光真实感模拟在自动驾驶等应用中发挥着关键作用,其中神经网络辐射场(NeRFs)的进步可能通过自动创建数字3D资产来实现更好的可扩展性。然而,由于街道上相机运动的高度共线性和在高速下的稀疏采样,街景的重建质量受到影响。另一方面,该应用通常需要从偏离输入视角的相机视角进行渲染,以准确模拟如变道等行为。LidaRF提出了几个见解,允许更好地利用激光雷达数据来改善街景中NeRF的质量。首先,框架从激光雷达数据中学习几何场景表示,这些表示与基于隐式网格的解码器相结合,从而提供了由显示点云提供的更强的几何信息。其次,提出了一种鲁棒的遮挡感知深度监督训练策略,允许通过累积使用密集激光雷达点云的强势信息来改善街景中的NeRF重建质量。第三,根据激光雷达点的强度生成增强的训练视角,以进一步改进在真实驾驶场景下的新视角合成中获取的显著改进。这样,通过框架从激光雷达数据中学习到的更加准确的几何场景表示,可以一步改进方法并在真实驾驶场景下获取更好的显著改进。
LidaRF的贡献主要体现在三个方面:
(i)混合激光雷达编码和网格特征以增强场景表示。虽然激光雷达已被用作自然的深度监控源,但将激光雷达纳入NeRF输入中,为几何归纳提供了巨大的潜力,但实现起来并不简单。为此,借用了基于网格的表示法,但将从点云中学习的特征融合到网格中,以继承显式点云表示法的优势。通过3D感知框架成功的启动,利用3D稀疏疗卷积网络作为一种有效且高效的结构,从激光雷达点云的局部和全局上下文中提取几何特征。
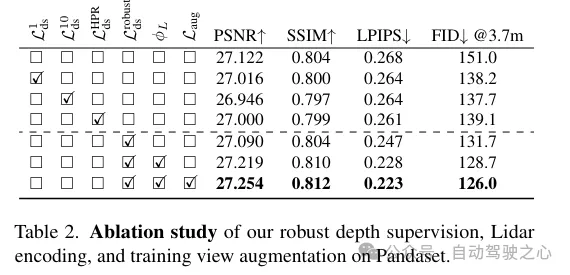
(ii)鲁棒的遮挡感知深度监督。与现有工作类似,这里也使用激光雷达作为深度监督的来源,但更加深入。由于激光雷达点的稀疏性限制了其有效性,尤其是在低纹理区域,通过跨邻近帧集化激光雷达点来生成更密集的深度图。然而,这样获得的深度图没有考虑到遮挡,产生了错误的深度监督。因此,提出了一种健壮的深度监督方案,借用class学习的方式——从近场到远场逐步监督深度,并在NeRF训练过程中逐渐滤除错误的深度,从而更有效地从激光雷达中学习深度。
(iii)基于激光雷达的视图增强。此外,鉴于驾驶场景中的视图稀疏性和覆盖有限,利用激光雷达来密集化训练视图。也就是说,将累积的激光雷达点投影到新的训练视图中;请注意,这些视图可能与驾驶轨迹有一定的偏离。这些从激光雷达投影的视图被添加到训练数据集中,它们并没有考虑到遮挡问题。然而,我们应用了前面提到的监督方案来解决遮挡问题,从而提高了性能。虽然我们的方法也适用于一般场景,但在这项工作中更专注于街道场景的评估,并与现有技术相比,无论是定量还是定性,都取得了显著的改进。
LidaRF在需要更大程度偏离输入视图的有趣应用中也显示出优势,在具有挑战性的街道场景应用中显著提高了NeRF的质量。
LidaRF整体框架一览
LidaRF是一种用于输入和输出对应的密度和颜色的方法,它采用了UNet融合了哈夫编码和激光雷达编码。此外,通过激光雷达投影生成强化训练数据,使用提出的健壮深度监督方案训练几何预测。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
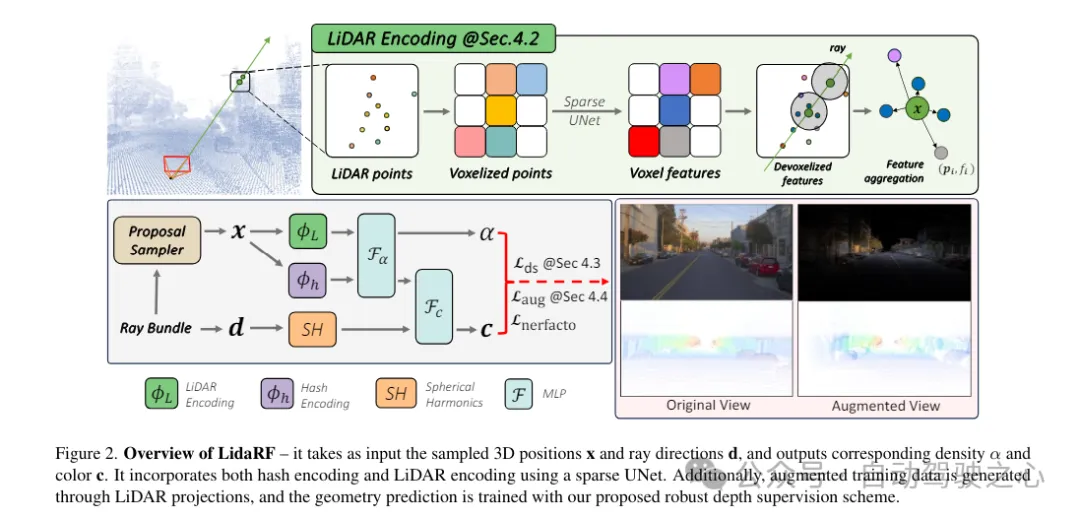
1)激光雷达编码的混合表示法
激光雷达点云具有强大的几何指导潜力,这对NeRF(神经渲染场)来说极具价值。然而,仅依赖激光雷达特征来进行场景表示,由于激光雷达点的稀疏性(尽管有时间累积),会导致低分辨率的渲染。此外,由于激光雷达的视野有限,例如它不能捕获超过一定高度的建筑物表面,因此在这些区域中会出现空白渲染。相比之下,本文的框架融合了激光雷达特征和高分辨率的空间网格特征,以利用两者的优势,并共同学习以实现高质量和完整的场景渲染。
激光雷达特征提取。在这里详细描述了每个激光雷达点的几何特征提取过程,参照图2,首先将整个序列的所有帧的激光雷达点云聚合起来,以构建更密集的点云集合。然后将点云体素化为体素网格,其中每个体素单元内的点的空间位置进行平均,为每个体素单元生成一个3维特征。受到3D感知框架广泛成功的启发,在体素网格上使用3D稀疏UNet对场景几何特征进行编码,这允许从场景几何的全局上下文中学习。3D稀疏UNet将体素网格及其3维特征作为输入,并输出neural volumetric 特征,每个被占用的体素由n维特征组成。
 寻光
寻光
阿里达摩院寻光视频创作平台,以视觉AIGC为核心功能,用PPT制作的方式创作视频
 70 查看详情
70 查看详情 
激光雷达特征查询。对于沿着要渲染的射线上的每个样本点x,如果在搜索半径R内有至少K个附近的激光雷达点,则查询其激光雷达特征;否则,其激光雷达特征被设置为空(即全零)。具体来说,采用固定半径最近邻(FRNN)方法来搜索与x相关的K个最近的激光雷达点索引集,记作。与[9]中在启动训练过程之前预先确定射线采样点的方法不同,本文的方法在执行FRNN搜索时是实时的,因为随着NeRF训练的收敛,来自region网络的样本点分布会动态地趋向于集中在表面上。遵循Point-NeRF的方法,我们的方法利用一个多层感知机(MLP)F,将每个点的激光雷达特征映射到神经场景描述中。对于x的第i个邻近点,F将激光雷达特征和相对位置作为输入,并输出神经场景描述作为:
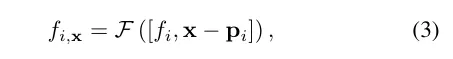
为了获得采样位置x处的最终激光雷达编码ϕ,使用标准的反距离权重法来聚合其K个邻近点的神经场景描述
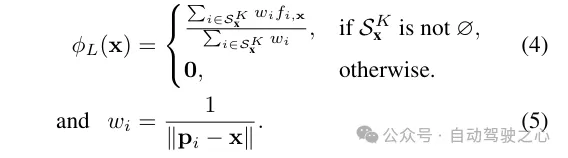
辐射解码的特征融合。将激光雷达编码ϕL与哈希编码ϕh进行拼接,并应用一个多层感知机Fα来预测每个样本的密度α和密度嵌入h。最后,通过另一个多层感知机Fc,根据观察方向d的球面谐波编码SH和密度嵌入h来预测相应的颜色c。
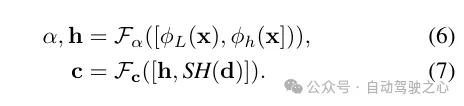
2)鲁棒深度监督
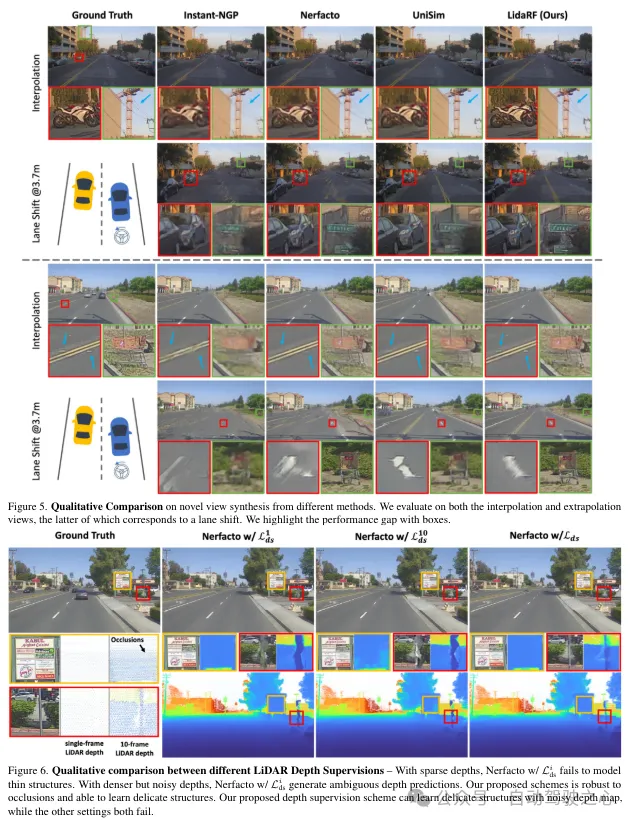
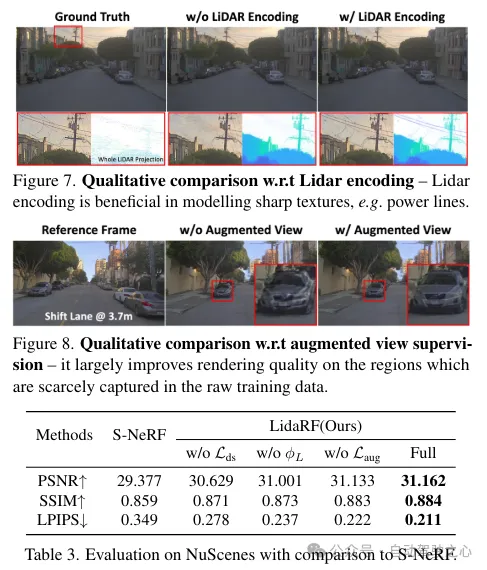
除了特征编码外,还通过将激光雷达点投影到图像平面上来从它们中获取深度监督。然而,由于激光雷达点的稀疏性,所得益处有限,不足以重建低纹理区域,如路面。在这里,我们提出累积相邻的激光雷达帧以增加密度。尽管3D点能够准确地捕获场景结构,但在将它们投影到图像平面以进行深度监督时,需要考虑点之间的遮挡。遮挡是由于相机与激光雷达及其相邻帧之间的位移增加而产生的,从而产生虚假的深度监督,如图3所示。由于即使累积后激光雷达的稀疏性,处理这个问题也非常困难,使得诸如z缓冲之类的基本原理图形技术无法应用。在这项工作中,提出了一种鲁棒的监督方案,以在训练NeRF时自动过滤掉虚假的深度监督。

遮挡感知的鲁棒监督方案。本文设计了一个class训练策略,使得模型最初使用更近、更可靠的深度数据进行训练,这些数据更不容易受到遮挡的影响。随着训练的进行,模型逐渐开始融合更远的深度数据。同时,模型还具备了丢弃与其预测相比异常遥远的深度监督的能力。
回想一下,由于车载摄像头的向前运动,它产生的训练图像是稀疏的,视野覆盖有限,这给NeRF重建带来了挑战,尤其是当新视图偏离车辆轨迹时。在这里,我们提出利用激光雷达来增强训练数据。首先,我们通过将每个激光雷达帧的点云投影到其同步的摄像头上并为RGB值进行插值来为其上色。累积上色的点云,并将其投影到一组合成增强的视图上,生成如图2所示的合成图像和深度图。
实验对比分析
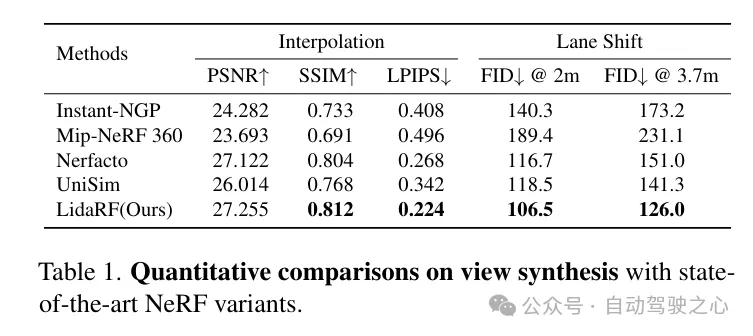

以上就是LidaRF:研究用于街景神经辐射场的激光雷达数据(CVPR’24)的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/418021.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫