
let’s delve into the apache spark architecture, providing a high-level overview and discussing some key software components in detail.
High-Level OverviewApache Spark’s application architecture is composed of several crucial components that work together to process data in a distributed environment. Understanding these components is essential for grasping how Spark functions. The key components include:
Driver ProgramMaster NodeWorker NodeExecutorTasksSparkContextSQL ContextSpark Session
Here’s an overview of how these components integrate within the overall architecture:
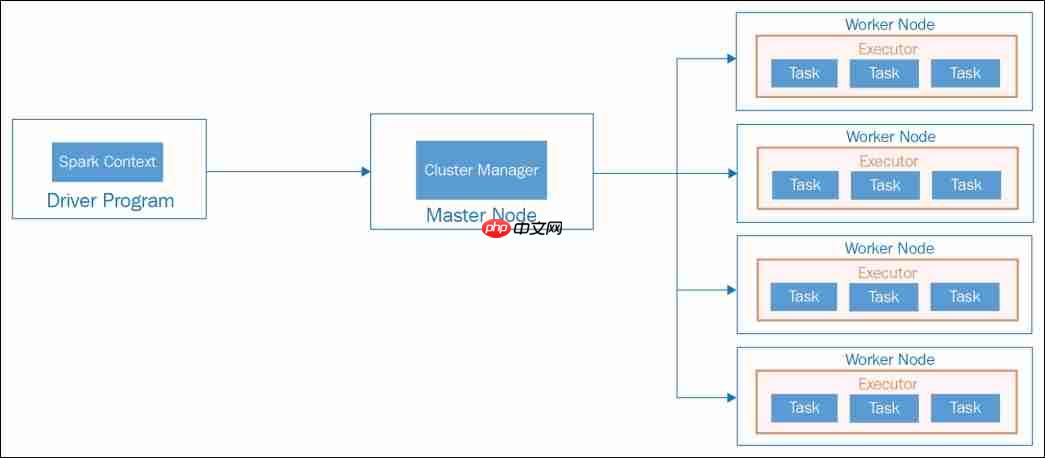 Apache Spark application architecture – Standalone mode
Apache Spark application architecture – Standalone mode
Driver ProgramThe Driver Program serves as the primary component of a Spark application. The machine hosting the Spark application process, which initializes SparkContext and Spark Session, is referred to as the Driver Node, and the running process is known as the Driver Process. This program interacts with the Cluster Manager to allocate tasks to executors.
Cluster ManagerAs the name suggests, a Cluster Manager oversees a cluster. Spark is compatible with various cluster managers such as YARN, Mesos, and a Standalone cluster manager. In a standalone setup, there are two continuously running daemons: one on the master node and one on each worker node. Further details on cluster managers and deployment models will be covered in Chapter 8, Operating in Clustered Mode.
WorkerIf you’re familiar with Hadoop, you’ll recognize that a Worker Node is akin to a slave node. These nodes are where the actual computational work occurs within Spark executors. They report their available resources back to the master node. Typically, each node in a Spark cluster, except the master, runs a worker process. Usually, one Spark worker daemon is initiated per worker node, which then launches and oversees executors for the applications.
ExecutorsThe master node allocates resources and utilizes workers across the cluster to instantiate Executors for the driver. These executors are employed by the driver to execute tasks. Executors are initiated only when a job begins on a worker node. Each application maintains its own set of executor processes, which can remain active throughout the application’s lifecycle and execute tasks across multiple threads. This approach ensures application isolation and prevents data sharing between different applications. Executors are responsible for task execution and managing data in memory or on disk.
TasksA task represents a unit of work dispatched to an executor. It is essentially a command sent from the Driver Program to an executor, serialized as a Function object. The executor deserializes this command (which is part of your previously loaded JAR) and executes it on a specific data partition.
A partition is a logical division of data spread across a Spark cluster. Spark typically reads data from a distributed storage system and partitions it to facilitate parallel processing across the cluster. For instance, when reading from HDFS, a partition is created for each HDFS partition. Partitions are crucial because Spark executes one task per partition. Consequently, the number of partitions is significant. Spark automatically sets the number of partitions unless manually specified, e.g., sc.parallelize(data, numPartitions).
 即构数智人
即构数智人
即构数智人是由即构科技推出的AI虚拟数字人视频创作平台,支持数字人形象定制、短视频创作、数字人直播等。
 36 查看详情
36 查看详情 
SparkContextSparkContext serves as the entry point for a Spark session. It connects you to the Spark cluster and enables the creation of RDDs, accumulators, and broadcast variables on that cluster. Ideally, only one SparkContext should be active per JVM. Therefore, you must call stop() on the active SparkContext before initiating a new one. In local mode, when starting a Python or Scala shell, a SparkContext object is automatically created, and the variable sc references this SparkContext object, allowing you to create RDDs from text files without explicitly initializing it.
/** * Read a text file from HDFS, a local file system (available on all nodes), or any * Hadoop-supported file system URI, and return it as an RDD of Strings. * The text files must be encoded as UTF-8. * * @param path path to the text file on a supported file system * @param minPartitions suggested minimum number of partitions for the resulting RDD * @return RDD of lines of the text file */def textFile( path: String, minPartitions: Int = defaultMinPartitions): RDD[String] = withScope { assertNotStopped() hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text], minPartitions).map(pair => pair._2.toString).setName(path)}/** Get an RDD for a Hadoop file with an arbitrary InputFormat
- @note Because Hadoop's RecordReader class re-uses the same Writable object for each
- record, directly caching the returned RDD or directly passing it to an aggregation or shuffle
- operation will create many references to the same object.
- If you plan to directly cache, sort, or aggregate Hadoop writable objects, you should first
- copy them using a
map function. - @param path directory to the input data files, the path can be comma separated paths
- as a list of inputs
- @param inputFormatClass storage format of the data to be read
- @param keyClass
Classof the key associated with theinputFormatClassparameter - @param valueClass
Classof the value associated with theinputFormatClassparameter - @param minPartitions suggested minimum number of partitions for the resulting RDD
- @return RDD of tuples of key and corresponding value*/def hadoopFile[K, V](path: String,inputFormatClass: Class[_ FileInputFormat.setInputPaths(jobConf, path)new HadoopRDD(this,confBroadcast,Some(setInputPathsFunc),inputFormatClass,keyClass,valueClass,minPartitions).setName(path)}
Spark SessionThe Spark Session is the entry point for programming with Spark using the dataset and DataFrame API.
For more in-depth information, you can refer to the following resource: Apache Spark Architecture.
以上就是Spark Architecture 系统架构的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/477828.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















