it之家 1 月 9 日消息,meta 日前公布了一项名为 audio2photoreal 的 ai 框架,该框架能够生成一系列逼真的 npc 人物模型,并借助现有配音文件自动为人物模型“对口型”“摆动作”。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


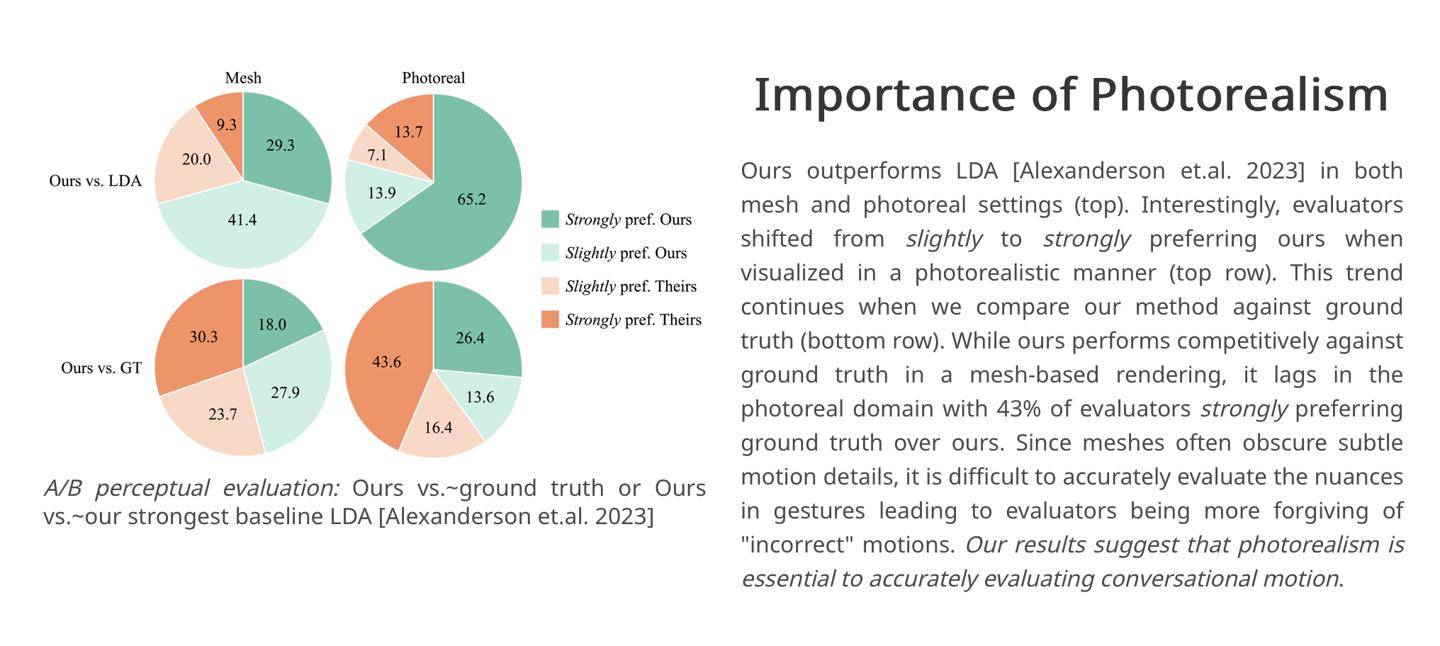
▲ 图源 Meta 研究报告(下同)
IT之家从官方研究报告中得知,Audio2photoreal 框架在接收到配音文件后,首先生成一系列 NPC 模型,之后利用量化技术及扩散算法生成模型用动作,其中量化技术为框架提供动作样本参考、扩散算法用于改善框架生成的人物动作效果。
研究人员提到,该框架可以生成 30 FPS 的“高质量动作样本”,还能模拟人类在对话中“手指点物”、“转手腕”或“耸肩”等不由自主的“习惯性动作”。

 冬瓜配音
冬瓜配音
AI在线配音生成器
 66 查看详情
66 查看详情 

研究人员援引自家实验结果,在对照实验中有 43% 的评估者对框架生成的人物对话场景感到“强烈满意”,因此研究人员认为 Audio2photoreal 框架相对于业界竞品能够生成“更具动态和表现力”的动作。
据悉,研究团队目前已经在 GitHub 公开了相关代码和数据集,感兴趣的小伙伴可以点此访问。
以上就是Meta 推出音频转图像 AI 框架,用于生成人物对话场景的配音的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/442751.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫