
中山大学、香港科技大学、上海交通大学和华为诺亚方舟实验室的研究人员提出了一种名为 atomthink 的新框架,旨在提升多模态大语言模型 (mllm) 解决高级数学推理问题的能力。该框架通过将“慢思考”策略融入mllm,显著提高了模型在基准数学测试中的性能,并具有良好的可迁移性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AtomThink 框架的核心在于其对“原子步骤”的关注。“原子步骤”指的是语义上不可再分的最小推理单元。该框架包含三个关键组件:多模态注释引擎、原子步骤指令微调和策略搜索。
挑战与创新:
现有方法通常依赖于精心设计的提示来激发模型的思维链 (CoT),但忽略了推理链中中间步骤的质量。AtomThink 则通过原子步骤质量评估策略,对每个步骤进行细致分析,从而识别并改进薄弱环节。该策略借鉴了GPT-4o的推理行为,构建了一个规范的推理能力集合,并利用结果监督和重映射来评估模型在不同能力项上的得分。

AtomThink 框架详解:
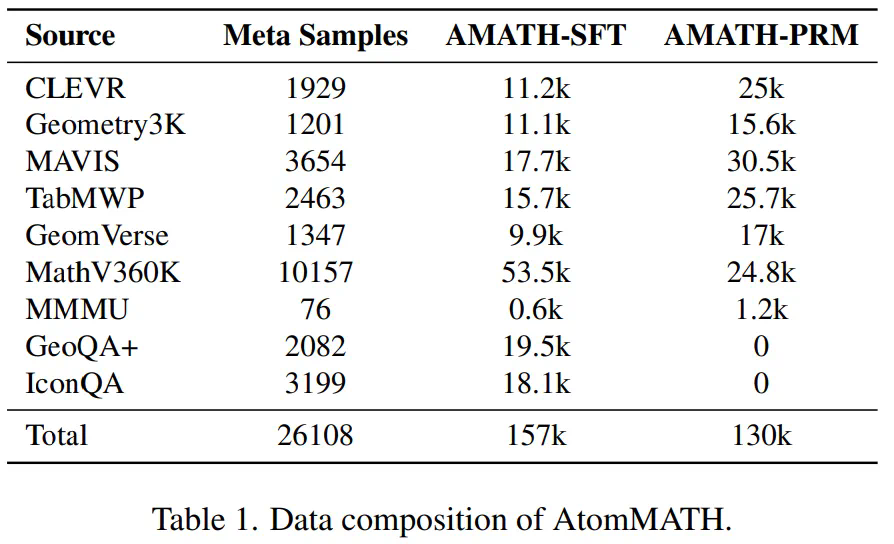
多模态注释引擎: 该引擎利用动态提示和短 CoT 增强策略,从现有数据集中生成高质量的长 CoT 数据。它通过GPT-4o辅助,将原始推理过程分解成多个原子步骤,并创建了 AtomMATH 数据集 (包括AMATH-SFT 和 AMATH-PRM 两个子集)。
 SpeakingPass-打造你的专属雅思口语语料
SpeakingPass-打造你的专属雅思口语语料
使用chatGPT帮你快速备考雅思口语,提升分数
 25 查看详情
25 查看详情 
原子步骤微调: 该步骤对 MLLM 进行指令微调和过程监督训练 (PRM),以增强其解码能力,并使其学习近似马尔可夫决策过程的输出格式。
策略搜索: 为了从多个候选步骤中选择最佳路径,AtomThink 框架采用了路径维度搜索 (多数投票、Best-of-N) 和步骤维度搜索 (贪心算法、Beam Search)。
实验结果与结论:
实验结果表明,AtomThink 框架在 MathVista 和 MathVerse 两个基准测试中显著提升了模型的性能。与基线模型相比,AtomThink 在 QuickThink (快速推理) 模式下已经取得了显著改进;而在 SlowThink (慢速推理,利用 Beam Search) 模式下,性能提升更为显著,甚至超过了一倍。 Best-of-N 策略结合平均得分聚合,取得了最佳性能。 研究还验证了 Test-time scaling law 在多模态数学推理任务中的存在。
该研究为构建更强大的慢思考模型提供了新的思路,也为解决复杂数学推理问题提供了有效的解决方案。论文及代码即将开源:
论文:https://www.php.cn/link/5c3165e90eb8727c7dd0f9434cbd2bba主页 (即将开源): https://www.php.cn/link/1852a2083dbe1c2ec33ab9366feb2862
以上就是多模态慢思考:分解原子步骤以解决复杂数学推理的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/402298.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























