
本文基于Oxford-IIIT Pet数据集,用PaddleSeg实现猫咪一键抠图。提取猫数据集并重新制作标签(背景为0、图像为1),划分训练、测试、评估集后,配置FCN模型(HRNet骨干)训练,2100轮时mIoU达0.7874,导出静态模型并通过PaddleHub部署,可实现猫咪抠图,用于制作证件照等。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、 基于Oxford-IIIT Pet数据集实现PaddleHub猫咪一键抠图
1.主要工作
从Oxford-IIIT Pet宠物数据集提取cat据集重新制作label,背景设置为0,图像设置为1最终iter 2100时, mIoU =0.7874,仍有上升空间,只是耗时较长,不再训练通过paddlehub部署导出的静态模型
模型文件见当前目录 model.gz , paddlehub部署见 catseg_mobile.zip 。
最后就可以完美抠图了,可以制作猫猫证件照了。
2.PaddleSeg简介
PaddleSeg是基于飞桨PaddlePaddle开发的端到端图像分割开发套件,涵盖了高精度和轻量级等不同方向的大量高质量分割模型。通过模块化的设计,提供了配置化驱动和API调用两种应用方式,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用。
特性
高精度模型: 基于百度自研的半监督标签知识蒸馏方案(SSLD)训练得到高精度骨干网络,结合前沿的分割技术,提供了50+的高质量预训练模型,效果优于其他开源实现。模块化设计: 支持15+主流 分割网络 ,结合模块化设计的 数据增强策略 、骨干网络、损失函数 等不同组件,开发者可以基于实际应用场景出发,组装多样化的训练配置,满足不同性能和精度的要求。高性能: 支持多进程异步I/O、多卡并行训练、评估等加速策略,结合飞桨核心框架的显存优化功能,可大幅度减少分割模型的训练开销,让开发者更低成本、更高效地完成图像分割训练。In [ ]
! git clone https://gitee.com/paddlepaddle/PaddleSeg.git --depth=1
Cloning into 'PaddleSeg'...remote: Enumerating objects: 1589, done.remote: Counting objects: 100% (1589/1589), done.remote: Compressing objects: 100% (1354/1354), done.remote: Total 1589 (delta 309), reused 1117 (delta 142), pack-reused 0Receiving objects: 100% (1589/1589), 88.49 MiB | 5.57 MiB/s, done.Resolving deltas: 100% (309/309), done.Checking connectivity... done.
3.数据集制作
需要手动删除dataset/annotations/list.txt文件头,便于pandas读取,如麻烦,可以直接使用已制作好的数据集二,cat数据集。
In [1]
# 解压缩数据集!mkdir dataset!tar -xvf data/data50154/images.tar.gz -C dataset/!tar -xvf data/data50154/annotations.tar.gz -C dataset/
In [3]
# 查看list文件!head -n 10 dataset/annotations/list.txt
#Image CLASS-ID SPECIES BREED ID#ID: 1:37 Class ids#SPECIES: 1:Cat 2:Dog#BREED ID: 1-25:Cat 1:12:Dog#All images with 1st letter as captial are cat images#images with small first letter are dog imagesAbyssinian_100 1 1 1Abyssinian_101 1 1 1Abyssinian_102 1 1 1Abyssinian_103 1 1 1
In [13]
# 删除文件前6行描述头,方便pandas读取!sed -i '1,6d' dataset/annotations/list.txt
In [14]
!head dataset/annotations/list.txt
Abyssinian_100 1 1 1Abyssinian_101 1 1 1Abyssinian_102 1 1 1Abyssinian_103 1 1 1Abyssinian_104 1 1 1Abyssinian_105 1 1 1Abyssinian_106 1 1 1Abyssinian_107 1 1 1Abyssinian_108 1 1 1Abyssinian_109 1 1 1
In [ ]
import pandas as pdimport shutilimport os# Image CLASS-ID SPECIES BREED ID# ID: 1:37 Class ids# SPECIES: 1:Cat 2:Dog# BREED ID: 1-25:Cat 1:12:Dog# All images with 1st letter as captial are cat images# images with small first letter are dog images# ._Abyssinian_100.pngdef copyfile(animal, filename): # imagelabel列表 file_list = [] image_file = filename + '.jpg' label_file = filename + '.png' if os.path.exists(os.path.join('dataset/images', image_file)): shutil.copy(os.path.join('dataset/images', image_file), os.path.join(f'{animal}/images', image_file)) shutil.copy(os.path.join('dataset/annotations/trimaps', label_file), os.path.join(f'{animal}/labels', label_file)) temp = os.path.join('images/', image_file) + ' ' + os.path.join('labels/',label_file) + 'n' file_list.append(temp) with open(os.path.join(animal, animal + '.txt'), 'a') as f: f.writelines(file_list)if __name__ == "__main__": data = pd.read_csv('dataset/annotations/list.txt', header=None, sep=' ') data.head() cat = data[data[2] == 1] dog = data[data[2] == 2] for item in cat[0]: copyfile('cat', item) for item in dog[0]: copyfile('dog', item)
In [ ]
# 删除无用数据!rm dataset/ -rf
4.训练自定义的数据集
4.1文件结构
├── cat.txt├── images│ ├── Abyssinian_100.jpg│ ├── Abyssinian_101.jpg│ ├── ...├── labels│ ├── Abyssinian_100.png│ ├── Abyssinian_101.png│ ├── ...
4.2 列表内容:
images/Abyssinian_1.jpg labels/Abyssinian_1.pngimages/Abyssinian_10.jpg labels/Abyssinian_10.pngimages/Abyssinian_100.jpg labels/Abyssinian_100.png...
4.3.数据查看
In [3]
%cd ~from PIL import Imageimg=Image.open('cat/images/Abyssinian_123.jpg')print(img)img
/home/aistudio
In [5]
img=Image.open('cat/labels/Abyssinian_123.png')print(img)img
5.标签处理
标签是从0开始排序,本项目的数据提取自Oxford-IIIT Pet https://www.robots.ox.ac.uk/~vgg/data/pets 宠物数据集,该数据集是从1开始编码,所以需要重新编码。背景设置为0,图像设置为1.
In [ ]
# 执行一次即可import pandas as pdimport osimport matplotlib.pyplot as pltimport numpy as npfrom PIL import Imagedef re_label(filename): img = plt.imread(filename) * 255.0 img_label = np.zeros((img.shape[0], img.shape[1]), np.uint8) for i in range(img.shape[0]): for j in range(img.shape[1]): value = img[i, j] if value == 2: img_label[i, j] = 1 label0 = Image.fromarray(np.uint8(img_label)) label0.save( filename)data=pd.read_csv("cat/cat.txt", header=None, sep=' ') for item in data[1]: re_label(os.path.join('cat', item))print('处理完毕!')
处理完毕!
二、数据集预处理
In [ ]
import osfrom sklearn.model_selection import train_test_splitimport pandas as pddef break_data(target, rate=0.2): origin_dataset = pd.read_csv("cat/cat.txt", header=None, sep=' ') # 加入参数 train_data, test_data = train_test_split(origin_dataset, test_size=rate) train_data,eval_data=train_test_split(train_data, test_size=rate) train_filename = os.path.join(target, 'train.txt') test_filename = os.path.join(target, 'test.txt') eval_filename = os.path.join(target, 'eval.txt') train_data.to_csv(train_filename, index=False, sep=' ', header=None) test_data.to_csv(test_filename, index=False, sep=' ', header=None) eval_data.to_csv(eval_filename, index=False, sep=' ', header=None) print('train_data:',len(train_data)) print('test_data:',len(test_data)) print('eval_data:',len(eval_data))if __name__ == '__main__': break_data(target='cat', rate=0.2)
train_data: 1516test_data: 475eval_data: 380
In [ ]
# 查看!head cat/train.txt
images/Bengal_173.jpg labels/Bengal_173.pngimages/Siamese_179.jpg labels/Siamese_179.pngimages/British_Shorthair_201.jpg labels/British_Shorthair_201.pngimages/Russian_Blue_60.jpg labels/Russian_Blue_60.pngimages/British_Shorthair_93.jpg labels/British_Shorthair_93.pngimages/British_Shorthair_26.jpg labels/British_Shorthair_26.pngimages/British_Shorthair_209.jpg labels/British_Shorthair_209.pngimages/British_Shorthair_101.jpg labels/British_Shorthair_101.pngimages/British_Shorthair_269.jpg labels/British_Shorthair_269.pngimages/Ragdoll_59.jpg labels/Ragdoll_59.png
三、配置
In [ ]
# 已配置好,可以不用复制了# !cp PaddleSeg/configs/quick_start/bisenet_optic_disc_512x512_1k.yml ~/bisenet_optic_disc_512x512_1k.yml
修改 bisenet_optic_disc_512x512_1k.yml,要注意一下几点:
1.数据集路径配置2.num_classes设置,背景不算3.transforms设置4.loss设置
batch_size: 600iters: 5000train_dataset: type: Dataset dataset_root: /home/aistudio/cat/ train_path: /home/aistudio/cat/train.txt num_classes: 2 transforms: - type: ResizeStepScaling min_scale_factor: 0.5 max_scale_factor: 2.0 scale_step_size: 0.25 - type: RandomPaddingCrop crop_size: [224, 224] - type: RandomHorizontalFlip - type: RandomDistort brightness_range: 0.4 contrast_range: 0.4 saturation_range: 0.4 - type: Normalize mode: trainval_dataset: type: Dataset dataset_root: /home/aistudio/cat/ val_path: /home/aistudio/cat/eval.txt num_classes: 2 transforms: - type: Normalize mode: valoptimizer: type: sgd momentum: 0.9 weight_decay: 0.0005lr_scheduler: type: PolynomialDecay learning_rate: 0.05 end_lr: 0 power: 0.9loss: types: - type: CrossEntropyLoss coef: [1]model: type: FCN backbone: type: HRNet_W18_Small_V1 align_corners: False num_classes: 2 pretrained: Null
四、训练
In [1]
%cd ~/PaddleSeg/! python train.py --config ../bisenet_optic_disc_512x512_1k.yml --do_eval --use_vdl --save_interval 100 --save_dir output
2021-11-13 19:30:52 [INFO][TRAIN] epoch: 1105, iter: 2210/5000, loss: 0.1849, lr: 0.029586, batch_cost: 8.8180, reader_cost: 7.73956, ips: 68.0427 samples/sec | ETA 06:50:022021-11-13 19:32:18 [INFO][TRAIN] epoch: 1110, iter: 2220/5000, loss: 0.1768, lr: 0.029490, batch_cost: 8.6004, reader_cost: 7.52235, ips: 69.7641 samples/sec | ETA 06:38:292021-11-13 19:33:47 [INFO][TRAIN] epoch: 1115, iter: 2230/5000, loss: 0.1791, lr: 0.029395, batch_cost: 8.8851, reader_cost: 7.80702, ips: 67.5288 samples/sec | ETA 06:50:112021-11-13 19:35:14 [INFO][TRAIN] epoch: 1120, iter: 2240/5000, loss: 0.1835, lr: 0.029299, batch_cost: 8.6699, reader_cost: 7.59314, ips: 69.2053 samples/sec | ETA 06:38:482021-11-13 19:36:41 [INFO][TRAIN] epoch: 1125, iter: 2250/5000, loss: 0.1815, lr: 0.029204, batch_cost: 8.7713, reader_cost: 7.68169, ips: 68.4051 samples/sec | ETA 06:42:002021-11-13 19:38:08 [INFO][TRAIN] epoch: 1130, iter: 2260/5000, loss: 0.1833, lr: 0.029108, batch_cost: 8.7045, reader_cost: 7.62504, ips: 68.9299 samples/sec | ETA 06:37:302021-11-13 19:39:35 [INFO][TRAIN] epoch: 1135, iter: 2270/5000, loss: 0.1741, lr: 0.029013, batch_cost: 8.7032, reader_cost: 7.61708, ips: 68.9401 samples/sec | ETA 06:35:592021-11-13 19:41:03 [INFO][TRAIN] epoch: 1140, iter: 2280/5000, loss: 0.1810, lr: 0.028917, batch_cost: 8.8020, reader_cost: 7.72264, ips: 68.1664 samples/sec | ETA 06:39:012021-11-13 19:42:33 [INFO][TRAIN] epoch: 1145, iter: 2290/5000, loss: 0.1799, lr: 0.028821, batch_cost: 8.9336, reader_cost: 7.84692, ips: 67.1623 samples/sec | ETA 06:43:302021-11-13 19:44:02 [INFO][TRAIN] epoch: 1150, iter: 2300/5000, loss: 0.1756, lr: 0.028726, batch_cost: 8.9216, reader_cost: 7.84517, ips: 67.2524 samples/sec | ETA 06:41:282021-11-13 19:44:02 [INFO]Start evaluating (total_samples: 380, total_iters: 380)...380/380 [==============================] - 15s 40ms/step - batch_cost: 0.0394 - reader cost: 0.0012021-11-13 19:44:17 [INFO][EVAL] #Images: 380 mIoU: 0.7640 Acc: 0.8681 Kappa: 0.7330 2021-11-13 19:44:17 [INFO][EVAL] Class IoU: [0.7378 0.7902]2021-11-13 19:44:17 [INFO][EVAL] Class Acc: [0.7925 0.9347]2021-11-13 19:44:17 [INFO][EVAL] The model with the best validation mIoU (0.7874) was saved at iter 2100.
五、测试
In [2]
!python val.py --config /home/aistudio/bisenet_optic_disc_512x512_1k.yml --model_path output/best_model/model.pdparams
2021-11-13 19:48:13 [INFO]---------------Config Information---------------batch_size: 600iters: 5000loss: coef: - 1 types: - type: CrossEntropyLosslr_scheduler: end_lr: 0 learning_rate: 0.05 power: 0.9 type: PolynomialDecaymodel: backbone: align_corners: false type: HRNet_W18_Small_V1 num_classes: 2 pretrained: null type: FCNoptimizer: momentum: 0.9 type: sgd weight_decay: 0.0005train_dataset: dataset_root: /home/aistudio/cat/ mode: train num_classes: 2 train_path: /home/aistudio/cat/train.txt transforms: - max_scale_factor: 2.0 min_scale_factor: 0.5 scale_step_size: 0.25 type: ResizeStepScaling - crop_size: - 224 - 224 type: RandomPaddingCrop - type: RandomHorizontalFlip - brightness_range: 0.4 contrast_range: 0.4 saturation_range: 0.4 type: RandomDistort - type: Normalize type: Datasetval_dataset: dataset_root: /home/aistudio/cat/ mode: val num_classes: 2 transforms: - type: Normalize type: Dataset val_path: /home/aistudio/cat/eval.txt------------------------------------------------W1113 19:48:13.707370 4265 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1W1113 19:48:13.707428 4265 device_context.cc:422] device: 0, cuDNN Version: 7.6.2021-11-13 19:48:19 [INFO]Loading pretrained model from output/best_model/model.pdparams2021-11-13 19:48:19 [INFO]There are 363/363 variables loaded into FCN.2021-11-13 19:48:19 [INFO]Loaded trained params of model successfully2021-11-13 19:48:19 [INFO]Start evaluating (total_samples: 380, total_iters: 380).../opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:239: UserWarning: The dtype of left and right variables are not the same, left dtype is paddle.int32, but right dtype is paddle.bool, the right dtype will convert to paddle.int32 format(lhs_dtype, rhs_dtype, lhs_dtype))/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:239: UserWarning: The dtype of left and right variables are not the same, left dtype is paddle.int64, but right dtype is paddle.bool, the right dtype will convert to paddle.int64 format(lhs_dtype, rhs_dtype, lhs_dtype))380/380 [==============================] - 15s 41ms/step - batch_cost: 0.0405 - reader cost: 0.002021-11-13 19:48:35 [INFO][EVAL] #Images: 380 mIoU: 0.7874 Acc: 0.8838 Kappa: 0.7616 2021-11-13 19:48:35 [INFO][EVAL] Class IoU: [0.7566 0.8181]2021-11-13 19:48:35 [INFO][EVAL] Class Acc: [0.8349 0.9211]
380/380 [==============================] - 15s 41ms/step - batch_cost: 0.0405 - reader cost: 0.002021-11-13 19:48:35 [INFO][EVAL] #Images: 380 mIoU: 0.7874 Acc: 0.8838 Kappa: 0.7616 2021-11-13 19:48:35 [INFO][EVAL] Class IoU: [0.7566 0.8181]2021-11-13 19:48:35 [INFO][EVAL] Class Acc: [0.8349 0.9211]
六、导出静态模型
In [3]
!python export.py --config /home/aistudio/bisenet_optic_disc_512x512_1k.yml --model_path output/best_model/model.pdparams
op_type, op_type, EXPRESSION_MAP[method_name]))/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:322: UserWarning: /tmp/tmp_l3u6xjv.py:58The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name]))2021-11-03 01:01:11 [INFO]Model is saved in ./output.
七、预测
deploy.yaml
Deploy: model: model.pdmodel params: model.pdiparams transforms: - type: Normalize
In [3]
# 安装paddleseg!pip install -e .
In [5]
# 预测%cd ~/PaddleSeg/!python deploy/python/infer.py --config output/deploy.yaml --image_path /home/aistudio/cat/images/Bombay_130.jpg
/home/aistudio/PaddleSeg
In [6]
# 打印原图from PIL import Imageimg=Image.open('/home/aistudio/cat/images/Bombay_130.jpg')img
In [7]
# 打印输出图,颜色可调from PIL import Imageimg=Image.open('/home/aistudio/PaddleSeg/output/Bombay_130.png')img
八、hub部署
hub部署可参考:PaddleHub Module转换
已用hub部署,可通过命令行或者python来抠图啦!,具体hub文件见目录压缩包catseg_mobile.zip
hub run catseg_mobile --input_path .cat1.jpg
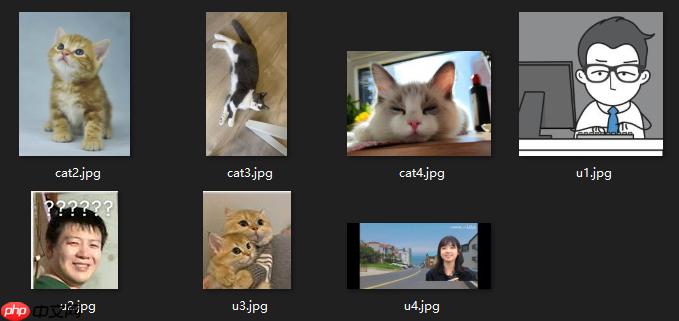
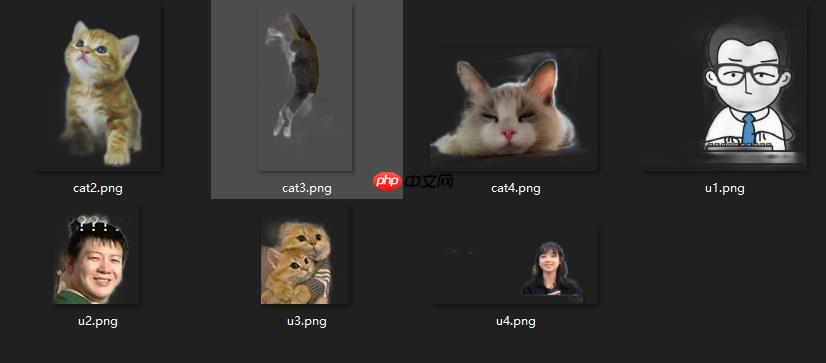
In [ ]
以上就是基于Oxford-IIIT Pet数据集实现PaddleHub猫咪一键抠图的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/47049.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















