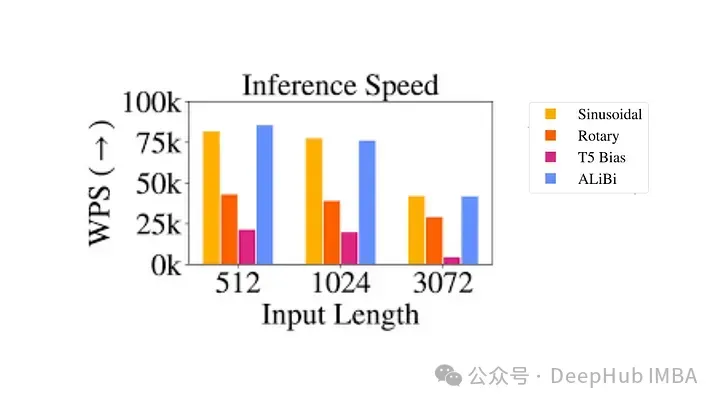
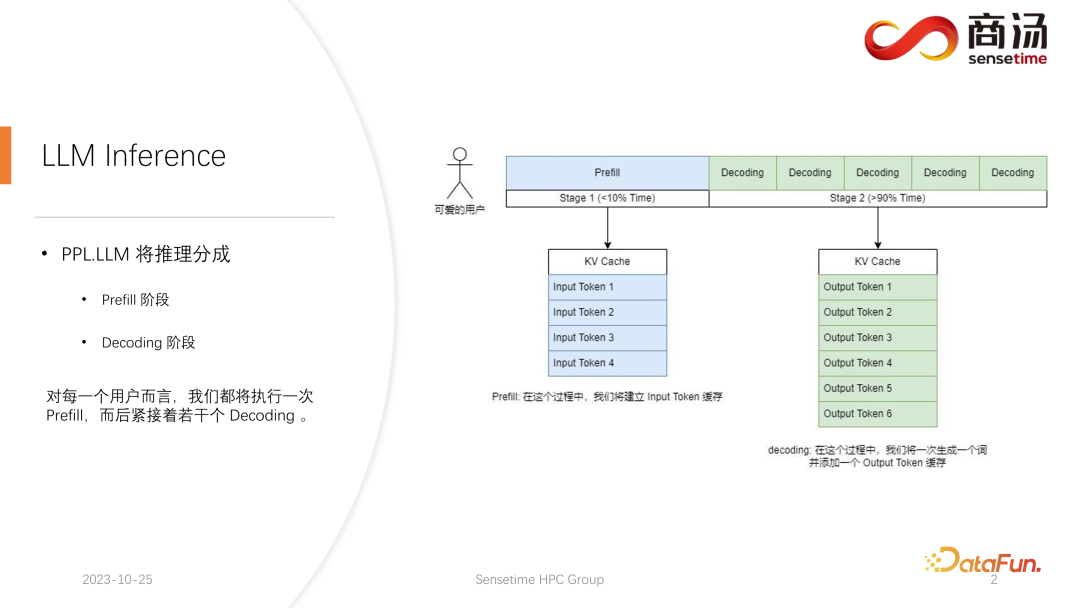
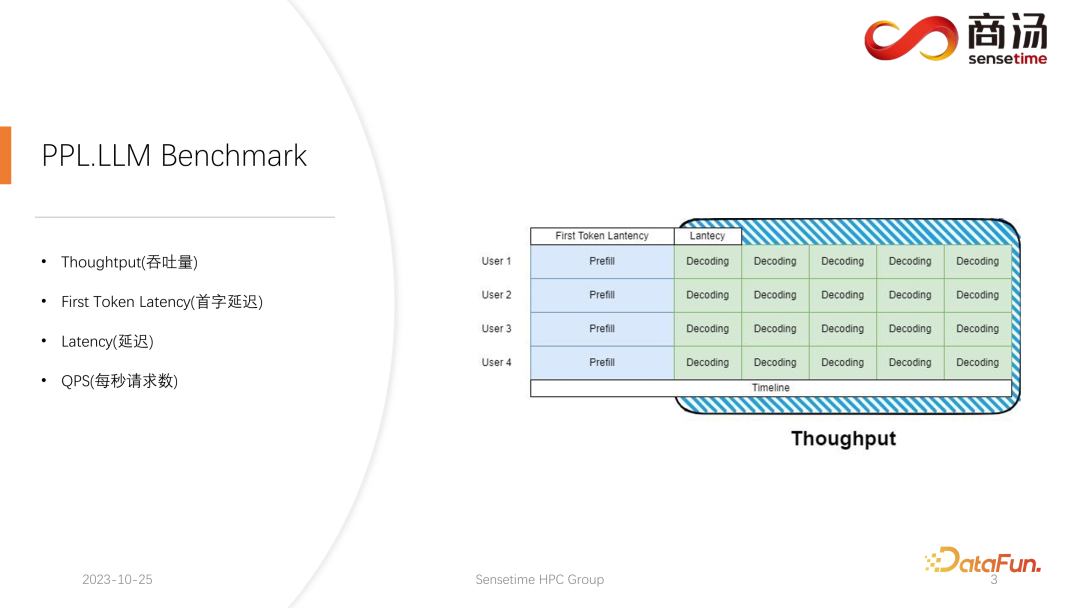
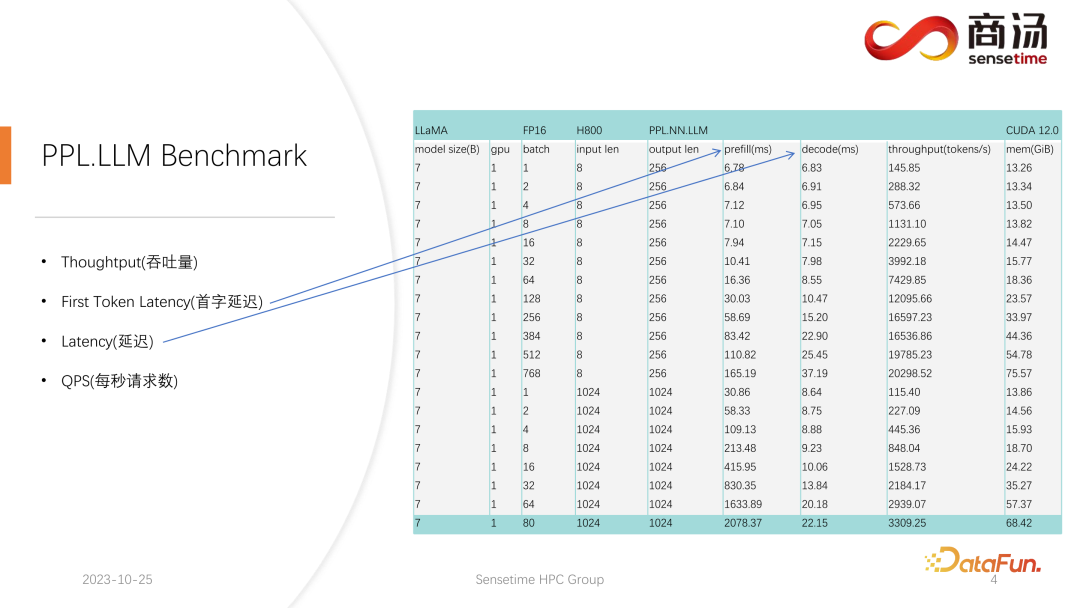
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

亚马逊云计算人工智能实验室的研究人员最近发现,网络上存在大量由机器翻译生成的内容,而这些翻译跨越多种语言的质量普遍较低。研究团队强调了在训练大型语言模型时,数据质量和来源的重要性。这一发现突显了在构建高质量语言模型时,需要更加关注数据的质量和来源的选择。
研究还发现,机器生成内容在资源较少语言的翻译中很普遍,并占网络内容的很大一部分。
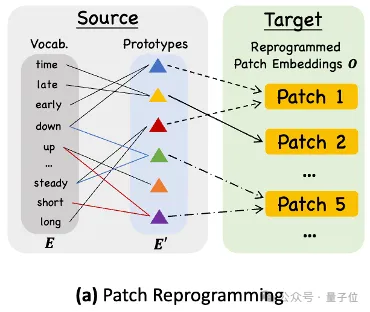
本站注意到,研究团队开发了名为MWccMatrix的庞大资源,用于更好地理解机器翻译内容的特征。该资源包含64亿个独特句子,覆盖了90种语言,并提供了相互翻译的句子组合,即翻译元组。
这项研究发现,大量网络内容通常通过机器翻译被翻译成多种语言。这种现象普遍存在于资源较少语言的翻译中,并且占据了这些语言网络内容的很大一部分。
 豆包大模型
豆包大模型
字节跳动自主研发的一系列大型语言模型
 834 查看详情
834 查看详情 
研究人员还注意到,出于广告收入等目的,被翻译成多种语言的内容存在选择性偏差。
根据我的研究,我得出以下结论:“过去十年,机器翻译技术取得了显著进步,但仍然无法达到人类质量水平。在过去的多年中,人们使用了当时可用的机器翻译系统将内容添加到网络上,因此网络上大部分机器翻译内容的质量可能相对较低,无法满足现代标准。这可能导致LLM模型产生更多的‘幻觉’,而选择偏差则表明即使不考虑机器翻译错误,数据质量也可能较低。对于LLM的训练来说,数据质量至关重要,高质量的语料库,如书籍和维基百科文章,通常需要进行多次向上采样。”
以上就是研究:网络充斥低质机翻内容,大语言模型训练需警惕数据陷阱的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/428040.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫