.reg_preds[i](reg_feat) #---------------------------------------------------# # 判断特征点是否有对应的物体 # obj_pred 80, 80, 1 # obj_pred 40, 40, 1 # obj_pred 20, 20, 1 #---------------------------------------------------# if self.iou_aware: obj_output = self.obj_preds[i](reg_feat) if self.iou_aware: output = paddle.concat([obj_output, reg_output, cls_output], 1) else: output = paddle.concat([reg_output, cls_output], 1) yolo_outputs.append(output) if self.training: return self.loss(yolo_outputs, targets, self.anchors) else: if self.iou_aware: y = [] for i, out in enumerate(yolo_outputs): na = len(self.anchors[i]) ioup, x = out[:, 0:na, :, :], out[:, na:, :, :] b, c, h, w = x.shape no = c // na x = x.reshape((b, na, no, h * w)) ioup = ioup.reshape((b, na, 1, h * w)) obj = x[:, :, 4:5, :] ioup = F.sigmoid(ioup) obj = F.sigmoid(obj) obj_t = (obj**(1 - self.iou_aware_factor)) * ( ioup**self.iou_aware_factor) obj_t = _de_sigmoid(obj_t) loc_t = x[:, :, :4, :] cls_t = x[:, :, 5:, :] y_t = paddle.concat([loc_t, obj_t, cls_t], axis=2) y_t = y_t.reshape((b, c, h, w)) y.append(y_t) return y else: return yolo_outputs @classmethod def from_config(cls, cfg, input_shape): return {'in_channels': [i.channels for i in input_shape], }
以上就是【创造营第二期】水下声呐探测,带你揭开海底的真实面纱的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/40135.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























