
该方案为飞桨遥感影像地块分割赛题10月第2名方案,借鉴榜首模型结构,采用HRNet_W48+OCRNet,loss结合LovaszSoftmax和CrossEntropy。数据集经处理剔除无效样本,用多种增强策略。训练用Momentum优化器等,预测选50轮模型,提分点含数据增强等。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

飞桨常规赛:遥感影像地块分割
10月第2名方案
赛题
本赛题旨在对遥感影像进行像素级内容解析,并对遥感影像中感兴趣的类别进行提取和分类,以衡量遥感影像地块分割模型在多个类别(如建筑、道路、林地等)上的效果。
数据共包括4种分类,像素值分别为0、1、2、3。此外,像素值255为未标注区域,表示对应区域的所属类别并不确定,在评测中也不会考虑这部分区域。
训练集包含66,653张遥感影像图片和对应的标注图片,测试集包括4,609张遥感影像图片。遥感分辨率均为2m/pixel,图片尺寸均为256*256。
示例图片:



解题思路
主要借鉴了当前榜首(戳这里查看方案)的模型结构,但由于实现细节的差异,分数还是低了不少。
和榜首方案不同的是,个人比较偏好API编程的模式。
模型
模型采用了HRNet_W48+OCRNet,loss采用LovaszSoftmax和CrossEntropy(详见my_model.py)。
backbone = paddleseg.models.backbones.HRNet_W48(pretrained='https://bj.bcebos.com/paddleseg/dygraph/hrnet_w48_ssld.tar.gz', has_se=False)model = paddleseg.models.OCRNet(num_classes=4,backbone=backbone,backbone_indices=[-1],ocr_mid_channels=512,ocr_key_channels=256, pretrained='https://bj.bcebos.com/paddleseg/dygraph/ccf/fcn_hrnetw48_rs_256x256_160k/model.pdparams')
ce_coef = 1.0lovasz_coef = 0.3main_loss = lovasz_coef*self.lovasz(yp[0], yt)+ce_coef*self.ce(yp[0], yt)soft_loss = lovasz_coef*self.lovasz(yp[1], yt)+ce_coef*self.ce(yp[1], yt)return 1.0*main_loss+0.4*soft_loss
数据集
数据集采用了paddle.io.Dataset包装,方便采用paddle.io.DataLoader实现组batch和并行预处理,能够提高训练效率。
在数据集中调用paddle.vision.transforms实现数据增强,采用的增强策略有颜色抖动、随机旋转、随机翻转、随机crop等。
另外,发现训练集中有大约5000余张样本对应的标签完全由255组成,他们对训练不会有任何收益,故构造数据集时将相应的样本剔除。
代码详见my_dataset.py
训练策略
优化器为Momentum,学习率策略为PolynomialDecay和LinearWarmup。其他训练参数为:
BATCH_SIZE = 32LR = 1e-3WARMUP_EPOCH = 10 # warmup轮数TRAIN_EPOCHS = 40 # 训练轮数EVAL_EPOCH = 2 # 每两轮验证一次
训练主函数见train.py
学习率变化曲线 loss曲线
loss曲线 miou曲线
miou曲线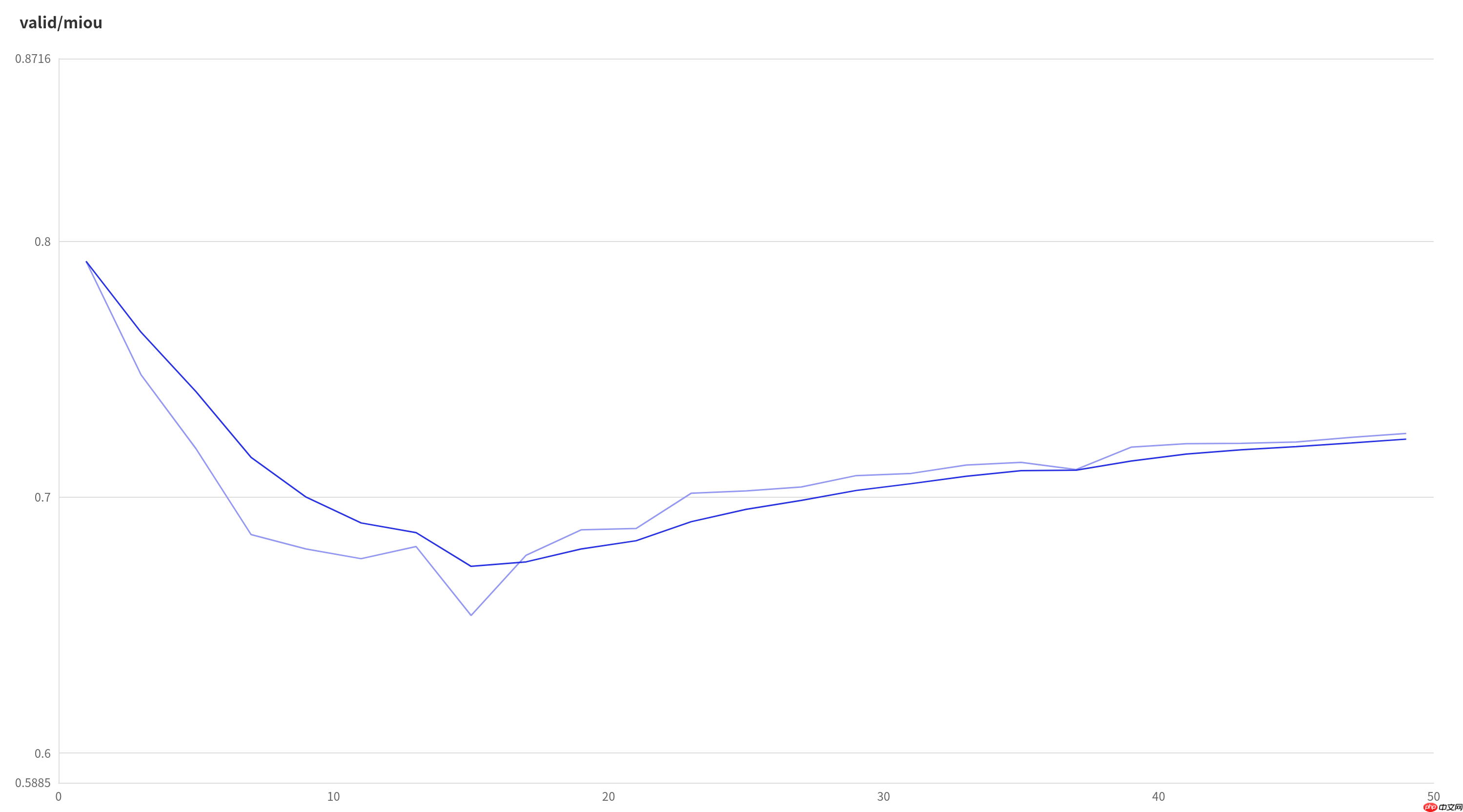
预测
训练时有一个很奇怪的现象,验证集的miou曲线是一个先降后升的’U’型。采用验证集最优模型的话,提交结果不如最后一轮,所以预测时加载的模型是训练50轮的参数。
预测时使用with paddle.no_grad():或者@paddle.no_grad()装饰器可以在推理时不保存中间结果,节省巨量显存。当然AI Studio的V100显卡太强了,有没有都无所谓。
推理时把数据集用DataLoader包装一下可以更好的并行。
预测后在左侧直接右键result文件夹,选择’打包下载’即可直接下载zip压缩包,可以直接在比赛页面提交。奇怪,前两天用的时候好像还是英文’Download as zip archive’,现在就变成中文了。
具体代码见predict.py。
代码说明
代码都放在work文件夹下,结果也都保存在work/result文件夹下,模型保存在models文件夹下。
configs.py全局参数设置my_dataset.py构造数据集my_model.py构造模型predict.py预测并保存结果train.py训练模型utils.py一些工具函数
模块文件下都通过
if __name__=='__main__': ...
的形式编写了一些测试语句,方便调试。
总结
四月份的时候参加过一轮,当时手攒了个模型,没有利用好paddleseg这个好用的套件,分数很低,该做好的点没有做好。感觉提分点主要有以下这些吧:
数据增强。一般来说,常规的数据增强都会有些效果,也可以根据数据的特点进行一定的取舍;SOTA模型。自己攒模型一般还是不如用现成的,尤其是对于新手。学到一定程度以后可以看看源码对比一下论文,说不定以后自己也能提出一些改进呢;预训练模型。不多说了,有没有预训练简直是两个模型;结果后处理。按之前的经验,语义分割类的结果做个滤波会有一点点不大的提升;另外,TTA据说很强。这里我还没来得及试。
和榜首的差距可能主要还是在数据增强策略上,另外,自己用API手写的训练过程可能还是有些细节上没实现好,还需要多学习学习。
一键复现
In [ ]
# 安装paddleseg和解压数据集。!pip install paddleseg==2.3.0!cd data/data77571/ && unzip -q train_and_label.zip!cd data/data77571/ && unzip -q img_test.zip
In [ ]
# 训练!cd work && python train.py
In [ ]
# 预测!cd work && python predict.py
以上就是飞桨常规赛:遥感影像地块分割 – 10月第2名方案的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/51480.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























