
训练
-
谷歌:非等频采样时间序列表示学习新方法
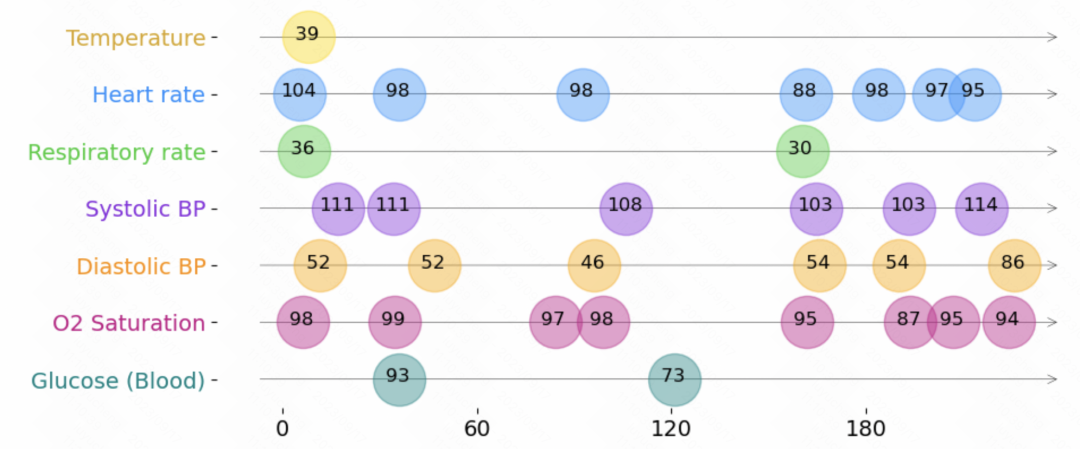
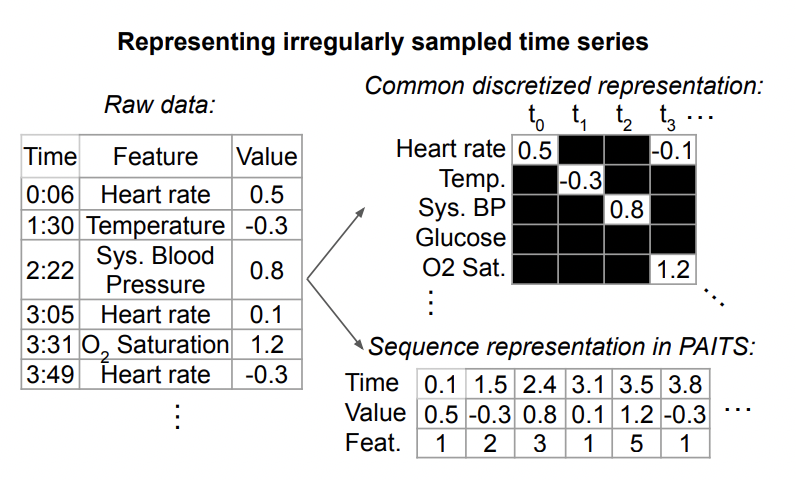
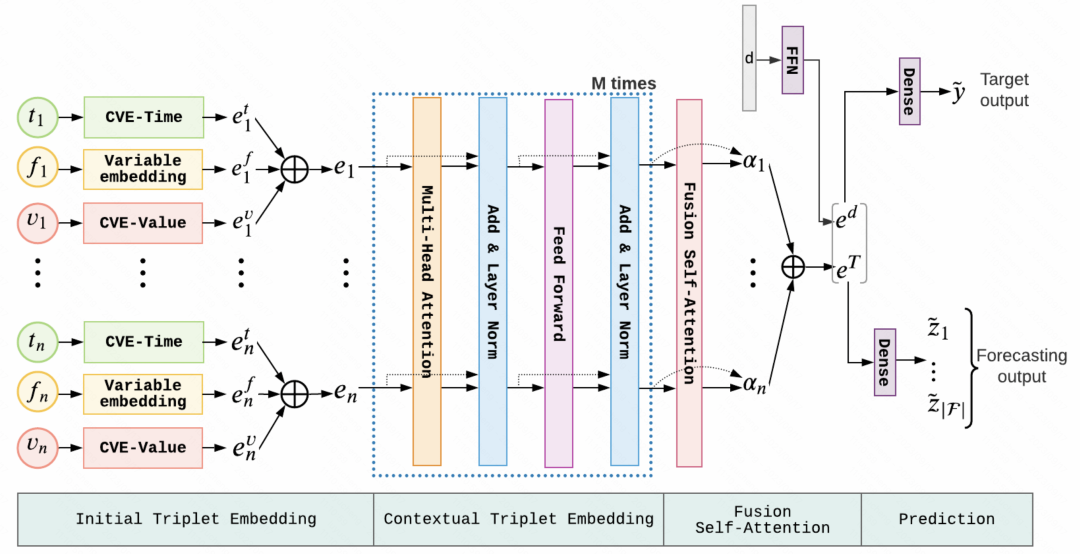

在时间序列问题中,有一种类型的时间序列不是等频采样的,即每组相邻两个观测值的时间间隔不一样。时间序列表示学习在等频采样的时间序列中已经进行了比较多的研究,但是在这种不规则采样的时间序列中研究比较少,并且这类时间序列的建模方式和等频采样中的建模方式有比较大的差别 今天介绍的这篇文章,在不规则采样的时间…
-
令人惊讶的时间冗余方法:降低视觉Transformer计算成本的新途径

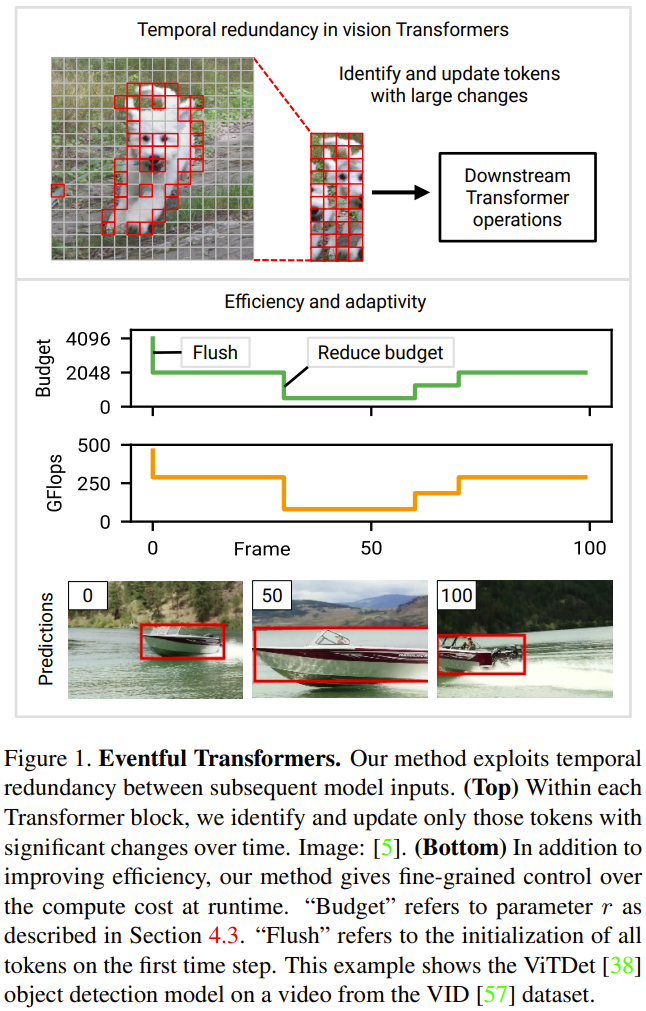
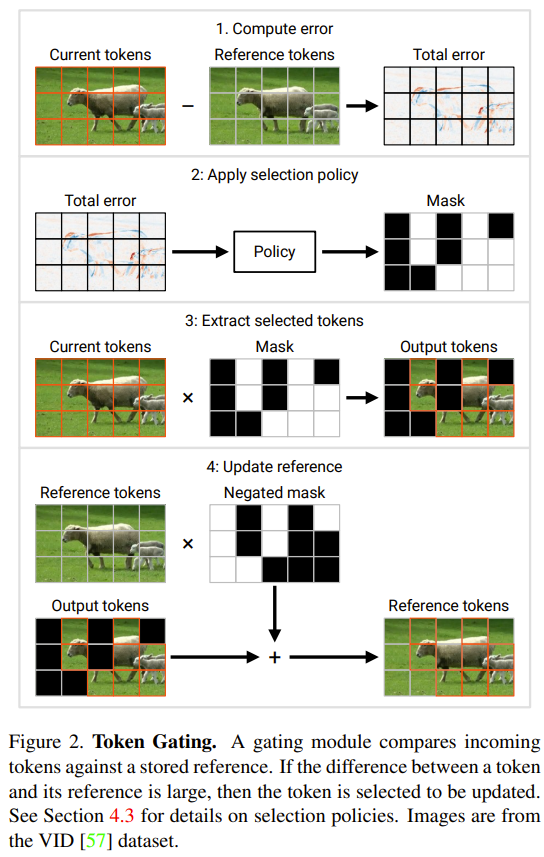
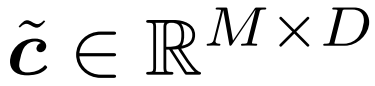
Transformer最初是为自然语言处理任务而设计的,但现在已经被广泛应用于视觉任务。视觉Transformer在多个视觉识别任务中展现出了出色的准确性,并在图像分类、视频分类和目标检测等任务中取得了当前最佳的表现 视觉 Transformer 的一大缺点是计算成本高。典型的卷积网络(CNN)处理…
-
BAT方法:AAAI 2024首个多模态目标追踪通用双向适配器




目标跟踪是计算机视觉的基础任务之一,近年来,单模态(RGB)目标跟踪取得了重大进展。然而,由于单一成像传感器的限制,我们需要引入多模态图像(如RGB、红外等)来弥补这一缺陷,以实现在复杂环境下的全天候目标跟踪。这种多模态图像的应用可以提供更全面的信息,增强目标检测和跟踪的准确性和鲁棒性。多模态目标跟…
-
微软6页论文爆火:三进制LLM,真香!

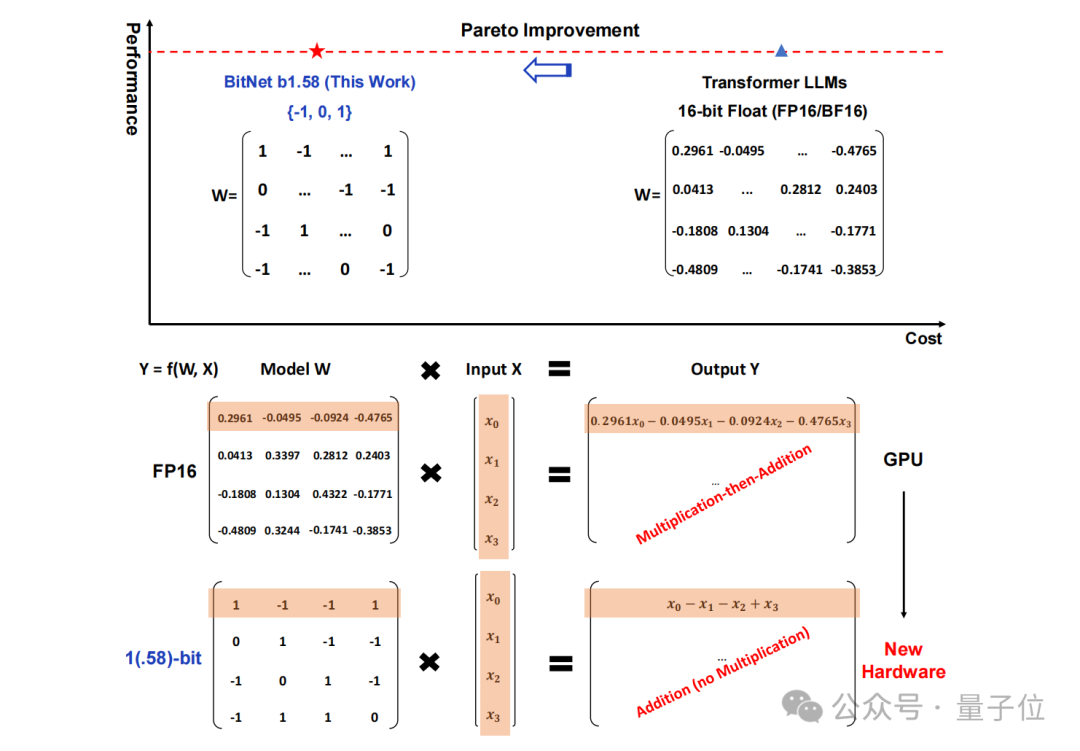
这就是由微软和中国中科院大学在最新一项研究中所提出的结论—— 所有的LLM,都将是1.58 bit的。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 具体而言,这项研究提出的方法叫做BitNet b1.58,可以说是从大语言模型“根儿”上的…
-
几行代码稳定UNet ! 中山大学等提出ScaleLong扩散模型:从质疑Scaling到成为Scaling
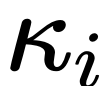
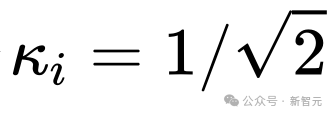
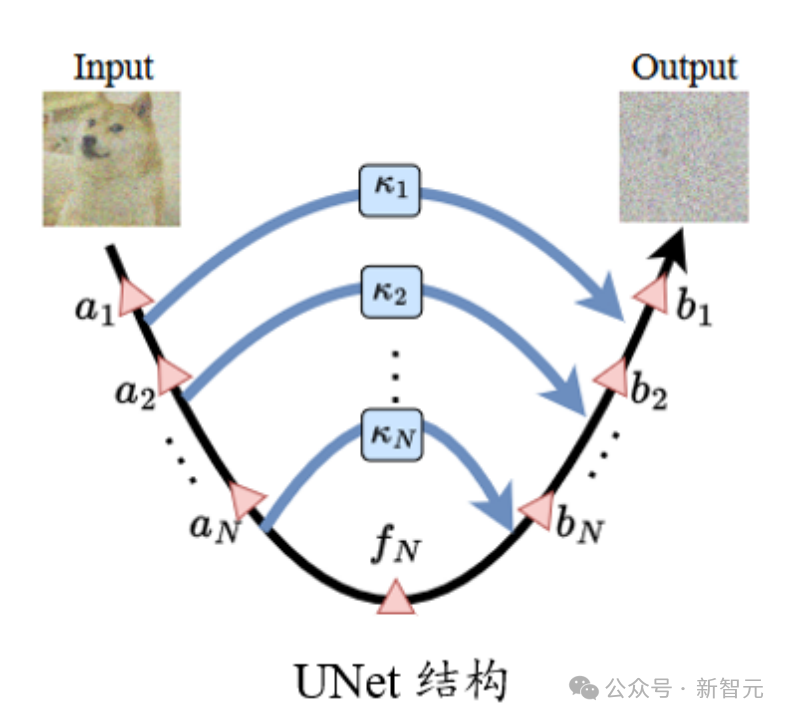
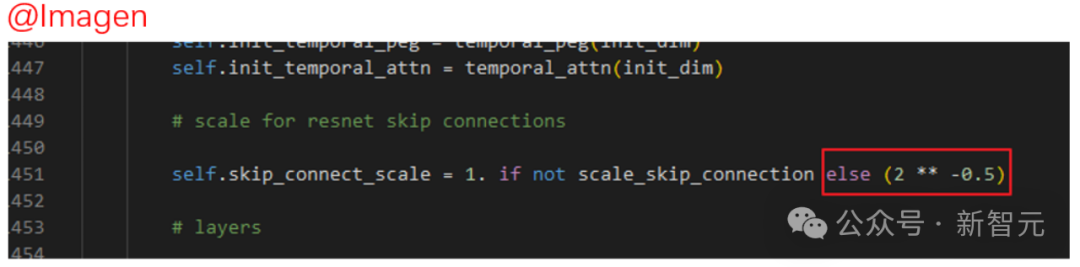
在标准的UNet结构中,long skip connection上的scaling系数 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 一般为1。 然而,在一些著名的扩散模型工作中,比如Imagen, Score-based generati…
-
陈丹琦团队新作:Llama-2上下文扩展至128k,10倍吞吐量仅需1/6内存
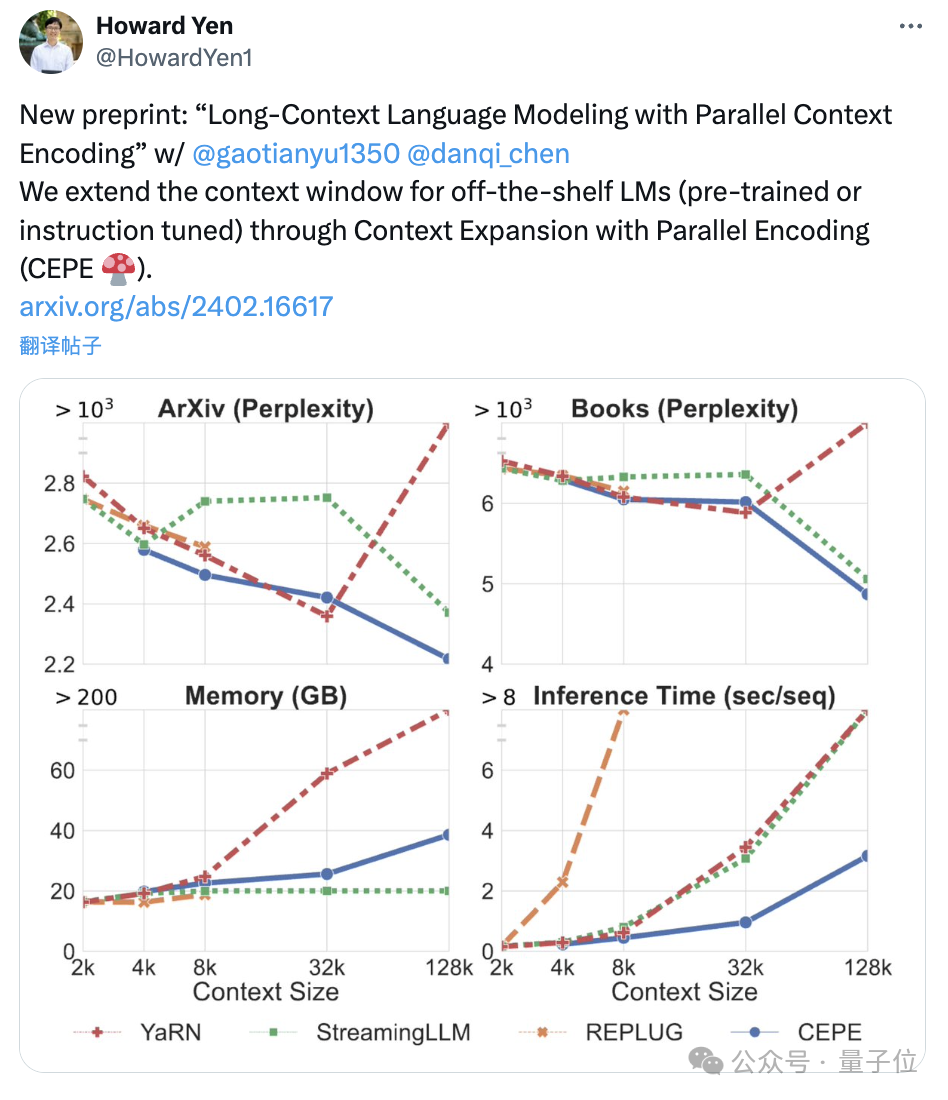


陈丹琦团队刚刚发布了一种新的llm上下文窗口扩展方法: 它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。 最重要的是,在这个过程中,只需要原来1/6的内存,模型就获得了10倍吞吐量。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSee…
-
ControlNet作者新作:AI绘画能分图层了!项目未开源就斩获660 Star




“绝不是简单的抠图。” ControlNet作者最新推出的一项研究受到了一波高度关注—— 给一句prompt,用Stable Diffusion可以直接生成单个或多个透明图层(PNG)! 例如来一句: 头发凌乱的女性,在卧室里。Woman with messy hair, in the bedroo…
-
Mamba超强进化体一举颠覆Transformer!单张A100跑140K上下文

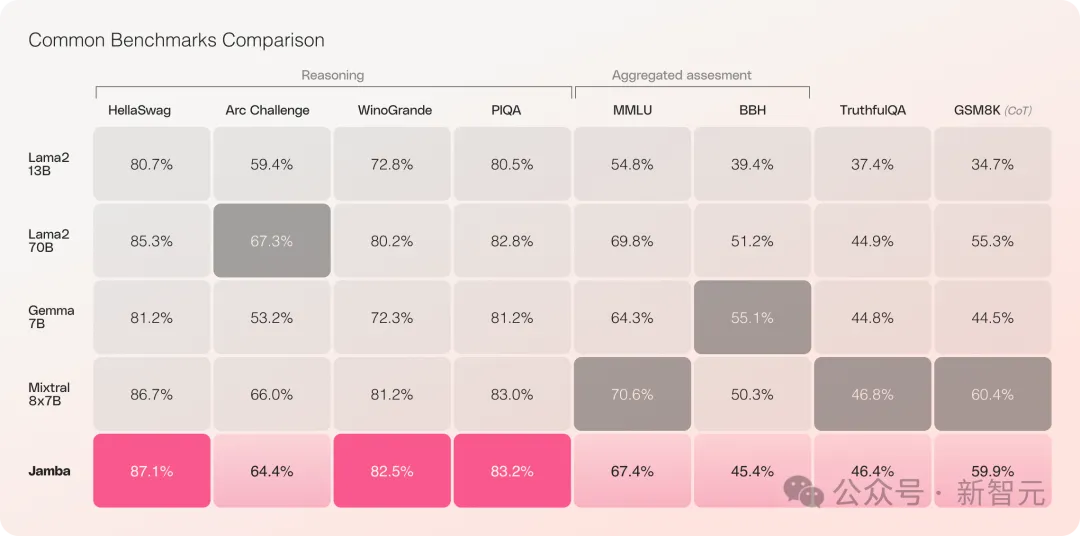

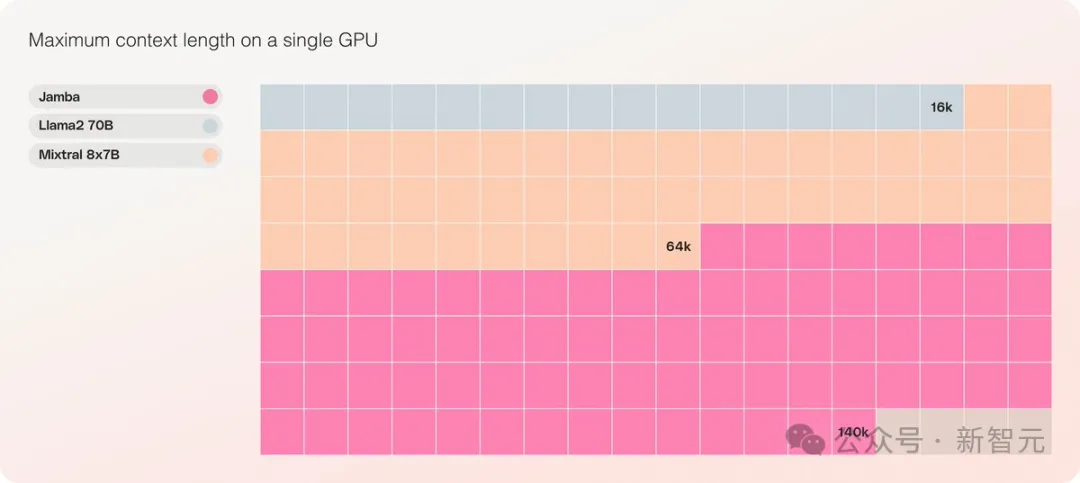
之前引爆了AI圈的Mamba架构,今天又推出了一版超强变体! 人工智能独角兽AI21 Labs刚刚开源了Jamba,世界上第一个生产级的Mamba大模型! ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ Jamba在多项基准测试中表现亮眼,与…
-
0门槛免费商用!孟子3-13B大模型正式开源,万亿token数据训练
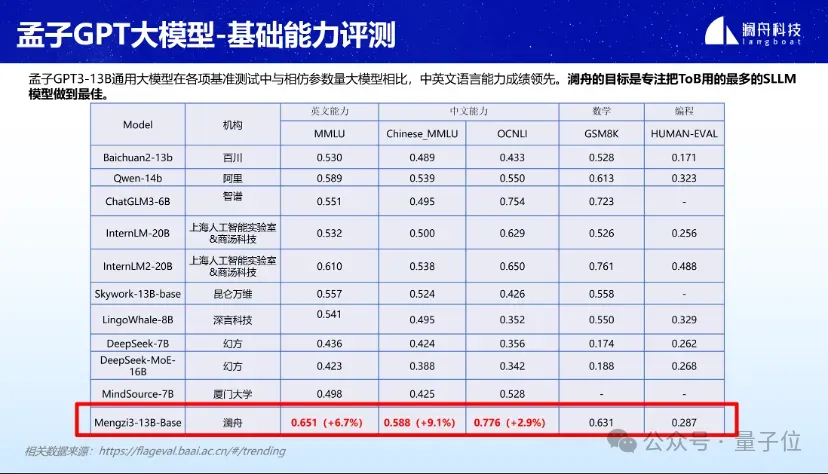

澜舟科技官宣:孟子3-13b大模型正式开源! 这一主打高性价比的轻量化大模型,面向学术研究完全开放,并支持免费商用。 在MMLU、GSM8K、HUMAN-EVAL等各项基准测评估中,孟子3-13B都表现出了不错的性能。 尤其在参量20B以内的轻量化大模型领域,中英文语言能力方面尤为突出。数学和编程能…
-
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键

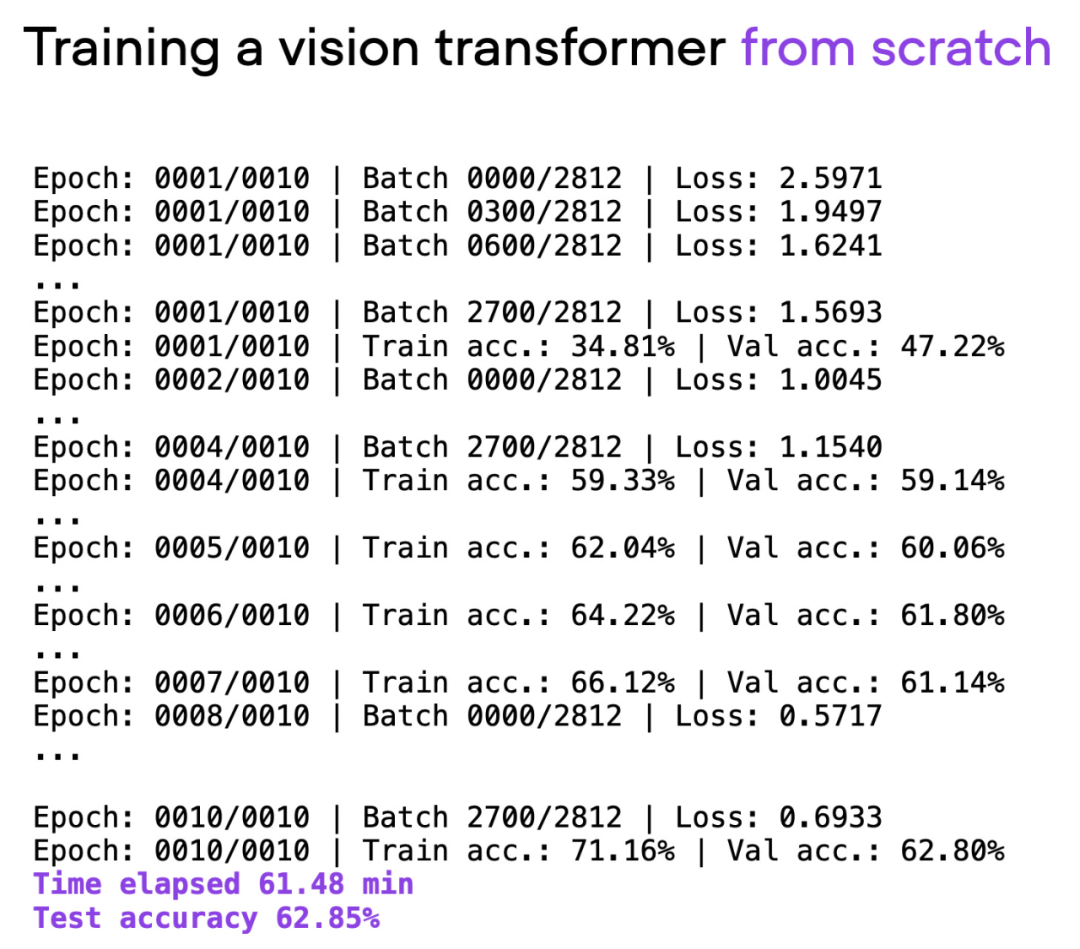
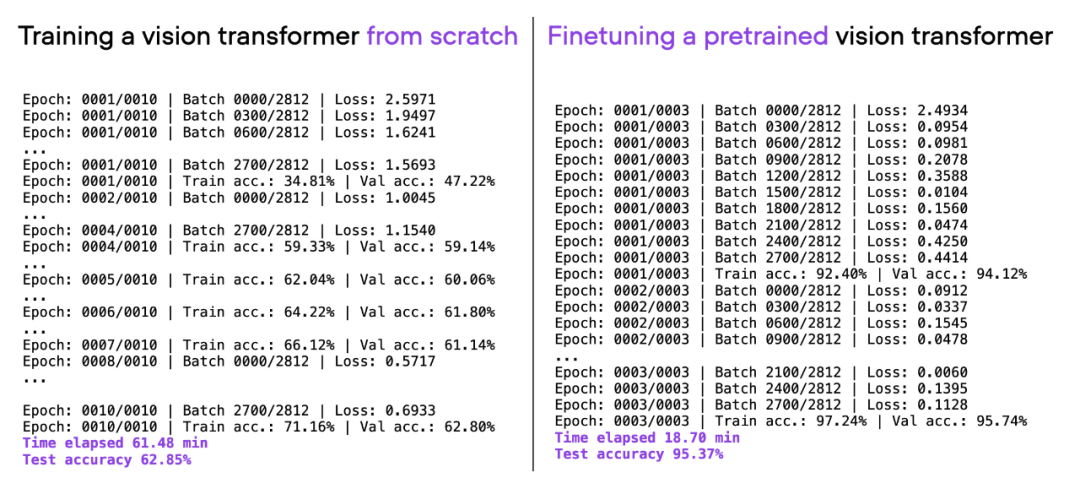
近日,深度学习领域知名研究者、lightning %ignore_a_1% 的首席人工智能教育者 sebastian raschka 在 cvpr 2023 上发表了主题演讲「scaling pytorch model training with minimal code changes」。 ☞☞☞…
