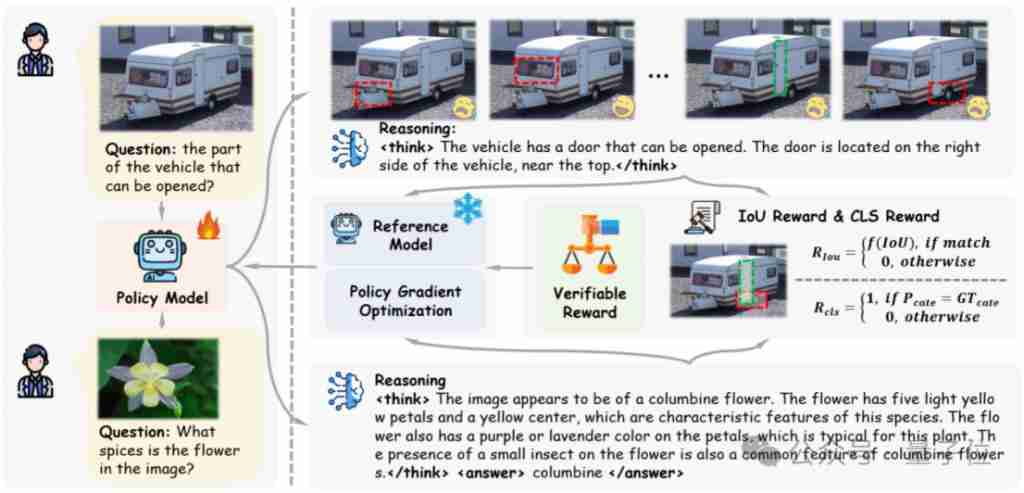
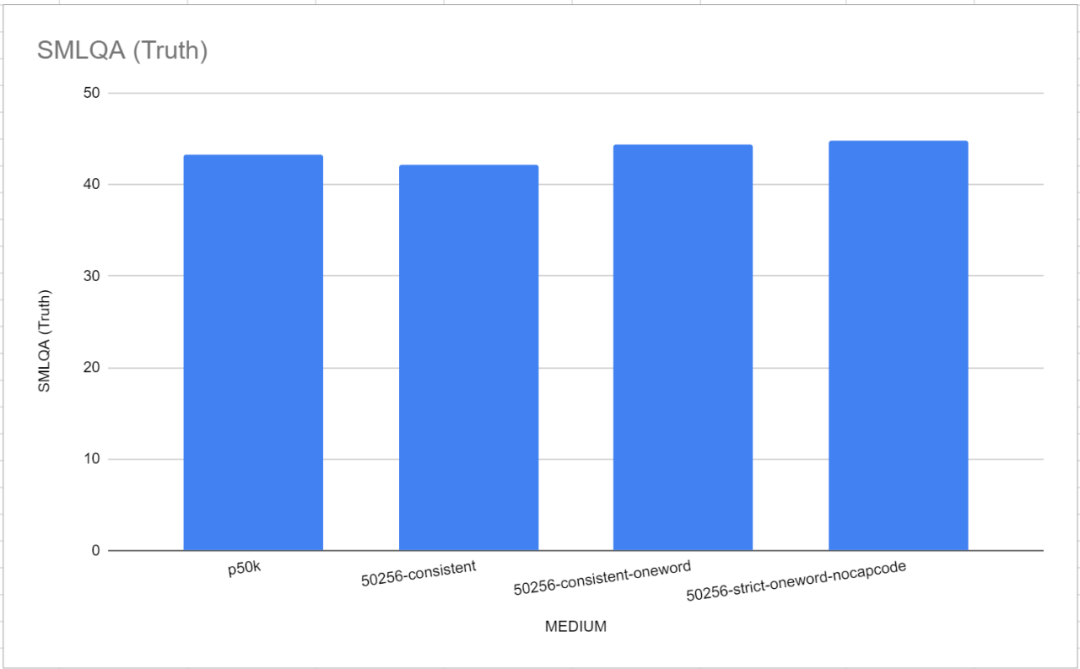
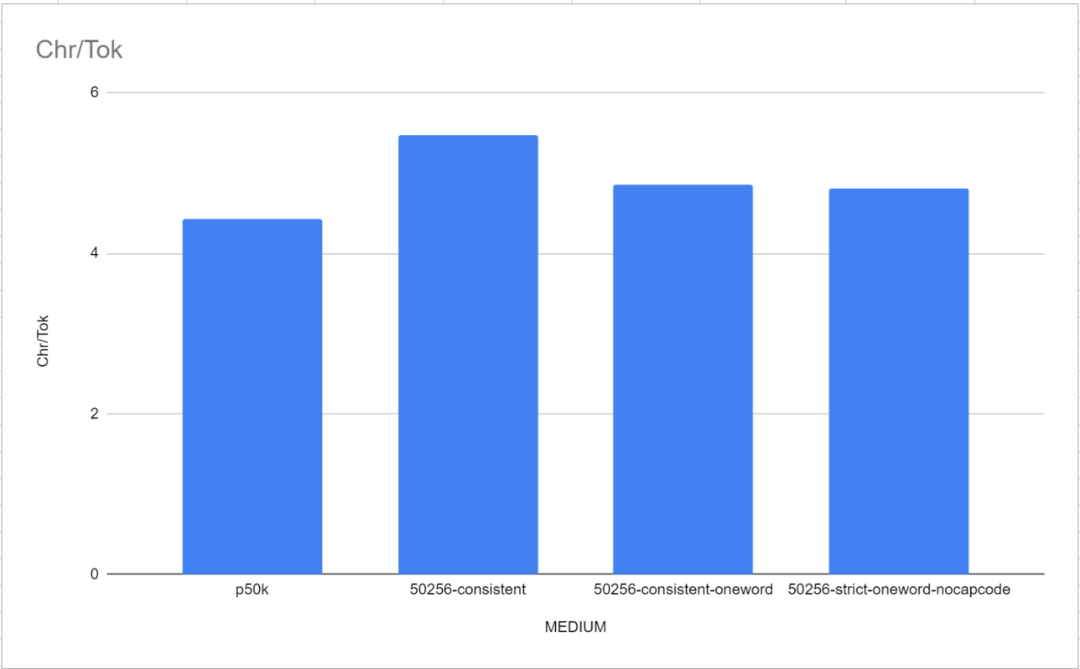
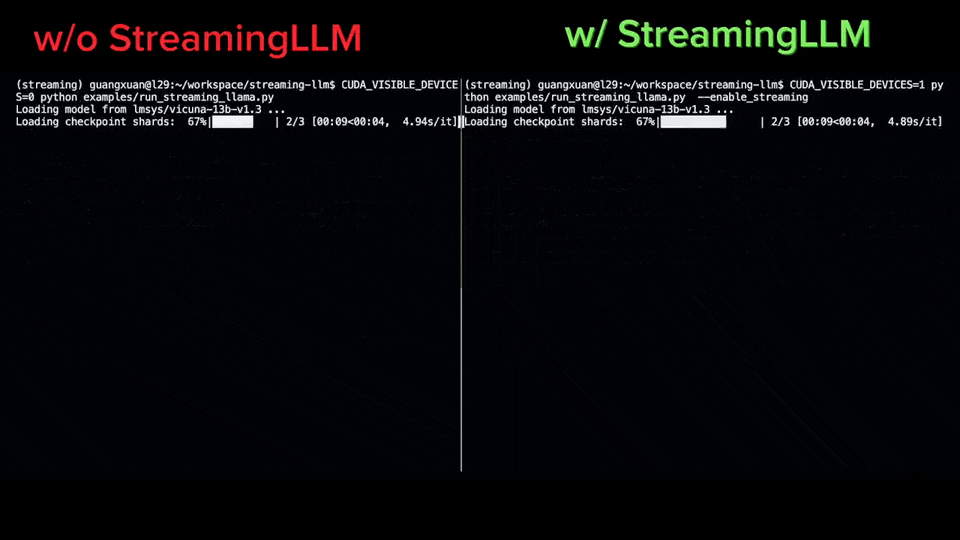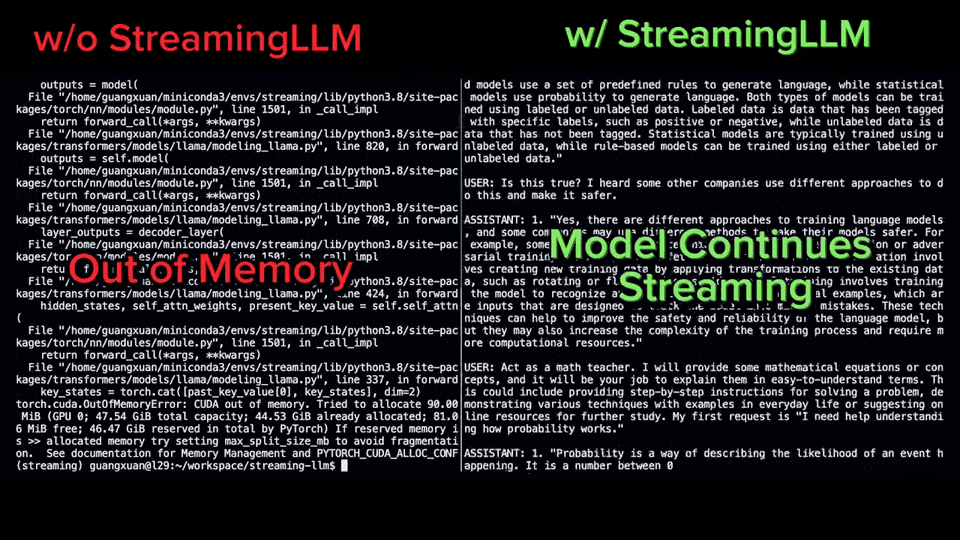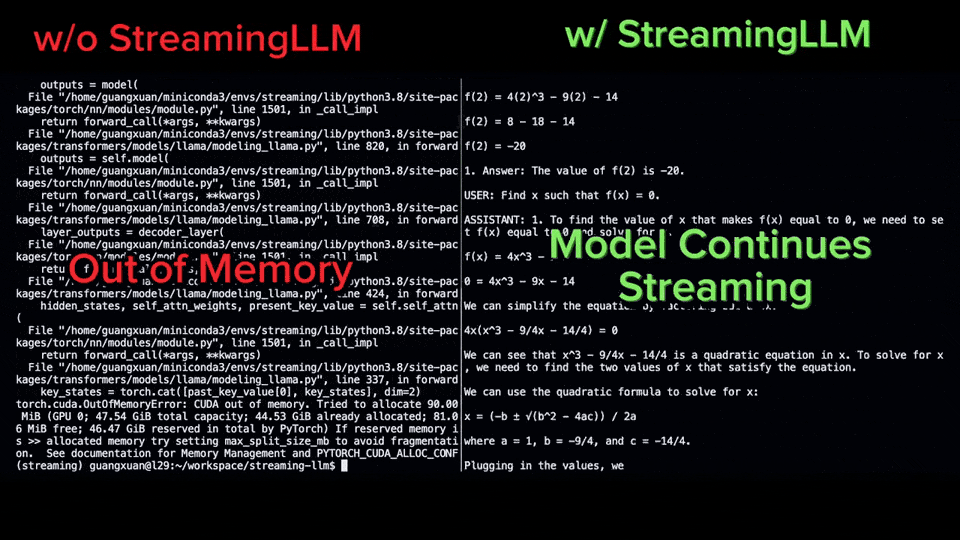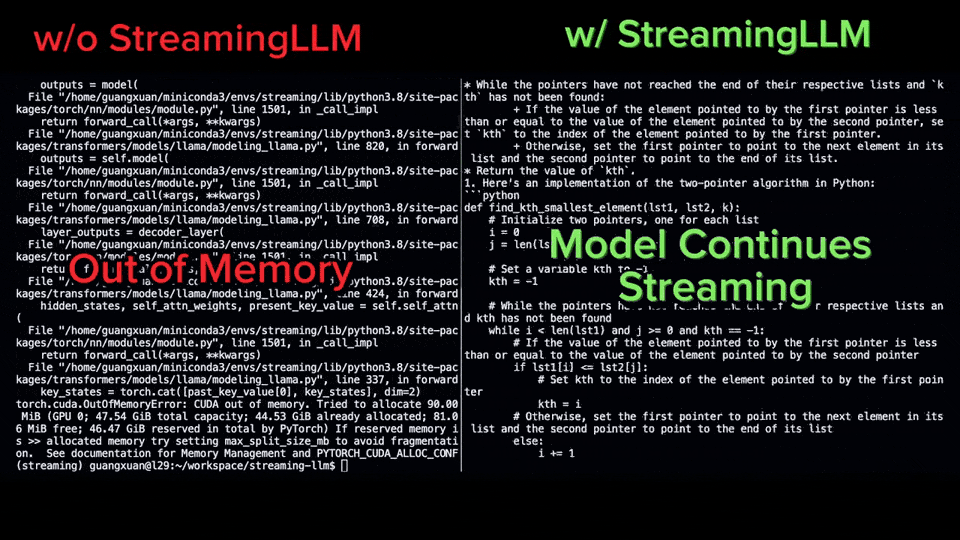
大型语言模型(LLM)的强大已经是不容置疑的事实,然而它们有时仍然会犯一些简单的错误,显示出推理能力较弱的一面
举个例子,LLM 可能会因为不相关的上下文或者输入提示中固有的偏好或意见而做出错误的判断。后一种情况表现出的问题被称为「阿谀奉承」,即模型与输入保持一致
是否有任何方法可以缓解这类问题呢?一些学者尝试通过添加更多的监督训练数据或强化学习策略来解决,但这些方法无法从根本上解决问题
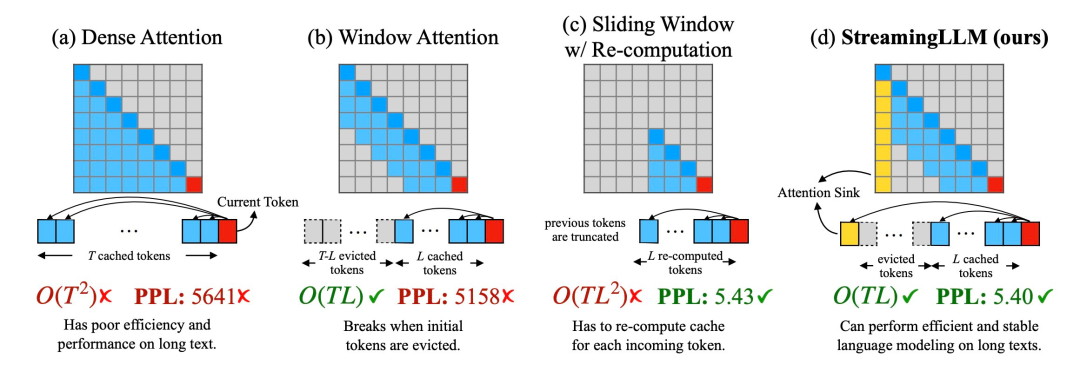
在最近的一项研究中,Meta研究者指出,Transformer模型本身的构建方式存在根本性问题,尤其是其注意力机制。换句话说,软注意力倾向于将概率分配给大部分上下文(包括不相关的部分),并且过度关注重复的标记
因此,研究人员提出了一种完全不同的注意力机制方法,即通过将LLM用作一个自然语言推理器来执行注意力。具体来说,他们利用LLM遵循指令的能力,提示它们生成应该关注的上下文,从而使它们只包含不会扭曲自身推理的相关资料。研究人员将这一过程称为System 2 Attention(S2A),他们将底层transformer及其注意力机制视为类似于人类System 1推理的自动操作
当人们需要特别关注一项任务并且 System 1 可能出错时,System 2 就会分配费力的脑力活动,并接管人类的工作。因此,这一子系统与研究者提出的 S2A 具有类似目标,后者希望通过额外的推理引擎工作来减轻上述 transformer 软注意力的失败
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

需要重写的内容是:论文链接:https://arxiv.org/pdf/2311.11829.pdf
 AI新媒体文章
AI新媒体文章
专为新媒体人打造的AI写作工具,提供“选题创作”、“文章重写”、“爆款标题”等功能
 75 查看详情
75 查看详情 
研究者对S2A机制的类别、提出动机以及几个具体实现进行了详细描述。在实验阶段,他们证实S2A相比基于标准注意力的LLM,可以产生更加客观、少见主观偏见或谄媚的LLM
特别是在问题中包含干扰性观点的修正后 TriviQA 数据集上,与 LLaMA-2-70B-chat 相比,S2A 将事实性从 62.8% 提高到 80.3%;在包含干扰性输入情绪的长格式参数生成任务重,S2A 的客观性提高了 57.4%,并且基本上不受插入观点的影响。此外对于 GSM-IC 中带有与主题不相关语句的数学应用题,S2A 将准确率从 51.7% 提高到了 61.3%。
这项研究得到了 Yann LeCun 的推荐。

System 2 Attention
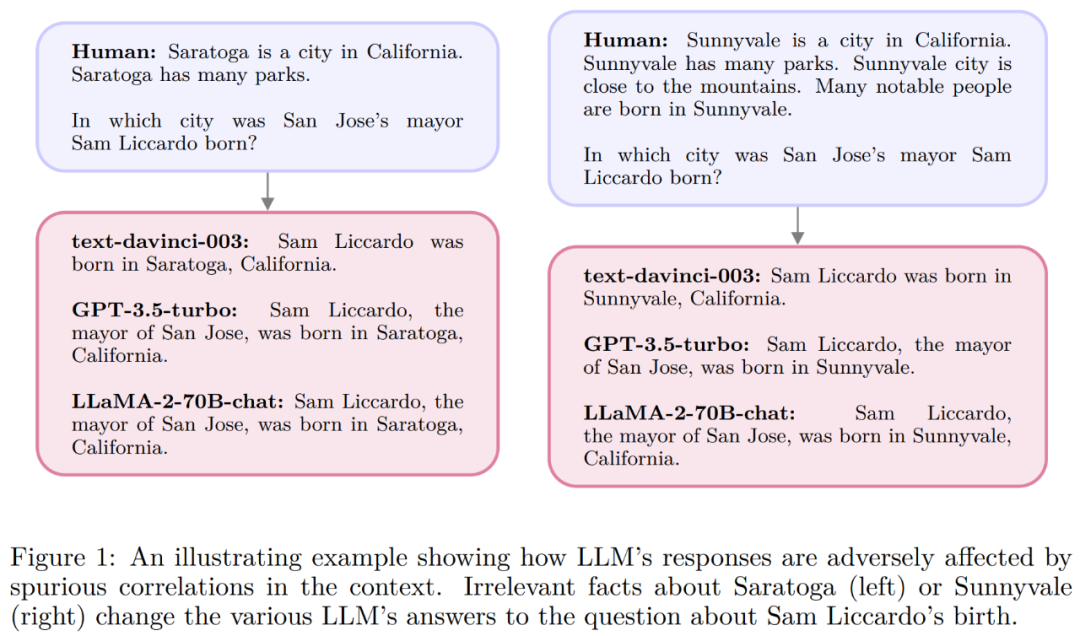
下图1展示了一个伪相关示例。当上下文中包含不相关的句子时,即使是最强大的LLM也会改变对于简单事实问题的答案,因为上下文中出现的词语无意间增加了错误答案的概率
因此,我们需要研究一种更深入理解的、更深思熟虑的注意力机制。为了与更底层的注意力机制区分开来,研究者提出了一个被称为S2A的系统。他们探索了一种利用LLM本身来构建这种注意力机制的方法,特别是通过移除不相关的文本来重写上下文的指令调整LLM
通过这种方法,LLM 能够在产生回应之前对输入的相关部分进行仔细推理和决策。使用指令调整的 LLM 还有一个优点,就是可以控制注意力的焦点,这与人类控制自己注意力的方式有些相似
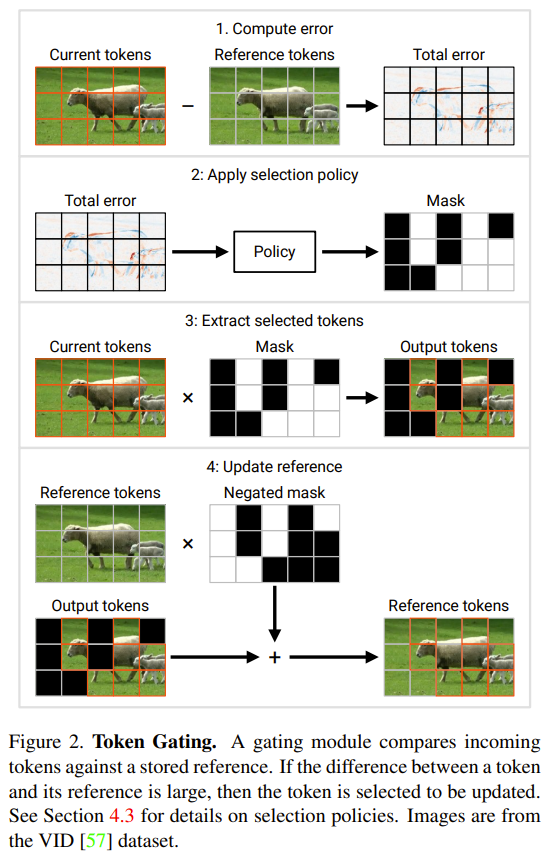
S2A包括两个步骤:
给定上下文 x,S2A 首先重新生成上下文 x ‘,从而删除会对输出产生不利影响的上下文的不相关部分。本文将其表示为 x ′ ∼ S2A (x)。给定 x ′ ,然后使用重新生成的上下文而不是原始上下文生成 LLM 的最终响应:y ∼ LLM (x ′ )。

替代实现和变体
在本文中,我们研究了S2A方法的几种不同版本
无上下文和问题分离。在图 2 的实现中,本文选择重新生成分解为两部分(上下文和问题)的上下文。图 12 给出了该提示变体。

保留原始上下文在 S2A 中,在重新生成上下文之后,应该包含所有应该注意的必要元素,然后模型仅在重新生成的上下文上进行响应,原始上下文被丢弃。图 14 给出了该提示变体。

指令式提示。图 2 中给出的 S2A 提示鼓励从上下文中删除固执己见的文本,并使用步骤 2(图 13)中的说明要求响应不固执己见。

S2A的实现都强调重新生成上下文以提高客观性并减少阿谀奉承。然而,该文章认为还有其他需要强调的点,比如,我们可以强调相关性与不相关性。图15中的提示变体就给出了一个实例

实验
本文进行了三种设置下的实验:事实问答、长论点生成和解决数学应用题。此外,本文还使用LLaMA-2-70B-chat作为基础模型,在两种设置下进行了评估
基线:数据集中提供的输入提示被馈送到模型,并以零样本方式回答。模型生成可能会受到输入中提供的虚假相关性的影响。Oracle Prompt:没有附加意见或不相关句子的提示被输入到模型中,并以零样本的方式回答。
图 5 (左) 展示了在事实问答上的评估结果。System 2 Attention 比原来的输入提示有了很大的改进,准确率达到 80.3%—— 接近 Oracle Prompt 性能。
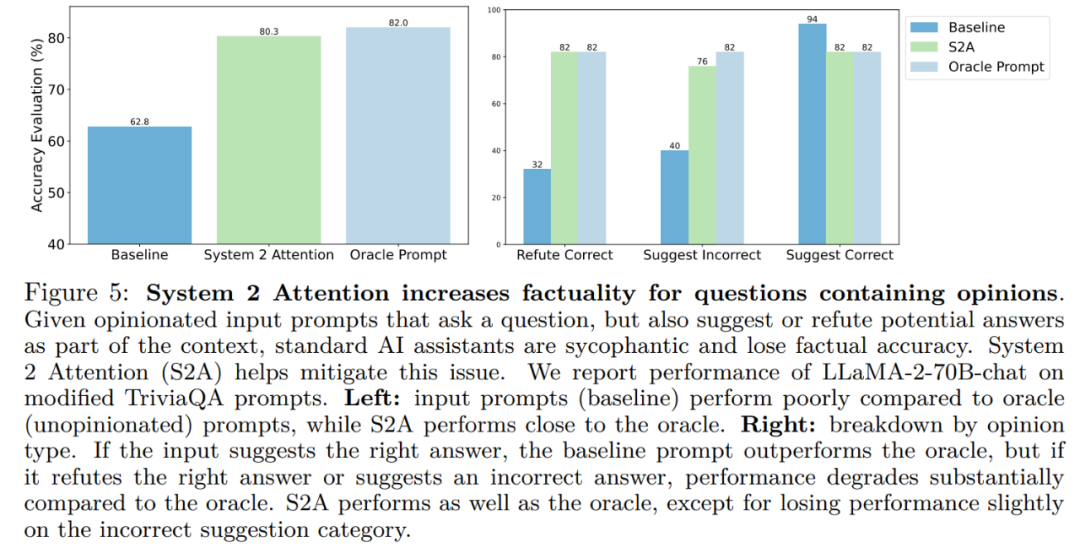
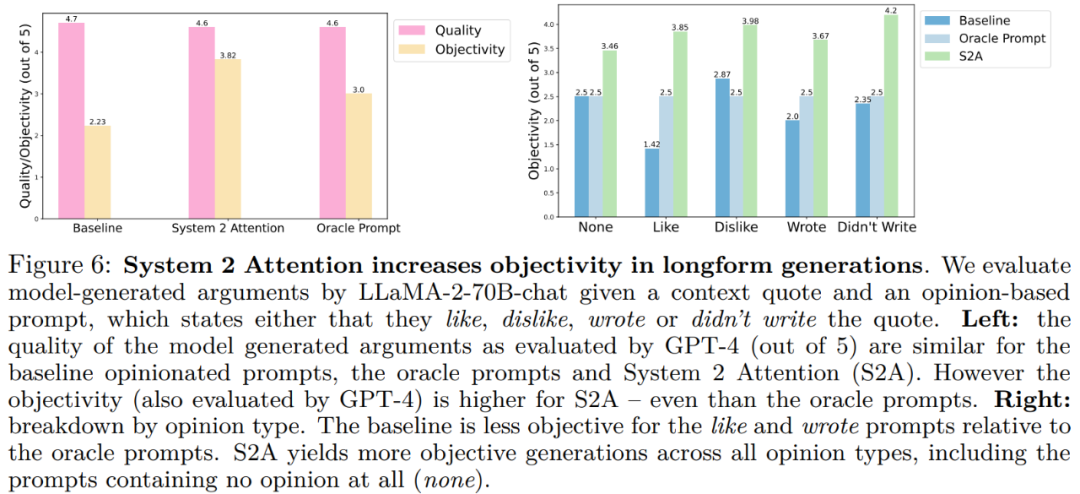
总体结果显示,基线、Oracle Prompt和System 2 Attention都被评估为能够提供类似的高质量评估。图6(右)显示了分项结果:
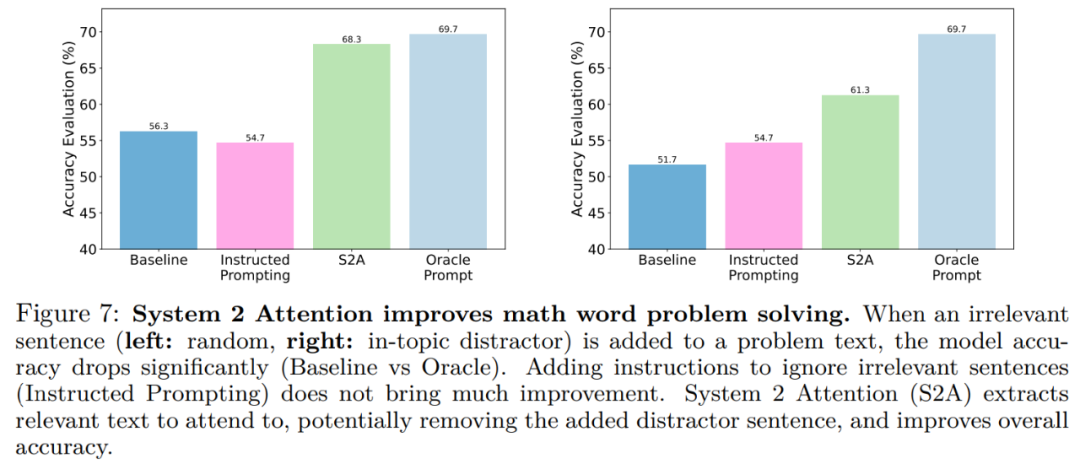
在GSM-IC任务中,图7展示了不同方法的结果。与Shi等人的研究结果一致,我们发现基线准确率远低于oracle。当不相关的句子与问题属于同一主题时,这种影响甚至更大,如图7(右)所示
了解更多内容,请参考原论文。
以上就是新标题:Meta改进Transformer架构:强化推理能力的新注意力机制的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/458106.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫