之前我们提到 CNN 时,通常会认为是属于计算机视觉领域。但是在2014年,Yoon Kim 针对 CNN 的输入层做了一些变形,从而提出了文本分类模型 textCNN。由于 CNN 在计算机视觉中,常被用于提取图像的局部特征图,且起到了很好的效果,所以该作者将其引入到 NLP 中,应用于文本分类任务,试图使用 CNN 捕捉文本中单词之间的关系。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一文读懂textCNN模型原理
一、简介
之前我们提到 CNN 时,通常会认为是属于计算机视觉领域。但是在2014年,Yoon Kim 针对 CNN 的输入层做了一些变形,从而提出了文本分类模型 textCNN。由于 CNN 在计算机视觉中,常被用于提取图像的局部特征图,且起到了很好的效果,所以该作者将其引入到 NLP 中,应用于文本分类任务,试图使用 CNN 捕捉文本中单词之间的关系。
二、与传统 CNN 的不同
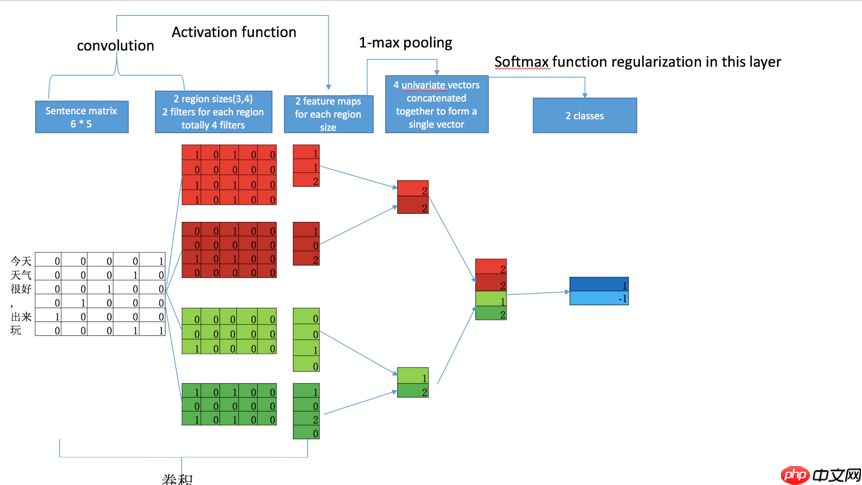
图一-textCNN架构
与传统图像的CNN网络相比, textCNN 在网络结构上没有任何变化,甚至更加简化了, 从图中可以看出textCNN 其实只有一层卷积,一层max-pooling, 最后将输出外接softmax 来n分类。
然而textCNN 最大的不同是在于输入数据的不同: 图像是二维甚至三维数据, 图像的卷积核是从左到右, 从上到下进行滑动来进行特征提取;自然语言是一维数据, 虽然经过word-embedding 生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义。比如 “今天” 对应的向量[0, 0, 0, 0, 1], 按窗口大小为 1 * 2 从左到右滑动得到[0,0], [0,0], [0,0], [0, 1]这四个向量, 对应的都是”今天”这个词汇, 这种滑动没有帮助。
TextCNN最大优势在于网络结构简单 ,在模型网络结构如此简单的情况下,通过引入已经训练好的词向量依旧有很不错的效果,在多项数据数据集上超越benchmark。网络结构简单导致参数数目少, 计算量少, 训练速度快,在单机单卡的v100机器上,训练165万数据, 迭代26万步,半个小时左右可以收敛。
三、模型架构简析
《Convolutional Neural Networks for Sentence Classification》一文中最早给出了文本CNN的基本结构,而后《A Sensitivity Analysis …》一文专门做了各种控制变量的实验对比。
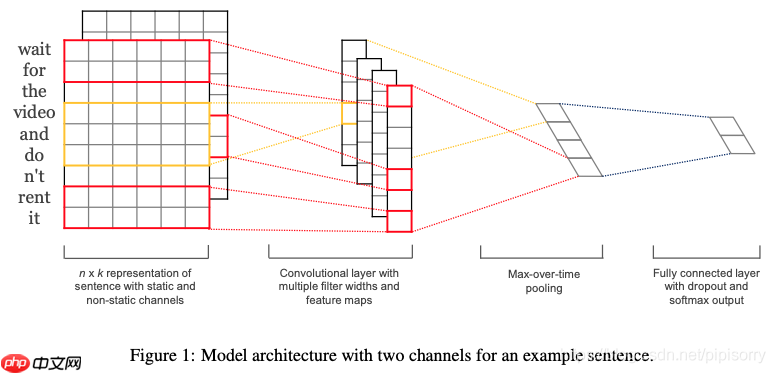
图二-《Convolutional Neural Networks for Sentence Classification》模型示意图
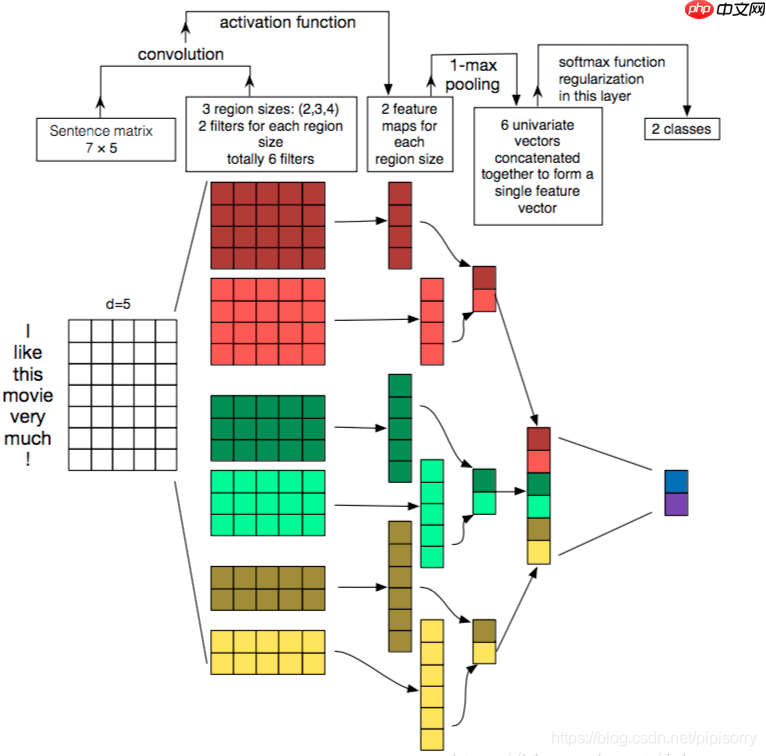
图三-《A Sensitivity Analysis …》[2]模型示意图
由于一条文本语句由 n 个词组成,而每个词又可以表示为一个 k 维的词向量,所以最初模型的输入可以看作是一个 n×k 的单通道图像。
之后经过卷积层处理。在卷积层中,选用了不同的卷积核来得到不同的特征图,且卷积核的宽度即词向量的维度 k,所以卷积在这里的作用是用于提取不同数量的单词构成的元组之间的关系,比如卷积核的大小为 3,那么则将相邻的三个词语当作是一个特征。
在上图一的第二个阶段可以看到,由于选用的卷积核宽度与词向量维度相同,所以最终得到的特征图也就表现为了 n 维向量,之后便是对得到的每一个特征图做一次max-pooling,并将max-pooling的结果作为全连接层的输入,并最终进行 Softmax 分类。
四、textCNN模型架构
我们仍以图一中文语句为例
(一)Word Embedding 分词构建词向量
如图一所示,textCNN 首先将 “今天天气很好,出来玩” 分词成”今天/天气/很好/,/出来/玩, 通过word2vec或者GLOV 等embedding 方式将每个词成映射成一个5维(维数可以自己指定)词向量, 如 “今天” -> [0,0,0,0,1], “天气” ->[0,0,0,1,0], “很好” ->[0,0,1,0,0]等等。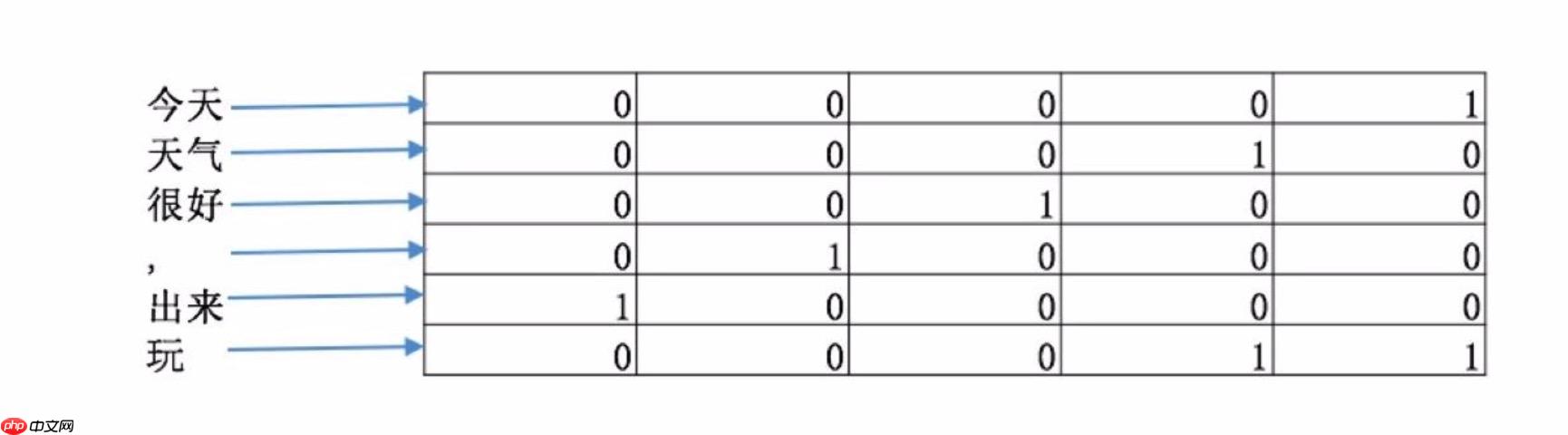
这样做的好处主要是将自然语言数值化,方便后续的处理。从这里也可以看出不同的映射方式对最后的结果是会产生巨大的影响, nlp 当中目前最火热的研究方向便是如何将自然语言映射成更好的词向量。我们构建完词向量后,将所有的词向量拼接起来构成一个6 * 5的二维矩阵,作为最初的输入。
(二)卷积池化层(convolution and pooling)
卷积(convolution)
文本卷积与图像卷积的不同之处在于只针对文本序列的一个方向(垂直)做卷积,卷积核的宽度固定为词向量的维度d。高度是超参数,可以设置。对句子单词每个可能的窗口做卷积操作得到特征图(feature map) c = [c_1, c_2, …, c_s-h+1]。
现在假设有一个卷积核,是一个宽度为d,高度为h的矩阵w,那么w有h∗d个参数需要被更新。对于一个句子,经过嵌入层之后可以得到矩阵AϵRs×d。 A[i:j]表示A的第i行到第j行, 那么卷积操作可以用如下公式表示: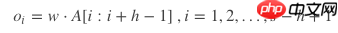
叠加上偏置b,在使用激活函数f激活, 得到所需的特征。公式如下: 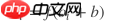
具体卷积计算参考博客文本分类算法TextCNN原理详解(一)
对于多通道(channel)的说明
在CNN 中常常会提到一个词channel, 图三 中 深红矩阵与 浅红矩阵 便构成了两个channel 统称一个卷积核, 从这个图中也可以看出每个channel 不必严格一样, 每个4 * 5 矩阵与输入矩阵做一次卷积操作得到一个feature map. 在计算机视觉中,由于彩色图像存在 R, G, B 三种颜色, 每个颜色便代表一种channel。 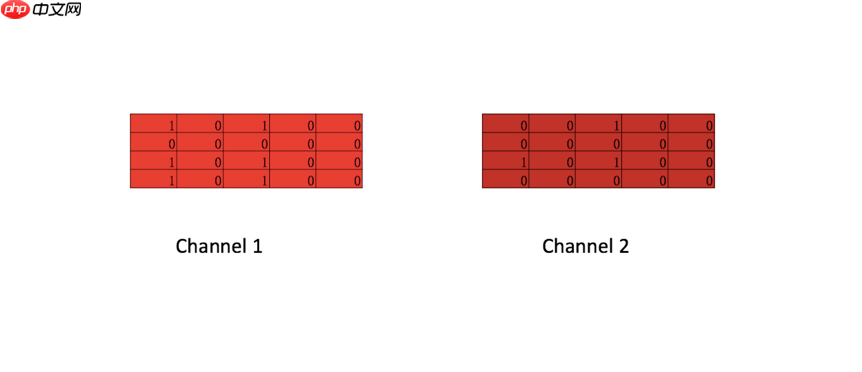
根据原论文作者的描述, 一开始引入channel 是希望防止过拟合(通过保证学习到的vectors 不要偏离输入太多)来在小数据集合获得比单channel更好的表现,后来发现其实直接使用正则化效果更好。
不过使用多channel 相比与单channel, 每个channel 可以使用不同的word embedding, 比如可以在no-static(梯度可以反向传播) 的channel 来fine tune 词向量,让词向量更加适用于当前的训练。
对于channel在textCNN 是否有用, 从论文的实验结果来看多channels并没有明显提升模型的分类能力, 七个数据集上的五个数据集 单channel 的textCNN 表现都要优于 多channels的textCNN。
最大池化(max-pooling)
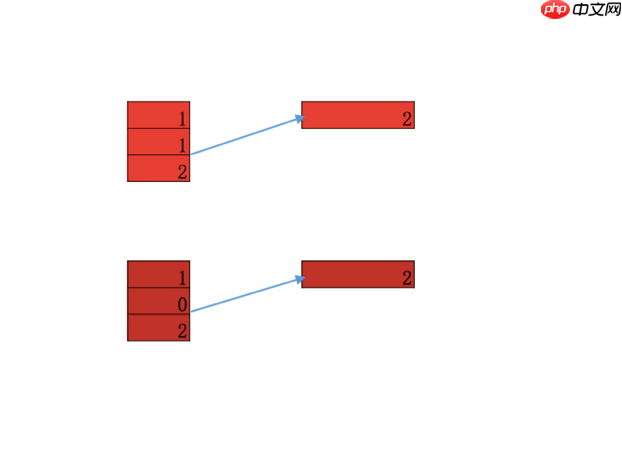
得到feamap = [1,1,2] 后, 从中选取一个最大值[2] 作为输出, 便是max-pooling。max-pooling 在保持主要特征的情况下, 大大降低了参数的数目, 从图五中可以看出 feature map 从 三维变成了一维, 好处有如下两点:
1、降低了过拟合的风险, feature map = [1, 1, 2] 或者[1, 0, 2] 最后的输出都是[2], 表明开始的输入即使有轻微变形, 也不影响最后的识别。
2、参数减少, 进一步加速计算。
pooling 本身无法带来平移不变性(图片有个字母A, 这个字母A 无论出现在图片的哪个位置, 在CNN的网络中都可以识别出来),卷积核的权值共享才能.
max-pooling的原理主要是从多个值中取一个最大值,做不到这一点。cnn 能够做到平移不变性,是因为在滑动卷积核的时候,使用的卷积核权值是保持固定的(权值共享), 假设这个卷积核被训练的就能识别字母A, 当这个卷积核在整张图片上滑动的时候,当然可以把整张图片的A都识别出来。
(三)优化与正则化
池化层后面加上全连接层和SoftMax层做分类任务,得到各个类别比如 label 为1 的概率以及label 为-1的概率。同时防止过拟合,一般会添加L2和Dropout正则化方法。最后整体使用梯度法进行参数的更新模型的优化。
五、案例与代码实现
本文案例参考飞桨项目THUCNews数据集使用TextCNN完成文本分类任务。案例采用 THUCNews 数据集,由清华大学自然语言处理实验室根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。其在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、cai票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。
(一)环境配置
In [1]
import pandas as pdimport numpy as npimport paddleimport paddle.nn as nnfrom paddle.io import DataLoader, Datasetimport paddle.optimizer as optimfrom paddlenlp.data import Padimport jiebafrom collections import Counter
(二)数据准备
In [2]
data = pd.read_csv("data/data45260/Train.txt", sep='t', names=['ClassNo', 'ClassName', 'Sentence'])print("Train Set")print(data.head())print(data.info())pred_data = pd.read_csv("data/data45260/Test.txt", sep='t', names=['Sentence'])print("Pred Set")print(pred_data.head())print(pred_data.info())
Train Set ClassNo ClassName Sentence0 0 财经 上证50ETF净申购突增1 0 财经 交银施罗德保本基金将发行2 0 财经 基金公司不裁员反扩军 走访名校揽人才3 0 财经 基金巨亏30亿 欲打开云天系跌停自救4 0 财经 基金市场周二缩量走低RangeIndex: 752476 entries, 0 to 752475Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 ClassNo 752476 non-null int64 1 ClassName 752476 non-null object 2 Sentence 752475 non-null objectdtypes: int64(1), object(2)memory usage: 17.2+ MBNonePred Set Sentence0 北京君太百货璀璨秋色 满100省353020元1 教育部:小学高年级将开始学习性知识2 专业级单反相机 佳能7D单机售价9280元3 星展银行起诉内地客户 银行强硬客户无奈4 脱离中国的实际 强压RMB大幅升值只能是梦想RangeIndex: 83599 entries, 0 to 83598Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Sentence 83599 non-null objectdtypes: object(1)memory usage: 653.2+ KBNone
In [3]
## 注意到训练集中语句与数据数目不匹配,需删除无效数据data.dropna(axis=0, how='any', inplace=True)X = data['Sentence'].valuesY = data['ClassNo'].valuesY_name = data['ClassName'][np.sort(np.unique(data['ClassName'], return_index=True)[1])].valuesY_dict = dict([val for val in zip(np.unique(Y), Y_name)])
数据预处理,中文语句的处理需要注意中文分词及停用词的去除。根据提供的中文停用词数据集,将其数据进行加载。然后使用 jieba 包提供的中文分词功能,将训练集的输入语句每一句首先进行分词,调用 jieba.lcut(s) 进行分词并且返回分词后的列表。对于列表中的每一个词语,查看是否在停用词表中出现,如果出现则将其删除。
In [4]
def preprocess(data): stopwords = open("data/data81223/stopwords.txt").read().split('n') new_data = [] for row in data: row = jieba.lcut(row) # 中文分词 new_row = [] for word in row: if word not in stopwords: new_row.append(word) new_data.append(new_row) return np.array(new_data)corpus = preprocess(X)print(corpus[42])
Building prefix dict from the default dictionary ...Dumping model to file cache /tmp/jieba.cacheLoading model cost 0.835 seconds.Prefix dict has been built successfully.
['跌停', '虽未', '打开', '交易', '已', '活跃', ' ', '基金', '市价', '估值', '云天化']
In [5]
## 构建词表def build_vocab(data): word2id = {} vocab = Counter() for row in data: vocab.update(row) vocab = sorted(vocab.items(), key=lambda x: x[1], reverse=True) vocab = [('', 0)] + list(vocab) + [('', 0)] word2id = {word[0]: i for i, word in enumerate(vocab)} return word2iddef get_ids(data, word2id): ids = [] for row in data: id_ = list(map(lambda x: word2id.get(x, word2id['']), row)) ids.append(id_) return np.array(ids)def padding(data): return Pad(pad_val=0)(data)word2id = build_vocab(corpus)ids = get_ids(corpus, word2id)padding_ids = padding(ids)print(padding_ids[42])print(padding_ids[56748])
[ 2181 80653 4283 170 37 1070 1 19 12830 879 29555 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0][ 1908 4439 319 25054 126 2642 329 13 20 213 231 6516 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
In [6]
## 重写Datasetclass MyDataset(Dataset): def __init__(self, X, Y): super(MyDataset, self).__init__() self.X = X self.Y = Y def __len__(self): return self.X.shape[0] def __getitem__(self, index): return self.X[index], self.Y[index]
In [7]
## 划分数据集————训练集、测试集、开发集def split(X, Y): idx = [i for i in range(0, X.shape[0])] np.random.shuffle(idx) train_len = int(0.9 * len(idx)) return X[idx[:train_len]], Y[idx[:train_len]], X[idx[train_len:]], Y[idx[train_len:]]train_X, train_Y, test_X, test_Y = split(padding_ids, Y)print("Train Set: ", train_X.shape, train_Y.shape)print("Test Set: ", test_X.shape, test_Y.shape)
Train Set: (677227, 75) (677227,)Test Set: (75248, 75) (75248,)
(三)模型搭建
In [8]
## 搭建模型class TextCNN(paddle.nn.Layer): def __init__(self, vocab_size, embedding_size, classes, pretrained=None, kernel_num=100, kernel_size=[3, 4, 5], dropout=0.5): super(TextCNN, self).__init__() self.vocab_size = vocab_size self.embedding_size = embedding_size self.classes = classes self.pretrained = pretrained self.kernel_num = kernel_num self.kernel_size = kernel_size self.dropout = dropout if self.pretrained != None: self.embedding = nn.Embedding(num_embeddings=self.vocab_size, embedding_dim=self.embedding_size, padding_idx=0 ,_weight=pretrained) else: self.embedding = nn.Embedding(num_embeddings=self.vocab_size, embedding_dim=self.embedding_size, padding_idx=0) self.convs = nn.LayerList([nn.Conv2D(1, self.kernel_num, (kernel_size_, embedding_size)) for kernel_size_ in self.kernel_size]) self.dropout = nn.Dropout(self.dropout) self.linear = nn.Linear(3 * self.kernel_num, self.classes) def forward(self, x): embedding = self.embedding(x).unsqueeze(1) convs = [nn.ReLU()(conv(embedding)).squeeze(3) for conv in self.convs] pool_out = [nn.MaxPool1D(block.shape[2])(block).squeeze(2) for block in convs] pool_out = paddle.concat(pool_out, 1) logits = self.linear(pool_out) return logits
In [9]
## 训练配置BATCH_SIZE = 50EMBEDDING_SIZE = 150LEARNING_RATE = 0.00005EPOCHS = 5 # 5device = paddle.device.get_device() #注意配置环境必须是GPU,否则以下训练程序将无法运行print(device)
gpu:0
In [10]
## 模型训练与评估Train_Loader = DataLoader(MyDataset(paddle.to_tensor(train_X), paddle.to_tensor(train_Y)), batch_size=BATCH_SIZE, shuffle=True)Test_Loader = DataLoader(MyDataset(paddle.to_tensor(test_X), paddle.to_tensor(test_Y)), batch_size=BATCH_SIZE, shuffle=True)model = TextCNN(vocab_size=len(word2id), embedding_size=EMBEDDING_SIZE, classes=len(Y_dict))print(model)optimizer = optim.Adam(parameters=model.parameters(), learning_rate=LEARNING_RATE)criterion = nn.CrossEntropyLoss()for epoch in range(0, EPOCHS): Train_Loss, Test_Loss = [], [] Train_Acc, Test_Acc = [], [] model.train() for i, (x, y) in enumerate(Train_Loader): x = x.cuda() y = y.cuda() pred = model(x) loss = criterion(pred, y) Train_Loss.append(loss.item()) Train_Acc.append(paddle.metric.accuracy(pred, y).numpy()) loss.backward() optimizer.step() optimizer.clear_grad() model.eval() for i, (x, y) in enumerate(Test_Loader): x = x.cuda() y = y.cuda() pred = model(x) Test_Loss.append(criterion(pred, y).item()) Test_Acc.append(paddle.metric.accuracy(pred, y).numpy()) print( "Epoch: [{}/{}] TrainLoss/TestLoss: {:.4f}/{:.4f} TrainAcc/TestAcc: {:.4f}/{:.4f}".format( epoch + 1, EPOCHS, np.mean(Train_Loss), np.mean(Test_Loss), np.mean(Train_Acc), np.mean(Test_Acc) ) )
W0221 10:12:08.730477 101 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1W0221 10:12:08.736320 101 device_context.cc:465] device: 0, cuDNN Version: 7.6.
TextCNN( (embedding): Embedding(249925, 150, padding_idx=0, sparse=False) (convs): LayerList( (0): Conv2D(1, 100, kernel_size=[3, 150], data_format=NCHW) (1): Conv2D(1, 100, kernel_size=[4, 150], data_format=NCHW) (2): Conv2D(1, 100, kernel_size=[5, 150], data_format=NCHW) ) (dropout): Dropout(p=0.5, axis=None, mode=upscale_in_train) (linear): Linear(in_features=300, out_features=14, dtype=float32))Epoch: [1/5] TrainLoss/TestLoss: 0.6914/0.3004 TrainAcc/TestAcc: 0.8045/0.9109Epoch: [2/5] TrainLoss/TestLoss: 0.2333/0.2359 TrainAcc/TestAcc: 0.9311/0.9292Epoch: [3/5] TrainLoss/TestLoss: 0.1707/0.2199 TrainAcc/TestAcc: 0.9486/0.9337Epoch: [4/5] TrainLoss/TestLoss: 0.1364/0.2162 TrainAcc/TestAcc: 0.9585/0.9347Epoch: [5/5] TrainLoss/TestLoss: 0.1125/0.2177 TrainAcc/TestAcc: 0.9657/0.9356
In [11]
## 保存模型paddle.save(model.state_dict(), "TextCNN.pdparams")paddle.save(optimizer.state_dict(), "Adam.pdparams")
(四)预测数据与效果检测
In [12]
## 预测数据准备pred_X = pred_data['Sentence'].valuespred_corpus = preprocess(pred_X)pred_ids = get_ids(pred_corpus, word2id)pred_padding_ids = padding(pred_ids)print(pred_padding_ids.shape)## 预测过程,并将预测结果按照输入的训练集形式进行了保存Pred_Loader = DataLoader(MyDataset(paddle.to_tensor(pred_padding_ids), paddle.to_tensor(pred_padding_ids)), batch_size=BATCH_SIZE, shuffle=False)model.eval()pred_Y = []for i, (x, y) in enumerate(Pred_Loader): x = x.cuda() pred = model(x) label = np.argmax(pred, axis=1) pred_Y += list(label)## 可视化一些文本的预测结果pred_Name = [Y_dict[name] for name in pred_Y]MyPred = pd.DataFrame({'ClassNo': pred_Y, 'ClassName': pred_Name, 'Sentence': pred_X})print(MyPred.head())MyPred.to_csv('pred.csv', index=False)
(83599, 75) ClassNo ClassName Sentence0 3 股票 北京君太百货璀璨秋色 满100省353020元1 5 教育 教育部:小学高年级将开始学习性知识2 6 科技 专业级单反相机 佳能7D单机售价9280元3 3 股票 星展银行起诉内地客户 银行强硬客户无奈4 3 股票 脱离中国的实际 强压RMB大幅升值只能是梦想
(五)封装功能 自定义文本输入
In [16]
model_params = paddle.load('TextCNN.pdparams')model_infer = TextCNN(vocab_size=len(word2id), embedding_size=EMBEDDING_SIZE, classes=len(Y_dict))model_infer.set_state_dict(model_params)sentence = input()infer_corpus = preprocess([sentence])infer_ids = get_ids(infer_corpus, word2id)infer_padding_ids = padding(infer_ids)model_infer.eval()val = model_infer(paddle.to_tensor(infer_padding_ids))label = np.argmax(val, axis=1)[0]print("Sentence: ", sentence, " label: ", Y_dict[label])
Sentence: 再次点球失手!如何评价梅西现在的踢球水平? label: 体育
以上就是【AI达人创造营第二期】一文读懂textCNN模型原理的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/50386.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫