该内容围绕中文场景文字识别常规赛展开,介绍了比赛任务是用飞桨框架预测图像文字行内容。涵盖数据集情况,利用PaddleOCR的配置、训练、评估、预测等流程,包括模型选择、参数设置、预训练模型使用,以及结果提交相关的模型导出等内容。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、常规赛:中文场景文字识别
比赛地址:https://aistudio.baidu.com/aistudio/competition/detail/20/0/datasets
1.比赛简介
中文场景文字识别技术在人们的日常生活中受到广泛关注,具有丰富的应用场景,如:拍照翻译、图像检索、场景理解等。然而,中文场景中的文字面临着包括光照变化、低分辨率、字体以及排布多样性、中文字符种类多等复杂情况。如何解决上述问题成为一项极具挑战性的任务。
中文场景文字识别常规赛全新升级,提供轻量级中文场景文字识别数据,要求选手使用飞桨框架,对图像区域中的文字行进行预测,并返回文字行的内容。
2.数据集描述
本次赛题数据集共包括6万张图片,其中5万张图片作为训练集,1万张作为测试集。数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。
具体数据介绍
数据集中所有图像都经过一些预处理,如下图所示:

(a) 标注:久斯台球会所

(b) 标注:上海创科泵业制造有限公司
标注文件
平台提供的标注文件为.csv文件格式,文件中的四列分别为图片的宽、高、文件名和文字标注。样例如下:
0.jpg文本0—————-1.jpg文本0
二、环境设置
PaddleOCR https://github.com/paddlepaddle/PaddleOCR 是一款全宇宙最强的用的OCR工具库,开箱即用,速度杠杠的。
In [ ]
# 从gitee上下载PaddleOCR代码,也可以从GitHub链接下载!git clone https://gitee.com/paddlepaddle/PaddleOCR.git --depth=1# 升级pip!pip install -U pip # 安装依赖%cd ~/PaddleOCR%pip install -r requirements.txt
In [ ]
%cd ~/PaddleOCR/!tree -L 1
/home/aistudio/PaddleOCR.├── benchmark├── configs├── deploy├── doc├── __init__.py├── LICENSE├── MANIFEST.in├── paddleocr.py├── ppocr├── PPOCRLabel├── ppstructure├── README_ch.md├── README.md├── requirements.txt├── setup.py├── StyleText├── test_tipc├── tools└── train.sh10 directories, 9 files
三、数据准备
据悉train数据集共10万张,解压,并划分出10000张作为测试集。
1.数据下载解压
In [ ]
# 解压缩数据集%cd ~!unzip -qa data/data62842/train_images.zip -d data/data62842/!unzip -qa data/data62843/test_images.zip -d data/data62843/
/home/aistudio
In [ ]
# 使用命令查看训练数据文件夹下数据量是否是5万张!cd ~/data/data62842/train_images && ls -l | grep "^-" | wc -l
50000
In [ ]
# 使用命令查看test数据文件夹下数据量是否是1万张!cd ~/data/data62843/test_images && ls -l | grep "^-" | wc -l
10000
2. 数据集划分
In [ ]
# 读取数据列表文件import pandas as pd%cd ~data_label=pd.read_csv('data/data62842/train_label.csv', encoding='gb2312')data_label.head()
/home/aistudio
name value0 0.jpg 拉拉1 1.jpg 6号2 2.jpg 胖胖3 3.jpg 前门大栅栏总店4 4.jpg 你来就是旺季
In [ ]
# 对数据列表文件进行划分%cd ~/data/data62842/print(data_label.shape)train=data_label[:45000]val=data_label[45000:]train.to_csv('train.txt',sep='t',header=None,index=None)val.to_csv('val.txt',sep='t',header=None,index=None)
/home/aistudio/data/data62842(50000, 2)
In [ ]
# 查看数量print(train.shape)print(val.shape)
(45000, 2)(5000, 2)
In [ ]
!head val.txt
45000.jpg责任单位:北京市环清环卫设施维修45001.jpg眼镜45002.jpg光临45003.jpg主治45004.jpg菜饭骨头汤45005.jpg理45006.jpg要多者提前预定45007.jpg干洗湿洗45008.jpg画布咖啡45009.jpg电焊、气割、专业自卸车
In [ ]
!head train.txt
0.jpg拉拉1.jpg6号2.jpg胖胖3.jpg前门大栅栏总店4.jpg你来就是旺季5.jpg毛衣厂家直销6.jpg137619162187.jpg福鼎白茶8.jpg妍心美容9.jpg童车童床
四、配置训练参数
以PaddleOCR/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml为基准进行配置
1.配置模型网络
使用CRNN算法,backbone是MobileNetV3,损失函数是CTCLoss
Architecture: model_type: rec algorithm: CRNN Transform: Backbone: name: MobileNetV3 scale: 0.5 model_name: small small_stride: [1, 2, 2, 2] Neck: name: SequenceEncoder encoder_type: rnn hidden_size: 48 Head: name: CTCHead fc_decay: 0.00001
2.配置数据
对Train.data_dir, Train.label_file_list, Eval.data_dir, Eval.label_file_list进行配置
Train: dataset: name: SimpleDataSet data_dir: /home/aistudio/data/data62842/train_images label_file_list: ["/home/aistudio/data/data62842/train.txt"]......Eval: dataset: name: SimpleDataSet data_dir: /home/aistudio/data/data62842/train_images label_file_list: ["/home/aistudio/data/data62842/val.txt"]
3. 显卡、评估设置
use_gpu、cal_metric_during_train分别是GPU、评估开关
Global: use_gpu: false # true 使用GPU ..... cal_metric_during_train: False # true 打开评估
4. 多线程任务
Train.loader.num_workers:4Eval.loader.num_workers: 4
5.完整配置
Global: use_gpu: true epoch_num: 500 log_smooth_window: 20 print_batch_step: 10 save_model_dir: ./output/rec_chinese_lite_v2.0 save_epoch_step: 3 # evaluation is run every 5000 iterations after the 4000th iteration eval_batch_step: [0, 2000] cal_metric_during_train: True pretrained_model: ./ch_ppocr_mobile_v2.0_rec_pre/best_accuracy checkpoints: save_inference_dir: use_visualdl: True infer_img: doc/imgs_words/ch/word_1.jpg # for data or label process character_dict_path: ppocr/utils/ppocr_keys_v1.txt max_text_length: 25 infer_mode: False use_space_char: True save_res_path: ./output/rec/predicts_chinese_lite_v2.0.txtOptimizer: name: Adam beta1: 0.9 beta2: 0.999 lr: name: Cosine learning_rate: 0.001 warmup_epoch: 5 regularizer: name: 'L2' factor: 0.00001Architecture: model_type: rec algorithm: CRNN Transform: Backbone: name: MobileNetV3 scale: 0.5 model_name: small small_stride: [1, 2, 2, 2] Neck: name: SequenceEncoder encoder_type: rnn hidden_size: 48 Head: name: CTCHead fc_decay: 0.00001Loss: name: CTCLossPostProcess: name: CTCLabelDecodeMetric: name: RecMetric main_indicator: accTrain: dataset: name: SimpleDataSet data_dir: /home/aistudio/data/data62842/train_images label_file_list: ["/home/aistudio/data/data62842/train.txt"] transforms: - DecodeImage: # load image img_mode: BGR channel_first: False - RecAug: - CTCLabelEncode: # Class handling label - RecResizeImg: image_shape: [3, 32, 320] - KeepKeys: keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order loader: shuffle: True batch_size_per_card: 256 drop_last: True num_workers: 8Eval: dataset: name: SimpleDataSet data_dir: /home/aistudio/data/data62842/train_images label_file_list: ["/home/aistudio/data/data62842/val.txt"] transforms: - DecodeImage: # load image img_mode: BGR channel_first: False - CTCLabelEncode: # Class handling label - RecResizeImg: image_shape: [3, 32, 320] - KeepKeys: keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order loader: shuffle: False drop_last: False batch_size_per_card: 256 num_workers: 8
In [1]
# 覆盖配置!cp -f ~/rec_chinese_lite_train_v2.0.yml ~/PaddleOCR/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
cp: cannot stat '/home/aistudio/PaddleOCR/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml': No such file or directory
6.使用预训练模型
据悉使用预训练模型,训练速度更快!!!
PaddleOCR提供的可下载模型包括推理模型、训练模型、预训练模型、slim模型,模型区别说明如下:
推理模型inference.pdmodel、inference.pdiparams用于预测引擎推理,详情训练模型、预训练模型*.pdparams、*.pdopt、*.states训练过程中保存的模型的参数、优化器状态和训练中间信息,多用于模型指标评估和恢复训练slim模型*.nb经过飞桨模型压缩工具PaddleSlim压缩后的模型,适用于移动端/IoT端等端侧部署场景(需使用飞桨Paddle Lite部署)。
各个模型的关系如下面的示意图所示。

文本检测模型
ch_ppocr_mobile_slim_v2.0_detslim裁剪版超轻量模型,支持中英文、多语种文本检测ch_det_mv3_db_v2.0.yml2.6M推理模型ch_ppocr_mobile_v2.0_det原始超轻量模型,支持中英文、多语种文本检测ch_det_mv3_db_v2.0.yml3M推理模型 / 训练模型ch_ppocr_server_v2.0_det通用模型,支持中英文、多语种文本检测,比超轻量模型更大,但效果更好ch_det_res18_db_v2.0.yml47M推理模型 / 训练模型
文本识别模型
中文识别模型
ch_ppocr_mobile_slim_v2.0_recslim裁剪量化版超轻量模型,支持中英文、数字识别rec_chinese_lite_train_v2.0.yml6M推理模型 / 训练模型ch_ppocr_mobile_v2.0_rec原始超轻量模型,支持中英文、数字识别rec_chinese_lite_train_v2.0.yml5.2M推理模型 / 训练模型 / 预训练模型ch_ppocr_server_v2.0_rec通用模型,支持中英文、数字识别rec_chinese_common_train_v2.0.yml94.8M推理模型 / 训练模型 / 预训练模型
说明: 训练模型是基于预训练模型在真实数据与竖排合成文本数据上finetune得到的模型,在真实应用场景中有着更好的表现,预训练模型则是直接基于全量真实数据与合成数据训练得到,更适合用于在自己的数据集上finetune。
英文识别模型
en_number_mobile_slim_v2.0_recslim裁剪量化版超轻量模型,支持英文、数字识别rec_en_number_lite_train.yml2.7M推理模型 / 训练模型en_number_mobile_v2.0_rec原始超轻量模型,支持英文、数字识别rec_en_number_lite_train.yml2.6M推理模型 / 训练模型
In [ ]
%cd ~/PaddleOCR/# mobile模型# !wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar# !tar -xf ch_ppocr_mobile_v2.0_rec_pre.tar# server模型!wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar!tar -xf ch_ppocr_server_v2.0_rec_pre.tar
/home/aistudio/PaddleOCR--2021-12-31 12:58:03-- https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tarResolving paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c04:1001:1002:0:ff:b001:368aConnecting to paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)|182.61.200.195|:443... connected.HTTP request sent, awaiting response... 200 OKLength: 490184704 (467M) [application/x-tar]Saving to: ‘ch_ppocr_server_v2.0_rec_pre.tar’ch_ppocr_server_v2. 100%[===================>] 467.48M 56.0MB/s in 13s 2021-12-31 12:58:17 (34.9 MB/s) - ‘ch_ppocr_server_v2.0_rec_pre.tar’ saved [490184704/490184704]
五、训练
In [9]
%cd ~/PaddleOCR/# mobile模型# !python tools/train.py -c ./configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.checkpoints=./output/rec_chinese_lite_v2.0/latest# server模型!python tools/train.py -c ./configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml
1.选择合适的batch size
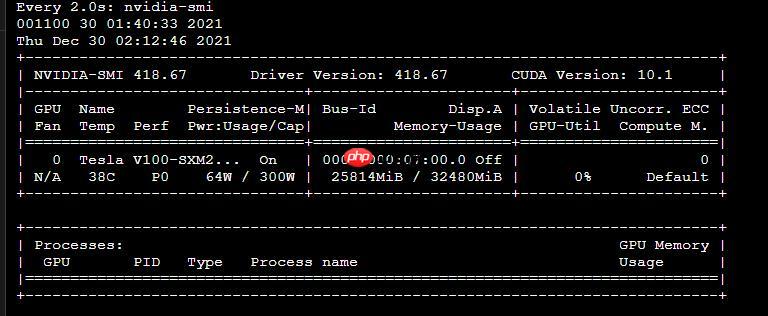
2.训练日志
[2021/12/30 23:26:54] root INFO: epoch: [68/500], iter: 9930, lr: 0.000962, loss: 5.635038, acc: 0.521482, norm_edit_dis: 0.745346, reader_cost: 0.01405 s, batch_cost: 0.26990 s, samples: 2560, ips: 948.50786[2021/12/30 23:27:11] root INFO: epoch: [68/500], iter: 9940, lr: 0.000962, loss: 5.653114, acc: 0.509764, norm_edit_dis: 0.740487, reader_cost: 0.01402 s, batch_cost: 0.26862 s, samples: 2560, ips: 953.03473[2021/12/30 23:27:26] root INFO: epoch: [68/500], iter: 9950, lr: 0.000962, loss: 5.411234, acc: 0.515623, norm_edit_dis: 0.748549, reader_cost: 0.00091 s, batch_cost: 0.26371 s, samples: 2560, ips: 970.76457[2021/12/30 23:27:40] root INFO: epoch: [68/500], iter: 9960, lr: 0.000962, loss: 5.588465, acc: 0.525389, norm_edit_dis: 0.755345, reader_cost: 0.00684 s, batch_cost: 0.25901 s, samples: 2560, ips: 988.38445[2021/12/30 23:27:48] root INFO: epoch: [68/500], iter: 9970, lr: 0.000961, loss: 5.789876, acc: 0.513670, norm_edit_dis: 0.740609, reader_cost: 0.00095 s, batch_cost: 0.15022 s, samples: 2560, ips: 1704.17763[2021/12/30 23:27:51] root INFO: epoch: [68/500], iter: 9974, lr: 0.000961, loss: 5.787237, acc: 0.511717, norm_edit_dis: 0.747102, reader_cost: 0.00018 s, batch_cost: 0.05935 s, samples: 1024, ips: 1725.41448[2021/12/30 23:27:51] root INFO: save model in ./output/rec_chinese_lite_v2.0/latest[2021/12/30 23:27:51] root INFO: Initialize indexs of datasets:['/home/aistudio/data/data62842/train.txt'][2021/12/30 23:28:21] root INFO: epoch: [69/500], iter: 9980, lr: 0.000961, loss: 5.801509, acc: 0.517576, norm_edit_dis: 0.749756, reader_cost: 1.10431 s, batch_cost: 1.37585 s, samples: 1536, ips: 111.64048[2021/12/30 23:28:40] root INFO: epoch: [69/500], iter: 9990, lr: 0.000961, loss: 5.548770, acc: 0.533201, norm_edit_dis: 0.762078, reader_cost: 0.00839 s, batch_cost: 0.32035 s, samples: 2560, ips: 799.11578[2021/12/30 23:28:56] root INFO: epoch: [69/500], iter: 10000, lr: 0.000961, loss: 5.449094, acc: 0.537107, norm_edit_dis: 0.762517, reader_cost: 0.00507 s, batch_cost: 0.25845 s, samples: 2560, ips: 990.51517eval model:: 100%|██████████████████████████████| 20/20 [00:15<00:00, 1.98it/s][2021/12/30 23:29:12] root INFO: cur metric, acc: 0.4641999071600186, norm_edit_dis: 0.6980459628854201, fps: 4204.853978632389[2021/12/30 23:29:12] root INFO: best metric, acc: 0.48179990364001923, start_epoch: 12, norm_edit_dis: 0.7096561279006699, fps: 4618.199275059127, best_epoch: 46
3. visualdl可视化
本地安装visualdl pip install visualdl下载日志至本地启动visualdl可视化 visualdl –logdir ./打开浏览器查看 http://localhost:8040/
六、模型评估
In [10]
# GPU 评估, Global.checkpoints 为待测权重%cd ~/PaddleOCR/# mobile模型# !python -m paddle.distributed.launch tools/eval.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml # -o Global.checkpoints=./output/rec_chinese_lite_v2.0/latest# server模型!python -m paddle.distributed.launch tools/eval.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml -o Global.checkpoints=./output/rec_chinese_common_v2.0/best_accuracy.pdparams
/home/aistudio/PaddleOCR----------- Configuration Arguments -----------backend: autoelastic_server: Noneforce: Falsegpus: Noneheter_devices: heter_worker_num: Noneheter_workers: host: Nonehttp_port: Noneips: 127.0.0.1job_id: Nonelog_dir: lognp: Nonenproc_per_node: Nonerun_mode: Nonescale: 0server_num: Noneservers: training_script: tools/eval.pytraining_script_args: ['-c', 'configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml', '-o', 'Global.checkpoints=./output/rec_chinese_common_v2.0/best_accuracy.pdparams']worker_num: Noneworkers: ------------------------------------------------WARNING 2021-12-31 18:51:19,722 launch.py:423] Not found distinct arguments and compiled with cuda or xpu. Default use collective modelaunch train in GPU mode!INFO 2021-12-31 18:51:19,725 launch_utils.py:528] Local start 1 processes. First process distributed environment info (Only For Debug): +=======================================================================================+ | Distributed Envs Value | +---------------------------------------------------------------------------------------+ | PADDLE_TRAINER_ID 0 | | PADDLE_CURRENT_ENDPOINT 127.0.0.1:46063 | | PADDLE_TRAINERS_NUM 1 | | PADDLE_TRAINER_ENDPOINTS 127.0.0.1:46063 | | PADDLE_RANK_IN_NODE 0 | | PADDLE_LOCAL_DEVICE_IDS 0 | | PADDLE_WORLD_DEVICE_IDS 0 | | FLAGS_selected_gpus 0 | | FLAGS_selected_accelerators 0 | +=======================================================================================+INFO 2021-12-31 18:51:19,725 launch_utils.py:532] details abouts PADDLE_TRAINER_ENDPOINTS can be found in log/endpoints.log, and detail running logs maybe found in log/workerlog.0launch proc_id:16263 idx:0[2021/12/31 18:51:21] root INFO: Architecture : [2021/12/31 18:51:21] root INFO: Backbone : [2021/12/31 18:51:21] root INFO: layers : 34[2021/12/31 18:51:21] root INFO: name : ResNet[2021/12/31 18:51:21] root INFO: Head : [2021/12/31 18:51:21] root INFO: fc_decay : 4e-05[2021/12/31 18:51:21] root INFO: name : CTCHead[2021/12/31 18:51:21] root INFO: Neck : [2021/12/31 18:51:21] root INFO: encoder_type : rnn[2021/12/31 18:51:21] root INFO: hidden_size : 256[2021/12/31 18:51:21] root INFO: name : SequenceEncoder[2021/12/31 18:51:21] root INFO: Transform : None[2021/12/31 18:51:21] root INFO: algorithm : CRNN[2021/12/31 18:51:21] root INFO: model_type : rec[2021/12/31 18:51:21] root INFO: Eval : [2021/12/31 18:51:21] root INFO: dataset : [2021/12/31 18:51:21] root INFO: data_dir : /home/aistudio/data/data62842/train_images[2021/12/31 18:51:21] root INFO: label_file_list : ['/home/aistudio/data/data62842/val.txt'][2021/12/31 18:51:21] root INFO: name : SimpleDataSet[2021/12/31 18:51:21] root INFO: transforms : [2021/12/31 18:51:21] root INFO: DecodeImage : [2021/12/31 18:51:21] root INFO: channel_first : False[2021/12/31 18:51:21] root INFO: img_mode : BGR[2021/12/31 18:51:21] root INFO: CTCLabelEncode : None[2021/12/31 18:51:21] root INFO: RecResizeImg : [2021/12/31 18:51:21] root INFO: image_shape : [3, 32, 320][2021/12/31 18:51:21] root INFO: KeepKeys : [2021/12/31 18:51:21] root INFO: keep_keys : ['image', 'label', 'length'][2021/12/31 18:51:21] root INFO: loader : [2021/12/31 18:51:21] root INFO: batch_size_per_card : 256[2021/12/31 18:51:21] root INFO: drop_last : False[2021/12/31 18:51:21] root INFO: num_workers : 8[2021/12/31 18:51:21] root INFO: shuffle : False[2021/12/31 18:51:21] root INFO: Global : [2021/12/31 18:51:21] root INFO: cal_metric_during_train : True[2021/12/31 18:51:21] root INFO: character_dict_path : ppocr/utils/ppocr_keys_v1.txt[2021/12/31 18:51:21] root INFO: checkpoints : ./output/rec_chinese_common_v2.0/best_accuracy.pdparams[2021/12/31 18:51:21] root INFO: debug : False[2021/12/31 18:51:21] root INFO: distributed : False[2021/12/31 18:51:21] root INFO: epoch_num : 500[2021/12/31 18:51:21] root INFO: eval_batch_step : [0, 2000][2021/12/31 18:51:21] root INFO: infer_img : doc/imgs_words/ch/word_1.jpg[2021/12/31 18:51:21] root INFO: infer_mode : False[2021/12/31 18:51:21] root INFO: log_smooth_window : 20[2021/12/31 18:51:21] root INFO: max_text_length : 25[2021/12/31 18:51:21] root INFO: pretrained_model : ./ch_ppocr_server_v2.0_rec_pre/best_accuracy[2021/12/31 18:51:21] root INFO: print_batch_step : 10[2021/12/31 18:51:21] root INFO: save_epoch_step : 3[2021/12/31 18:51:21] root INFO: save_inference_dir : None[2021/12/31 18:51:21] root INFO: save_model_dir : ./output/rec_chinese_common_v2.0[2021/12/31 18:51:21] root INFO: save_res_path : ./output/rec/predicts_chinese_common_v2.0.txt[2021/12/31 18:51:21] root INFO: use_gpu : True[2021/12/31 18:51:21] root INFO: use_space_char : True[2021/12/31 18:51:21] root INFO: use_visualdl : False[2021/12/31 18:51:21] root INFO: Loss : [2021/12/31 18:51:21] root INFO: name : CTCLoss[2021/12/31 18:51:21] root INFO: Metric : [2021/12/31 18:51:21] root INFO: main_indicator : acc[2021/12/31 18:51:21] root INFO: name : RecMetric[2021/12/31 18:51:21] root INFO: Optimizer : [2021/12/31 18:51:21] root INFO: beta1 : 0.9[2021/12/31 18:51:21] root INFO: beta2 : 0.999[2021/12/31 18:51:21] root INFO: lr : [2021/12/31 18:51:21] root INFO: learning_rate : 0.001[2021/12/31 18:51:21] root INFO: name : Cosine[2021/12/31 18:51:21] root INFO: warmup_epoch : 5[2021/12/31 18:51:21] root INFO: name : Adam[2021/12/31 18:51:21] root INFO: regularizer : [2021/12/31 18:51:21] root INFO: factor : 4e-05[2021/12/31 18:51:21] root INFO: name : L2[2021/12/31 18:51:21] root INFO: PostProcess : [2021/12/31 18:51:21] root INFO: name : CTCLabelDecode[2021/12/31 18:51:21] root INFO: Train : [2021/12/31 18:51:21] root INFO: dataset : [2021/12/31 18:51:21] root INFO: data_dir : /home/aistudio/data/data62842/train_images[2021/12/31 18:51:21] root INFO: label_file_list : ['/home/aistudio/data/data62842/train.txt'][2021/12/31 18:51:21] root INFO: name : SimpleDataSet[2021/12/31 18:51:21] root INFO: transforms : [2021/12/31 18:51:21] root INFO: DecodeImage : [2021/12/31 18:51:21] root INFO: channel_first : False[2021/12/31 18:51:21] root INFO: img_mode : BGR[2021/12/31 18:51:21] root INFO: RecAug : None[2021/12/31 18:51:21] root INFO: CTCLabelEncode : None[2021/12/31 18:51:21] root INFO: RecResizeImg : [2021/12/31 18:51:21] root INFO: image_shape : [3, 32, 320][2021/12/31 18:51:21] root INFO: KeepKeys : [2021/12/31 18:51:21] root INFO: keep_keys : ['image', 'label', 'length'][2021/12/31 18:51:21] root INFO: loader : [2021/12/31 18:51:21] root INFO: batch_size_per_card : 256[2021/12/31 18:51:21] root INFO: drop_last : True[2021/12/31 18:51:21] root INFO: num_workers : 8[2021/12/31 18:51:21] root INFO: shuffle : True[2021/12/31 18:51:21] root INFO: profiler_options : None[2021/12/31 18:51:21] root INFO: train with paddle 2.2.1 and device CUDAPlace(0)[2021/12/31 18:51:21] root INFO: Initialize indexs of datasets:['/home/aistudio/data/data62842/val.txt']W1231 18:51:21.482865 16263 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1W1231 18:51:21.487445 16263 device_context.cc:465] device: 0, cuDNN Version: 7.6.[2021/12/31 18:51:26] root INFO: resume from ./output/rec_chinese_common_v2.0/best_accuracy[2021/12/31 18:51:26] root INFO: metric in ckpt ***************[2021/12/31 18:51:26] root INFO: acc:0.6035998792800241[2021/12/31 18:51:26] root INFO: norm_edit_dis:0.8053270782756357[2021/12/31 18:51:26] root INFO: fps:438.9587163608945[2021/12/31 18:51:26] root INFO: best_epoch:23[2021/12/31 18:51:26] root INFO: start_epoch:24eval model:: 0%| | 0/20 [00:00<?, ?it/s]eval model:: 5%|▌ | 1/20 [00:02<00:54, 2.88s/it]eval model:: 10%|█ | 2/20 [00:04<00:43, 2.42s/it]eval model:: 15%|█▌ | 3/20 [00:05<00:35, 2.10s/it]eval model:: 20%|██ | 4/20 [00:06<00:29, 1.87s/it]eval model:: 25%|██▌ | 5/20 [00:08<00:25, 1.71s/it]eval model:: 30%|███ | 6/20 [00:09<00:22, 1.60s/it]eval model:: 35%|███▌ | 7/20 [00:10<00:19, 1.53s/it]eval model:: 40%|████ | 8/20 [00:12<00:17, 1.48s/it]eval model:: 45%|████▌ | 9/20 [00:13<00:15, 1.44s/it]eval model:: 50%|█████ | 10/20 [00:15<00:14, 1.42s/it]eval model:: 55%|█████▌ | 11/20 [00:16<00:12, 1.40s/it]eval model:: 60%|██████ | 12/20 [00:17<00:11, 1.39s/it]eval model:: 65%|██████▌ | 13/20 [00:19<00:09, 1.38s/it]eval model:: 70%|███████ | 14/20 [00:20<00:08, 1.38s/it]eval model:: 75%|███████▌ | 15/20 [00:21<00:06, 1.38s/it]eval model:: 80%|████████ | 16/20 [00:23<00:05, 1.38s/it]eval model:: 85%|████████▌ | 17/20 [00:24<00:04, 1.38s/it]eval model:: 90%|█████████ | 18/20 [00:25<00:02, 1.37s/it]eval model:: 95%|█████████▌| 19/20 [00:27<00:01, 1.37s/it]eval model:: 100%|██████████| 20/20 [00:28<00:00, 1.17s/it][2021/12/31 18:51:54] root INFO: metric eval ***************[2021/12/31 18:51:54] root INFO: acc:0.6035998792800241[2021/12/31 18:51:54] root INFO: norm_edit_dis:0.8053270782756357[2021/12/31 18:51:54] root INFO: fps:439.3796693669832INFO 2021-12-31 18:51:55,788 launch.py:311] Local processes completed.
七、结果预测
预测脚本使用预测训练好的模型,并将结果保存成txt格式,可以直接送到比赛提交入口测评,文件默认保存在output/rec/predicts_chinese_lite_v2.0.txt
1.提交内容与格式
本次比赛要求参赛选手必须提交使用深度学习平台飞桨(PaddlePaddle)训练的模型。参赛者要求以.txt 文本格式提交结果,其中每一行是图片名称和文字预测的结果,中间以 “t” 作为分割符,示例如下:
0.jpg文本0
2. infer_rec.py修改
with open(save_res_path, "w") as fout: #添加列头 fout.write('new_name' + "t" + 'value' +'n') for file in get_image_file_list(config['Global']['infer_img']): logger.info("infer_img: {}".format(file)) with open(file, 'rb') as f: img = f.read() data = {'image': img} batch = transform(data, ops) if config['Architecture']['algorithm'] == "SRN": encoder_word_pos_list = np.expand_dims(batch[1], axis=0) gsrm_word_pos_list = np.expand_dims(batch[2], axis=0) gsrm_slf_attn_bias1_list = np.expand_dims(batch[3], axis=0) gsrm_slf_attn_bias2_list = np.expand_dims(batch[4], axis=0) others = [ paddle.to_tensor(encoder_word_pos_list), paddle.to_tensor(gsrm_word_pos_list), paddle.to_tensor(gsrm_slf_attn_bias1_list), paddle.to_tensor(gsrm_slf_attn_bias2_list) ] if config['Architecture']['algorithm'] == "SAR": valid_ratio = np.expand_dims(batch[-1], axis=0) img_metas = [paddle.to_tensor(valid_ratio)] images = np.expand_dims(batch[0], axis=0) images = paddle.to_tensor(images) if config['Architecture']['algorithm'] == "SRN": preds = model(images, others) elif config['Architecture']['algorithm'] == "SAR": preds = model(images, img_metas) else: preds = model(images) post_result = post_process_class(preds) info = None if isinstance(post_result, dict): rec_info = dict() for key in post_result: if len(post_result[key][0]) >= 2: rec_info[key] = { "label": post_result[key][0][0], "score": float(post_result[key][0][1]), } info = json.dumps(rec_info) else: if len(post_result[0]) >= 2: info = post_result[0][0] + "t" + str(post_result[0][1]) if info is not None: logger.info("t result: {}".format(info)) # fout.write(file + "t" + info) # 格式化输出 fout.write(file + "t" + post_result[0][0] +'n') logger.info("success!")
In [11]
%cd ~/PaddleOCR/# mobile模型# !python tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml # -o Global.infer_img="/home/aistudio/data/data62843/test_images" # Global.pretrained_model="./output/rec_chinese_lite_v2.0/best_accuracy"# server模型!python tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml -o Global.infer_img="/home/aistudio/data/data62843/test_images" Global.checkpoints=./output/rec_chinese_common_v2.0/best_accuracy
预测日志
[2021/12/30 23:53:50] root INFO: result: 萧记果点0.66611135[2021/12/30 23:53:50] root INFO: infer_img: /home/aistudio/data/data62843/test_images/9995.jpg[2021/12/30 23:53:50] root INFO: result: 福0.1693737[2021/12/30 23:53:50] root INFO: infer_img: /home/aistudio/data/data62843/test_images/9996.jpg[2021/12/30 23:53:50] root INFO: result: 2790.97771764[2021/12/30 23:53:50] root INFO: infer_img: /home/aistudio/data/data62843/test_images/9997.jpg[2021/12/30 23:53:50] root INFO: result: 公牛装饰开关0.9916236[2021/12/30 23:53:50] root INFO: infer_img: /home/aistudio/data/data62843/test_images/9998.jpg[2021/12/30 23:53:50] root INFO: result: 专酒0.118371546[2021/12/30 23:53:50] root INFO: infer_img: /home/aistudio/data/data62843/test_images/9999.jpg[2021/12/30 23:53:50] root INFO: result: 东之家0.871051[2021/12/30 23:53:50] root INFO: success!......
八、基于预测引擎的预测
1.模型大小限制
约束性条件1:模型总大小不超过10MB(以.pdmodel和.pdiparams文件非压缩状态磁盘占用空间之和为准);
2.解决办法
训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。实际上,此处的约束条件限制的是inference 模型的大小。inference 模型一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成,模型大小也会小一些。
In [ ]
# 静态模型导出%cd ~/PaddleOCR/# mobile模型# !python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./output/rec_chinese_lite_v2.0/best_accuracy.pdparams Global.save_inference_dir=./inference/rec_inference/# server模型!python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_v2.0.yml -o Global.pretrained_model=./output/rec_chinese_common_train_v2.0/best_accuracy.pdparams Global.save_inference_dir=./inference/rec_inference/
/home/aistudio/PaddleOCRW1230 23:54:48.747483 13346 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1W1230 23:54:48.752360 13346 device_context.cc:465] device: 0, cuDNN Version: 7.6.[2021/12/30 23:54:52] root INFO: load pretrain successful from ./output/rec_chinese_lite_v2.0/best_accuracy[2021/12/30 23:54:54] root INFO: inference model is saved to ./inference/rec_inference/inference
In [ ]
%cd ~/PaddleOCR/!du -sh ./inference/rec_inference/
/home/aistudio/PaddleOCR5.2M./inference/rec_inference/
可以看到,当前训练使用的CRNN算法导出inference后,仅有5.2M。导出的inference模型也可以用来预测,预测逻辑如下代码所示。In [ ]
# 使用导出静态模型预测%cd ~/PaddleOCR/!python3.7 tools/infer/predict_rec.py --rec_model_dir=./inference/rec_inference/ --image_dir="/home/aistudio/data/A榜测试数据集/TestAImages"
预测日志
[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000001.jpg:('MJ', 0.2357887)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000002.jpg:('中门', 0.7167614)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000003.jpg:('黄焖鸡米饭', 0.7325407)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000004.jpg:('加行', 0.06699998)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000005.jpg:('学商烤面航', 0.40579563)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000006.jpg:('绿村装机 滋光彩机 CP口出国', 0.38243735)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000007.jpg:('有酸锁 四好吃', 0.38957664)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000008.jpg:('婚汽中海', 0.36037388)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000009.jpg:('L', 0.25453746)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000010.jpg:('清女装', 0.79736567)[2021/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000011.jpg:('幼小数学视食', 0.50577885)......
九、提交
预测结果保存到配置文件指定的 output/rec/predicts_chinese_lite_v2.0.txt文件,可直接提交即可。
In [12]
%cd ~!head PaddleOCR/output/rec/predicts_chinese_common_v2.0.txt
/home/aistudionew_namevalue0.jpg邦佳洗衣1.jpg不锈钢配件大全10.jpg诊疗科目:中医科100.jpg2101000.jpg电线电缆等1001.jpg201002.jpg进口滤纸 专业制造1003.jpg15065401004.jpgiWoW
1.mobile模型

2.server模型

大家可以再处理处理,优化优化,多跑几轮。
以上就是飞桨常规赛:中文场景文字识别- 12月第8名方案的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/49905.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫