
原标题:spring认证中国教育管理中心-apache geode 的 spring 数据教程五(spring中国教育管理中心)
5.5.9.数据过期
Apache Geode 允许您控制条目在缓存中的存留时间。过期是由经过的时间驱动的,而不是驱逐,后者是由条目数量或堆或内存使用情况驱动的。一旦条目过期,它将无法再从缓存中访问。
Apache Geode 支持以下过期类型:
生存时间 (TTL):对象在上次创建或更新后可以在缓存中保留的时间量(以秒为单位)。对于条目,创建和放置操作的计数器被设置为零。区域计数器在创建区域和条目的计数器重置时重置。空闲超时 (TTI):对象在上次访问后可以在缓存中保留的时间量(以秒为单位)。每当重置其 TTL 计数器时,对象的空闲超时计数器也会重置。此外,每当通过 get 操作或 netSearch 访问时,对象的空闲超时计数器也会重置。每当为其条目之一重置空闲超时时,区域的空闲超时计数器也会重置。这些过期类型可以应用于区域本身或区域中的条目。Spring Data for Apache Geode 提供了 、、 和 Region 子元素来指定超时值和到期操作。
以下示例展示了具有过期值设置的 PARTITION 区域:
有关过期策略的详细说明,请参阅 Apache Geode 的过期文档。
基于注释的数据过期
使用 Spring Data for Apache Geode,您可以为各个 Region 条目值定义过期策略和设置(或者,换句话说,直接在应用程序域对象上)。例如,您可以在基于会话的应用程序域对象上定义过期策略,如下所示:
@Expiration(timeout = "1800", action = "INVALIDATE")public class SessionBasedApplicationDomainObject { ...}
您还可以使用 @IdleTimeoutExpiration 和 @TimeToLiveExpiration 注释分别指定区域条目上的空闲超时 (TTI) 和生存时间 (TTL) 过期的特定设置,如以下示例所示:
@TimeToLiveExpiration(timeout = "3600", action = "LOCAL_DESTROY")@IdleTimeoutExpiration(timeout = "1800", action = "LOCAL_INVALIDATE")@Expiration(timeout = "1800", action = "INVALIDATE")public class AnotherSessionBasedApplicationDomainObject { ...}
当多个到期注释类型被指定时,@IdleTimeoutExpiration 和 @TimeToLiveExpiration 优先于一般的 @Expiration 注释。它们不会相互覆盖,而是补充不同的 Region 条目过期策略(例如 TTL 和 TTI)。
@Expiration 注释仅适用于区域条目值。Spring Data for Apache Geode 的过期注释支持不涵盖区域的过期。但是,Apache Geode 和 Spring Data for Apache Geode 确实允许您使用 SDG XML 命名空间设置区域到期时间,如下所示:
Spring Data for Apache Geode 的 @Expiration 注解支持是通过 Apache Geode 的 CustomExpiry 接口实现的。有关更多详细信息,请参阅 Apache Geode 关于配置数据过期的文档。
Spring Data for Apache Geode 的 AnnotationBasedExpiration 类(和 CustomExpiry 实现)负责处理 SDG @Expiration 注释,并根据请求为 Region 条目过期适当地应用过期策略配置。
要使用 Spring Data for Apache Geode 配置特定的 Apache Geode Regions 以将过期策略适当地应用于使用 @Expiration 基于注释的应用程序域对象,您必须:
在 Spring ApplicationContext 中定义一个 AnnotationBasedExpiration 类型的 bean,通过使用适当的构造函数或方便的工厂方法之一。在为特定的到期类型(例如空闲超时 (TTI) 或生存时间 (TTL))配置到期时,您应该使用 AnnotationBasedExpiration 类中的工厂方法之一,如下所示:
要配置空闲超时 (TTI) 到期时间,请使用 forIdleTimeout 工厂方法和 元素来设置 TTI。
(可选)使用 Spring Data for Apache Geode 的 @Expiration 注释之一,使用过期策略和自定义设置对存储在区域中的应用程序域对象进行注释:@Expiration, @IdleTimeoutExpiration, 或 @TimeToLiveExpiration。
(可选)如果特定应用程序域对象根本没有使用 Spring Data for Apache Geode 的 @Expiration 注解进行注解,但 Apache Geode 区域配置为使用 SDG 的自定义 AnnotationBasedExpiration 类来确定存储在区域中的对象的过期策略和设置,您可以通过在 bean 上设置“默认”过期属性来实现,如下所示:
您可能已经注意到 Spring Data for Apache Geode 的 @Expiration 注解使用 String 作为属性类型,而不是(可能更合适的)强类型——例如,int 对于 ‘timeout’ 和 SDG’s ExpirationActionType 对于 ‘action’。这是为什么?
好吧,输入 Spring Data for Apache Geode 的其他功能之一,利用 Spring 的核心基础设施来方便配置:属性占位符和 Spring 表达式语言 (SpEL) 表达式。
例如,开发人员可以通过在 @Expiration 注释属性中使用属性占位符来指定到期“超时”和“操作”,如以下示例所示:
@TimeToLiveExpiration(timeout = "${geode.region.entry.expiration.ttl.timeout}" action = "${geode.region.entry.expiration.ttl.action}")public class ExampleApplicationDomainObject { ...}
然后,在您的 Spring XML 配置或 JavaConfig 中,您可以声明以下 bean:
600 INVALIDATE ...
当多个应用程序域对象可能共享相似的过期策略时以及当您希望将配置外部化时,这都很方便。
但是,您可能需要由正在运行的系统的状态确定的更多动态到期配置。这就是 SpEL 的强大之处,实际上也是推荐的方法。您不仅可以在 Spring 容器中引用 bean 并访问 bean 属性、调用方法等,而且过期 ‘timeout’ 和 ‘action’ 的值可以是强类型的。考虑以下示例(基于前面的示例):
600 #{T(org.springframework.data.gemfire.expiration.ExpirationActionType).DESTROY} #{T(org.apache.geode.cache.ExpirationAction).INVALIDATE} ...
然后,在您的应用程序域对象上,您可以定义超时和操作,如下所示:
@TimeToLiveExpiration(timeout = "@expirationSettings['geode.region.entry.expiration.ttl.timeout']" action = "@expirationSetting['geode.region.entry.expiration.ttl.action']")public class ExampleApplicationDomainObject { ...}
您可以想象,“expirationSettings” bean 可能是一个比 java.util.Properties 的简单实例更有趣和有用的对象。在前面的示例中,properties 元素 (expirationSettings) 使用 SpEL 将操作值建立在实际 ExpirationAction 枚举类型的基础上,如果枚举类型发生变化,则会迅速导致识别失败。
例如,所有这些都已在 Spring Data for Apache Geode 测试套件中进行了演示和测试。有关更多详细信息,请参阅 来源。
5.5.10.数据持久化
 百度文心百中
百度文心百中
百度大模型语义搜索体验中心
 22 查看详情
22 查看详情 
区域可以是持久的。Apache Geode 确保您放入配置为持久性的区域的所有数据都以可在您下次重新创建区域时恢复的方式写入磁盘。这样做可以让数据在机器或进程失败后,甚至在 Apache Geode 数据节点有序关闭和随后重新启动后恢复。
要使用 Spring Data for Apache Geode 启用持久性,请将任何元素上的 persistent 属性设置为 true,如以下示例所示:
也可以通过设置 data-policy 属性来配置持久性。为此,请将属性值设置为 Apache Geode 的 DataPolicy 设置之一,如以下示例所示:
在 DataPolicy 一定的区域类型匹配,并且还必须与同意 persistent 的属性,如果它也明确设置。如果该 persistent 属性设置为 false 但 DataPolicy 指定了持久性(例如 PERSISTENT_REPLICATE 或 PERSISTENT_PARTITION),则会引发初始化异常。
为了在持久化区域时获得最大效率,您应该通过 disk-store 元素配置存储。在 DiskStore 通过使用引用的 disk-store-ref 属性。此外,该区域可以同步或异步执行磁盘写入。以下示例显示了一个同步 DiskStore:
这将在配置 DiskStore 中进一步讨论。
5.5.11.订阅政策
Apache Geode 允许配置点对点 (P2P) 事件消息传递 来控制区域接收的入口事件。Spring Data for Apache Geode 提供了 子元素来将订阅策略 REPLICATE 和 PARTITION 区域设置为 ALL 或 CACHE_CONTENT。以下示例显示了其订阅策略设置为 CACHE_CONTENT 的区域:
5.5.12.本地区域
Spring Data for Apache Geode 提供了 local-region 用于创建本地区域的专用元素。顾名思义,本地区域是独立的,这意味着它们不与任何其他分布式系统成员共享数据。除此之外,所有常见的区域配置选项都适用。
以下示例显示了一个最小声明(同样,该示例依赖 Spring Data for Apache Geode XML 命名空间命名约定来连接缓存):
在前面的示例中,创建了一个本地 Region(如果同名的 Region 尚不存在)。Region 的名称与 bean ID (exampleLocalRegion) 相同,并且 bean 假定存在名为 gemfireCache 的 Apache Geode 缓存。
5.5.13.复制区域
一种常见的 Region 类型是 REPLICATE Region 或“副本”。简而言之,当一个区域被配置为 REPLICATE 时,承载该区域的每个成员都会在本地存储该区域条目的副本。对 REPLICATE 区域的任何更新都会分发到该区域的所有副本。创建副本时,它会经历一个初始化阶段,在此阶段它会发现其他副本并自动复制所有条目。当一个副本正在初始化时,您仍然可以继续使用其他副本。
所有常见的配置选项都可用于 REPLICATE 区域。Spring Data for Apache Geode 提供了一个 replicated-region 元素。以下示例显示了一个最小声明:
有关更多详细信息,请参阅 Apache Geode 关于分布式和复制区域的文档。
5.5.14.分区区域
Spring Data for Apache Geode XML 命名空间也支持 PARTITION 区域。
引用 Apache Geode 文档:
“分区区域是数据在托管该区域的对等服务器之间划分的区域,以便每个对等服务器存储数据的子集。使用分区区域时,应用程序会显示区域的逻辑视图,该视图看起来像包含该区域中所有数据的单个地图。对此映射的读取或写入透明地路由到承载作为操作目标的条目的对等方。Apache Geode 将哈希码域划分为桶。每个桶都分配给一个特定的对等点,但可以随时重新定位到另一个对等点,以提高整个集群的资源利用率。”
一个 PARTITION 区域通过使用 partitioned-region 的元素创建。它的配置选项与 replicated-region 的类似,但增加了特定于分区的功能,例如冗余副本数、最大总内存、桶数、分区解析器等。
以下示例显示如何设置具有两个冗余副本的 PARTITION 区域:
有关更多详细信息,请参阅 Apache Geode 关于分区区域的文档。
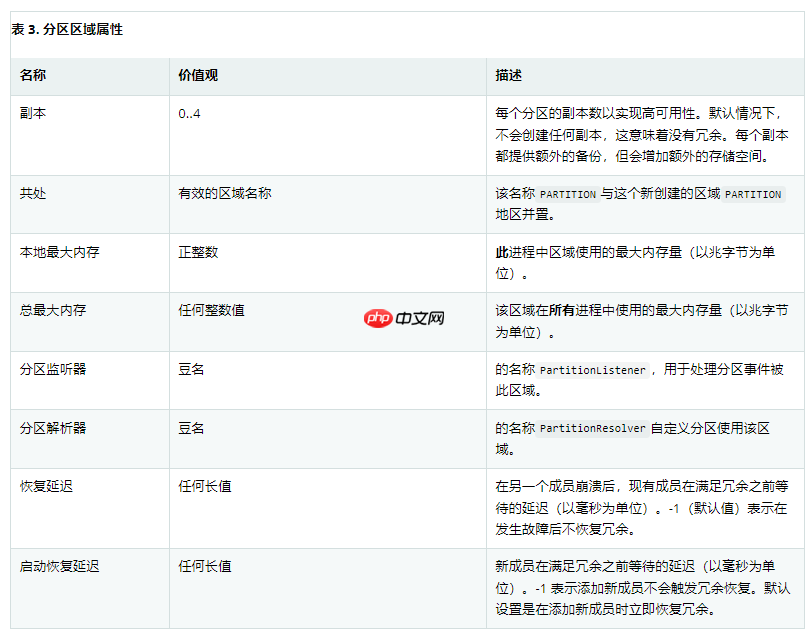
分区区域属性
下表提供了特定于 PARTITION 区域的配置选项的快速概览。这些选项是对前面描述的常见区域配置选项的补充。
以上就是Spring认证中国教育管理中心-Apache Geode 的 Spring 数据教程五的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/479785.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















