
该项目针对点击反欺诈二分类任务,通过数据分析发现android_id、语言特征影响大,时间特征影响小。构建了DCN、xDeepFM、MaskNet等模型,对比效果后选择表现佳的模型,经参数调整和模型融合优化,最终生成提交文件,完成欺诈点击识别。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

目录
项目说明比赛介绍思路分析数据分析模型构建模型调整其他项目代码超参定义特征-嵌入 表构建加载训练数据分割训练集和验证集建立dataset类,加载dataloader模型搭建模型实例化训练及验证函数定义模型训练绘制损失及acc曲线加载测试集数据并进行推断生成提交文件
1.项目说明
比赛介绍
目标:点击反欺诈数据:给定点击的特征,输出是否为欺诈的点击(0或1)分析:二分类任务、点击率预估
思路分析
三段式:数据分析 + 模型构建 + 模型调整
数据分析
时间戳特征对于时间戳特征,原始读入数据类型为字符串类型,无法直接用于模型训练,因此首先将其转换为datetime类型数据,之后再分别提取出年、月、日、时、分、秒、工作日属性。 分析发现,数据集中的时间全部在2019年6月2日至6月9日之间。因此,可以用到的时间特征就只有日(day)、时(hour)、分(minute)、秒(second)以及工作日(weekday)。下面对各个时间属性进行分析。 工作日属性。绘制正负样本的工作日分布情况,如图1所示。由图1可知,在weekday属性上,正负样本分布基本一致,因此可以猜想,如果单独加入weekday属性用于分类,那么对结果影响并不会太大。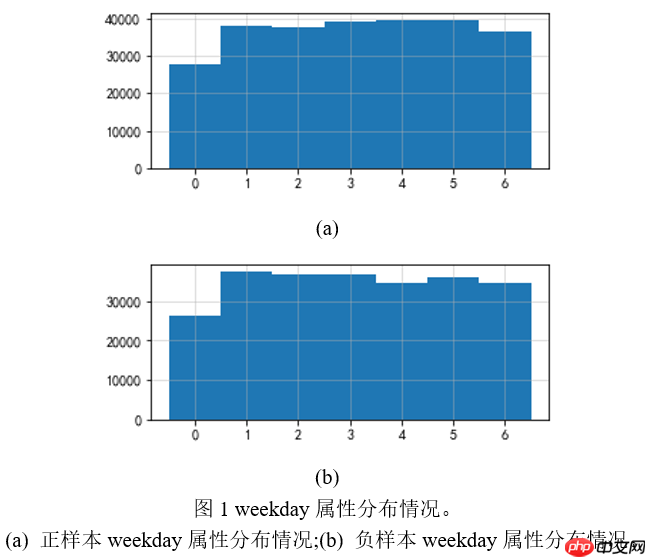 同样的,分别对于day、hour、minute、second作类似分析,可以得到图2所示分布情况。
同样的,分别对于day、hour、minute、second作类似分析,可以得到图2所示分布情况。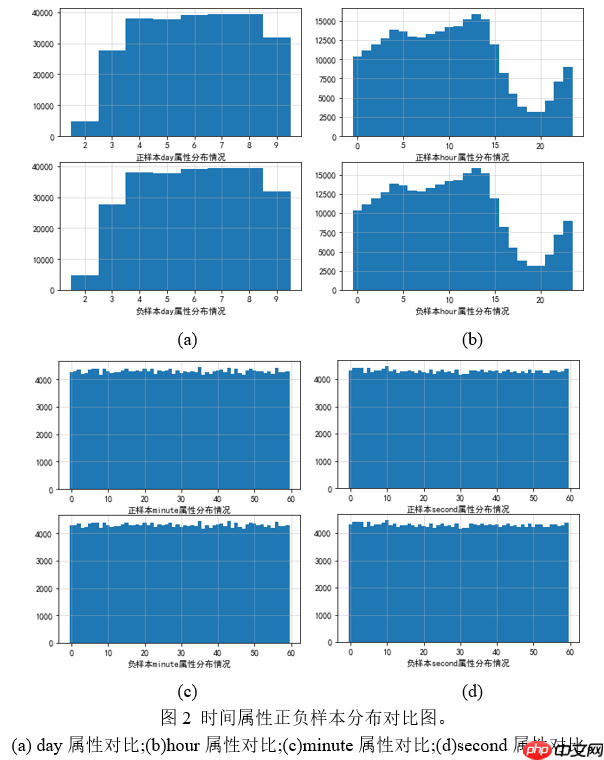 综上可以看出,单独的时间属性对于最终结果的影响基本不可见。Android_id特征这里主要分析android_id的出现频度,在一定程度上可以反应出不同设备出现的活跃度。按照android_id对数据集进行分组,可以发现在全部数据中,仅出现一次的设备id有455471个,而多次出现的id仅有12487条。由此可见,绝大多数设备在统计数据期间仅仅出现一次,也就意味着这些用户活跃度相对较低。对于出现超过1次的相对活跃用户来分析其行为中存在的欺诈比例,可以得出图3的结果。
综上可以看出,单独的时间属性对于最终结果的影响基本不可见。Android_id特征这里主要分析android_id的出现频度,在一定程度上可以反应出不同设备出现的活跃度。按照android_id对数据集进行分组,可以发现在全部数据中,仅出现一次的设备id有455471个,而多次出现的id仅有12487条。由此可见,绝大多数设备在统计数据期间仅仅出现一次,也就意味着这些用户活跃度相对较低。对于出现超过1次的相对活跃用户来分析其行为中存在的欺诈比例,可以得出图3的结果。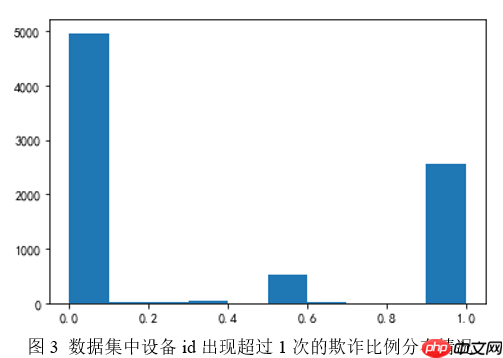 由图3可以看出,对于在数据集中出现超过一次的设备id来说,绝大多数要么全部欺诈,要么全部非欺诈。而这些设备中,部分欺诈部分非欺诈的占比不足8%。由此可以了解到android_id对于最终的结果判断会有很大影响。对于仅在数据集中出现一次的设备id来讲,欺诈比例大约为45%。语言特征语言特征中存在空值,因此分别计算正负样本中空值的出现比例可以得出正样本中空值的比例超过50%,而负样本中出现空值的比例仅为18%。由此可知该特征对于最终结果的影响也会比较大。
由图3可以看出,对于在数据集中出现超过一次的设备id来说,绝大多数要么全部欺诈,要么全部非欺诈。而这些设备中,部分欺诈部分非欺诈的占比不足8%。由此可以了解到android_id对于最终的结果判断会有很大影响。对于仅在数据集中出现一次的设备id来讲,欺诈比例大约为45%。语言特征语言特征中存在空值,因此分别计算正负样本中空值的出现比例可以得出正样本中空值的比例超过50%,而负样本中出现空值的比例仅为18%。由此可知该特征对于最终结果的影响也会比较大。
模型构建
模型选择在模型选择上,根据特征交互方式的不同,将模型分为了三类分别实现以验证效果。第一类:Wide&Deep系列。DCN模型可以算是该系列比较经典的模型。其特点在于结合了Deep部分提取深度特征交互信息和Cross部分提取浅层交互信息的功能,相当于使得模型同时具备的记忆能力和探索能力。第二类:xDeepFM系列。其实xDeepFM和DeepFM也算是Wide&Deep的一种分支,但是区别在于Wide&Deep部分的特征交互仅仅存在于bit-wise式的交互,而没有vector-vise形式的交互,因此这里单独将其拿出来作为一类。第三类:MaskNet。MaskNet的结构与设计初衷和Transformer非常像,简直是Transformer在点击率预估部分的一个翻版。其设计的实例指导的Mask模块的作用完全可以看做是一种Attention机制,也正是该模块使得MaskNet能够比上面两类有更好的效果。对三类模型分别进行实现,然后对比各种模型的效果。对数据集进行9:1的划分。在验证集上,MaskNet相比于前两类模型确实取得了更好的结果。
模型调整
参数选择对于嵌入维度,分别对比了16,32,64,发现当嵌入维度为32时,结果会更好一些。对于初始学习率,分别对比了0.01, 0.001, 0.0001,发现当初始学习率设为0.001时,网络更容易快速收敛。模型改进对于语言特征,存在诸如’zh-CN’, ‘zh’, ‘cn’, ‘Zh-CN’, ‘zh_CN’, ‘zh-cn’, ‘ZH’等表示意义相同的取值,因此刚开始将这些值进行了合并,统一为了同一种取值,然而经过模型验证发现,将每个值单独作为一种取值的预测结果要比对其合并的结果要更好一些。对于嵌入维度,因为第二类模型需要保证每个特征嵌入维度相同,所以所有嵌入维度都设置为32。但是考虑到有的特征的取值很多,而有的特征取值很少,将所有的特征均设为相同嵌入维度显然并不合理,因此对于第一类和第三类模型则分别根据不同的取值数量进行了不同维度的嵌入,通过实验也验证了这一点的有效性。模型融合考虑到不同模型可能存在不同的预测偏差,因此对不同的模型进行了融合。在实验过程中,对MaskNet的并行结构和序列结构进行了融合。对于融合模型,采用了共享embedding层的方式,之后经过各自的网络结构之后取出各自最后一层隐层进行拼接然后进行预测。最终实验效果也确实比单个模型要好。
其他
在数据处理方面,将所有的特征都看做了类别特征,因此对所有的特征都进行了嵌入。对于缺失值,则填充了”unk”值,使所有的缺失值作为单独一类。使用0.001学习率训练到模型振荡时,将学习率降为0.0001再进行少量训练可以得到更好的效果。
2.项目代码
In [ ]
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport gcimport datetimeimport timefrom sklearn.preprocessing import LabelEncoderfrom sklearn.model_selection import train_test_splitimport pickleimport warnings warnings.filterwarnings('ignore')
In [ ]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Fimport paddle.optimizer as optimfrom paddle.io import Dataset, DataLoader
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
超参定义
In [ ]
# DATA_PATH = "data/data79052/"DATA_PATH = "work/data/"BATCH_SIZE = 256 # 128USE_ALL_DATA = FalseUSE_TIME = True # 是否使用时间特征EMB_DIM = 32 # 嵌入维度 16REDUCE_RATIO = 2 # 先扩大一倍再降回来MB_NUMS = 3 # MaskBlocks数量 5
In [ ]
# xDeepFM相关参数CIN_EMB_DIM = 32 # 32CIN_H_0 = 22 # 原始特征数量CIN_HK_LIST = [256, 128, 64] # [100, 100, 50]
In [ ]
def reduce_mem_usage(df, use_uint=True, verbose=True): """ 节约内存函数 :param df: 原始从文件中读取出来的df数据 :param use_uint: 是否使用无符号整型处理数据 :param verbose: 是否打印输出处理前后内存占用情况 :return: 处理后的df """ numerics = ['uint8', 'uint16', 'uint32', 'uint64', 'int8', 'int16', 'int32', 'int64', 'float16', 'float32', 'float64'] start_mem = df.memory_usage().sum() / 1024**2 for col in df.columns: col_type = df[col].dtypes if col_type in numerics: c_min = df[col].min() c_max = df[col].max() if 'int' in str(col_type): if use_uint and c_min >= 0: # uint类型 if c_max <= np.iinfo(np.uint8).max: df[col] = df[col].astype(np.uint8) elif c_max <= np.iinfo(np.uint16).max: df[col] = df[col].astype(np.uint16) elif c_max = np.iinfo(np.int8).min and c_max = np.iinfo(np.int16).min and c_max = np.iinfo(np.int32).min and c_max = np.finfo(np.float16).min and c_max = np.finfo(np.float32).min and c_max <= np.finfo(np.float32).max: df[col] = df[col].astype(np.float32) else: df[col] = df[col].astype(np.float64) end_mem = df.memory_usage().sum() / 1024**2 if verbose: print('StartMem:{:.2f}Mb, EndMem:{:.2f}Mb ({:.1f}% reduction)'.format(start_mem, end_mem, 100 * (start_mem - end_mem) / start_mem)) return df
特征种类-嵌入维度 表构建
In [ ]
# 特征列名称feat_list = ['android_id', 'media_id', 'package', 'apptype', 'version', 'fea_hash', 'fea1_hash', 'cus_type', 'location', 'carrier', 'dev_height', 'dev_width', 'dev_ppi', 'lan', 'ntt', 'osv', 'os'] # 各特征对应种类数cardi = [467958, 292, 2102, 89, 23, 509473, 6147, 58, 332, 5, 864, 382, 105, 25, 8, 165, 2]if USE_TIME: feat_list.extend(["day", "weekday", "hour", "minute", "second"]) cardi.extend([8, 7, 24, 60, 60])# 特征列:种类数 对应字典cardi_dict = dict(zip(feat_list, cardi)) # 嵌入维度列表(嵌入维度 = 6 * (原始种类数^0.25))emb_dim_list = [6 * np.int(np.power(c, 0.25)) for c in cardi]#[EMB_DIM for c in cardi]# 构建 原始维度:嵌入维度 对应列表emb_dim_dict = list(zip(cardi, emb_dim_list)) # 每个特征域使用自己的嵌入维度emb_samedim_dict = list(zip(cardi, [EMB_DIM] * len(cardi))) # 每个特征域是哟明相同的嵌入维度,便于基于vector-wise的特征交互# 计算嵌入总维度EMB_OUT_SIZE = sum(emb_dim_list) EMB_SAMEOUT_SIZE = EMB_DIM * len(cardi)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:13: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations del sys.path[0]
加载训练数据
In [ ]
if USE_TIME: train = pd.read_csv(DATA_PATH + "lbe_raw_train_with_time.csv")else: train = pd.read_csv(DATA_PATH + "lbe_raw_train.csv")train = reduce_mem_usage(train, use_uint=False)
StartMem:95.37Mb, EndMem:22.89Mb (76.0% reduction)
分割训练集和验证集
In [ ]
def getTrain(df, use_all): """ 分割训练集和验证集 :param df:全量训练数据 :param use_all:是否使用全量训练数据 :return:训练集特征, 验证集特征, 训练集标签, 验证集标签 """ if use_all: X_train, X_valid, y_train, y_valid = train[feat_list].values, None, train["label"].values, None else: X_train, X_valid, y_train, y_valid = train_test_split(train[feat_list].values, train["label"].values, test_size=0.1, random_state=2021) # 0.1 return X_train, X_valid, y_train, y_valid
In [ ]
X_train, X_valid, y_train, y_valid = getTrain(train, USE_ALL_DATA)
建立dataset类,创建dataloader
In [ ]
class MyDataset(Dataset): def __init__(self, data_x, data_y): super(MyDataset, self).__init__() self.data_x = data_x self.data_y = data_y def __len__(self): return self.data_y.shape[0] def __getitem__(self, idx): return self.data_x[idx].astype(np.int), self.data_y[idx]
In [ ]
train_dataset = MyDataset(X_train, y_train)if not USE_ALL_DATA: valid_dataset = MyDataset(X_valid, y_valid)
In [ ]
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)if not USE_ALL_DATA: valid_loader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=False)
模型搭建
MaskNet(参考论文链接)
In [ ]
class IGM(nn.Layer): """ 实例指导的Mask模块。分为两层fc,第一层将数据扩大至中间维度,第二层将中间维度投影回原始维度 :param reduce_r: 中间层缩减比例(原始维度 / 中间层维度) :param input_size: 原始输入维度 """ def __init__(self, reduce_r, input_size): super(IGM, self).__init__() mid_size = input_size * reduce_r self.agg_layer = nn.Linear(input_size, mid_size) # 先扩大至中间维度 self.proj_layer = nn.Linear(mid_size, input_size) # 再降维至原始维度 def forward(self, x): x = self.agg_layer(x) x = self.proj_layer(x) return x
In [ ]
class MaskBlock(nn.Layer): """ MaskBlock,MaskNet的组成部分。每个MaskBlock由一个IGM和一个隐层组成。 :param emb_out_size: 嵌入层输出总维度 :param igm_reduce_r: IGM的缩减率 :param hid_size: 隐层维度,默认为-1,此时隐层维度设置为和嵌入层输出维度相同 :param mode:MaskBlock的类型,可选参数为'emb'和'mb' "emb":MaskBlock on feature embedding "mb":MaskBlock on MaskBlock """ def __init__(self, emb_out_size, igm_reduce_r, hid_size=-1, mode="emb"): super(MaskBlock, self).__init__() self.mode = mode # 用于区分两种不同结构的MaskBlock # 三个关键部分:LN, IGM, FFH if mode == "emb": self.LN_EMB = nn.LayerNorm(emb_out_size) self.IGM = IGM(reduce_r=igm_reduce_r, input_size=emb_out_size) if hid_size == -1: hid_size = emb_out_size self.hid_layer = nn.Linear(emb_out_size, hid_size) self.LN_HID = nn.LayerNorm(hid_size) def forward(self, x_left, x_right): if self.mode == "emb": ln_emb_out = self.LN_EMB(x_left) else: ln_emb_out = x_left igm_out = self.IGM(x_right) out = F.relu(self.LN_HID(self.hid_layer(ln_emb_out * igm_out))) return out
In [ ]
class EmbLayer(nn.Layer): """ 嵌入层 :param emb_dict:list, [(cardi:emb_dim), ...] :param concat_axis: -1 -> 横向(形成一个向量) 0 -> 纵向(形成一个矩阵) None -> 不拼接,直接返回嵌入list return: 各个域嵌入之后的结果 """ def __init__(self, emb_dict, concat_axis=-1): super(EmbLayer, self).__init__() self.field_num = len(emb_dict) self.concat_axis = concat_axis self.emb_list, self.emb_out_size = self.createEmb_list(emb_dict) def createEmb_list(self, emb_dict): emb_list = nn.LayerList() emb_out_size = 0 for cardi_num, emb_dim in emb_dict: emb_list.append(nn.Embedding(cardi_num, emb_dim)) emb_out_size += emb_dim return emb_list, emb_out_size def forward(self, x): if self.concat_axis is None: return [self.emb_list[i](x[:, i]) for i in range(len(self.emb_list))] y = paddle.concat([self.emb_list[i](x[:, i]) for i in range(len(self.emb_list))], axis=-1) if self.concat_axis != -1: y = paddle.reshape(y, shape=[x.shape[0], self.field_num, -1]) return y
In [ ]
class MLP(nn.Layer): """ MLP层 :param mlp_size_list: list, MLP各层尺寸 :param bn: bool, 是否使用batch normalization :param drop_out: 0-1/None, 丢弃比例, 默认0.5 """ def __init__(self, mlp_size_list, bn=False, drop_out=0.5): super(MLP, self).__init__() self.bn = bn self.drop_out = drop_out self.fc_layers = self.createFCLayers(mlp_size_list) def createFCLayers(self, mlp_size_list): fc_layers = nn.LayerList() if self.bn: self.bn_layers = nn.LayerList() if isinstance(self.drop_out, float): self.drop_out_layers = nn.LayerList() for idx in range(len(mlp_size_list)-1): fc_layers.append(nn.Linear(mlp_size_list[idx], mlp_size_list[idx+1])) if self.bn: self.bn_layers.append(nn.BatchNorm1D(mlp_size_list[idx+1])) if isinstance(self.drop_out, float): self.drop_out_layers.append(nn.Dropout(p=self.drop_out)) return fc_layers def forward(self, x): for idx, fc in enumerate(self.fc_layers): x = fc(x) if self.bn: x = self.bn_layers[idx](x) if isinstance(self.drop_out, float): x = self.drop_out_layers[idx](x) x = F.relu(x) return x
In [ ]
class ParaMaskNet(nn.Layer): """ 并行结构MaskNet :param emb_dict: list, [(原始cardi数量:嵌入维度), ...] :param igm_reduce_r_list: 每个MB对应一个IGM, 因此其长度即为MB的数量,每个值为对应的IGM中缩减率 :param mb_hid_list: 每个MB对应一个hidden层,每个值为对应的隐层数量,如果不单独设置可以全部赋值为-1,此时输出和输入维度相同 :param mlp_size_list: DNN隐层维度列表 :param emb_out_size: 嵌入层输出总维度 :param use_self_emb: 是否使用自己的嵌入层 :param use_last_fc: 是否使用最后一层全连接 :return: 并行结构的MaskNet实例 """ def __init__(self, emb_dict, igm_reduce_r_list, mb_hid_list, mlp_size_list, emb_out_size=EMB_OUT_SIZE, use_self_emb=True, use_last_fc=True): super(ParaMaskNet, self).__init__() self.emb_out_size = emb_out_size self.use_last_fc = use_last_fc self.use_self_emb = use_self_emb if use_self_emb: self.emb_layer = EmbLayer(emb_dict, concat_axis=None) self.mb_list, self.mb_out_size = self.createMBlist(igm_reduce_r_list, mb_hid_list) mlp_size_list.insert(0, self.mb_out_size) # mb层的输出之后即为mlp层 self.mlp = MLP(mlp_size_list, bn=True, drop_out=0.5) self.last_input_dim = mlp_size_list[-1] # 最后一层fc的输入维度 if self.use_last_fc: self.fc = nn.Linear(self.last_input_dim, 1) def createMBlist(self, igm_reduce_r_list, mb_hid_list): """ 构建MaskBlock模块 :param igm_reduce_r_list: 每个MB对应的缩减率列表 :param mb_hid_list: 每个MB对应的隐层维度列表 :return: 创建好的包含若干MB的LayerList """ mb_list = nn.LayerList() mb_out_size = 0 # 统计所有MB模块的总输出维度 for i in range(len(igm_reduce_r_list)): mb_list.append(MaskBlock(self.emb_out_size, igm_reduce_r_list[i], mb_hid_list[i])) # mb_out_size += self.emb_out_size if mb_hid_list[i] == -1 else mb_hid_list[i] return mb_list, mb_out_size def forward(self, x): # 如果使用自己的嵌入层,则将当前数据跑一边自己的嵌入层 if self.use_self_emb: x = self.emb_layer(x) # 此时x默认是未经concat的emb_list,这里进行横向拼接,形成一个长的嵌入向量 x = paddle.concat(x, axis=-1) # 依次经过MB模块并对结果进行拼接,依旧形成一个长的嵌入向量 x = paddle.concat([self.mb_list[i](x, x) for i in range(len(self.mb_list))], axis=-1) # 将MB层的输出接入MLP层 x = self.mlp(x) # 如果使用自身的最后一层则直接出最终计算结果,否则返回最后一层隐层的数据 if self.use_last_fc: x = self.fc(x) return F.sigmoid(x) return x
In [ ]
class ModifyParaMaskNet(nn.Layer): """ 对并行MaskNet结构进行改造,原来的模块都是利用基于bit-wise的交互方式,尝试加入vector-wise的交互方式 emb_dict: 原始cardi数量:嵌入维度 igm_reduce_r_list: 每个MB对应一个IGM, 因此其长度即为MB的数量,每个值为对应的IGM中缩减率 mb_hid_list: 每个MB对应一个hidden层,每个值为对应的隐层数量,如果不单独设置可以全部赋值为-1 mlp_size_list: DNN隐层维度列表 """ def __init__(self, emb_dict, igm_reduce_r_list, mb_hid_list, cin_hk_list, mlp_size_list, emb_out_size=EMB_OUT_SIZE, use_self_emb=True, use_last_fc=True): super(ModifyParaMaskNet, self).__init__() self.emb_out_size = emb_out_size self.use_last_fc = use_last_fc self.use_self_emb = use_self_emb if use_self_emb: self.emb_layer = EmbLayer(emb_dict, concat_axis=None) self.field_num = len(emb_dict) self.emb_dim = emb_dict[0][1] self.mb_list, self.mb_out_size = self.createMBlist(igm_reduce_r_list, mb_hid_list, self.emb_out_size) self.cin = CIN(batch_size=BATCH_SIZE, h_0=self.field_num, emb_dim=self.emb_dim, hk_list=cin_hk_list) mlp_size_list.insert(0, self.mb_out_size) if len(mlp_size_list) > 1: self.mlp = MLP(mlp_size_list, bn=True, drop_out=True) else: self.mlp = None self.last_input_dim = mlp_size_list[-1] + self.cin.cin_out_size + self.emb_out_size if self.use_last_fc: self.fc = nn.Linear(self.last_input_dim, 1) def createMBlist(self, igm_reduce_r_list, mb_hid_list, input_size): mb_list = nn.LayerList() mb_out_size = 0 for i in range(len(igm_reduce_r_list)): mb_list.append(MaskBlock(input_size, igm_reduce_r_list[i], mb_hid_list[i])) # mb_out_size += input_size if mb_hid_list[i] == -1 else mb_hid_list[i] return mb_list, mb_out_size def forward(self, x): if self.use_self_emb: x = self.emb_layer(x) # 此时x默认是未经concat的emb_list x = paddle.concat(x, axis=-1) cin_in = paddle.reshape(x, shape=[x.shape[0], self.field_num, self.emb_dim]) # batch_size * field_num * emb_dim cin_out = self.cin(cin_in) pmb_out = paddle.concat([self.mb_list[i](x, x) for i in range(len(self.mb_list))], axis=-1) # x = paddle.concat([x_pm, cin_out], axis=-1) if self.mlp is not None: mlp_out = self.mlp(pmb_out) else: mlp_out = pmb_out x = paddle.concat([x, cin_out, mlp_out], axis=-1) if self.use_last_fc: x = self.fc(x) return F.sigmoid(x) return x
In [ ]
class SerMaskNet(nn.Layer): """ 序列MaskNet,类似于RNN的结构 :param emb_dict: [(原始种类数, 嵌入维度),...] :param igm_reduce_r_list: list, 每个MB对应的缩减率 :param mb_hid_list: list, 每个MB对应的隐层维度 :param mlp_size_list: list, MLP各层尺寸 :param emb_out_size: 嵌入层输出总维度 :param use_self_emb: 是否使用自己的嵌入层 :param use_last_fc: 是否使用最后一层fc :return: """ def __init__(self, emb_dict, igm_reduce_r_list, mb_hid_list, mlp_size_list, emb_out_size=EMB_OUT_SIZE, use_self_emb=True, use_last_fc=True): super(SerMaskNet, self).__init__() self.emb_out_size = emb_out_size self.use_last_fc = use_last_fc self.use_self_emb = use_self_emb if use_self_emb: self.emb_layer = EmbLayer(emb_dict, concat_axis=None) self.mb_list, self.mb_out_size = self.createMBlist(igm_reduce_r_list, mb_hid_list) mlp_size_list.insert(0, self.mb_out_size) # mb层的输出 if len(mlp_size_list) > 1: self.mlp = MLP(mlp_size_list, bn=True, drop_out=0.5) else: self.mlp = None # 记录最后一层输入维度 self.last_input_dim = mlp_size_list[-1] if self.use_last_fc: self.fc = nn.Linear(self.last_input_dim, 1) def createMBlist(self, igm_reduce_r_list, mb_hid_list): mb_list = nn.LayerList() for i in range(len(igm_reduce_r_list)): if i == 0: # 第一个MaskBlock是MaskBlock on Feature Embedding mb_list.append(MaskBlock(self.emb_out_size, igm_reduce_r_list[i], mb_hid_list[i], mode="emb")) else: # 其余MaskBlock都是MaskBlock on MaskBlock mb_list.append(MaskBlock(self.emb_out_size, igm_reduce_r_list[i], mb_hid_list[i], mode="mb")) # return mb_list, mb_hid_list[-1] def forward(self, x): if self.use_self_emb: x = self.emb_layer(x) # 此时x是尚未concat的emb list x = paddle.concat(x, axis=-1) x_left = x # 左边部分是上一个MB的输出 x_right = x # 右边部分是原始emb层的输出 for i in range(len(self.mb_list)): x_left = self.mb_list[i](x_left, x_right) if self.mlp is not None: x = self.mlp(x_left) else: x = x_left if self.use_last_fc: x = self.fc(x) return F.sigmoid(x) return x
In [ ]
# 使用共同的embedding层,每个模型都可以修改# 取出每个模型最后的隐层参数,然后concat之后进行fc
In [ ]
class EnsembleModel(paddle.nn.Layer): def __init__(self, emb_dim_dict=emb_dim_dict): super(EnsembleModel, self).__init__() self.use_self_emb = False # 是否使用各自自己的emb层 if not self.use_self_emb: self.emb_layer = EmbLayer(emb_dim_dict, concat_axis=None) self.model_list = nn.LayerList([ ParaMaskNet(emb_dict=emb_dim_dict, igm_reduce_r_list=[1, 2, 3], mb_hid_list=[512 * i for i in range(1, 4)], mlp_size_list=[512, 128], emb_out_size=EMB_OUT_SIZE, use_self_emb=self.use_self_emb, use_last_fc=False), # DeepFM(emb_dict=emb_dim_dict, mlp_size_list=mlp_size_list, emb_out_size=EMB_OUT_SIZE, use_self_emb=self.use_self_emb, use_last_fc=False), SerMaskNet(emb_dict=emb_dim_dict, igm_reduce_r_list=[1, 2, 3], mb_hid_list=[-1, -1, 512], mlp_size_list=[128], emb_out_size=EMB_OUT_SIZE, use_self_emb=self.use_self_emb, use_last_fc=False) ]) # 还要获取最后一层拼接之后的维度 last_input_dim = sum([m.last_input_dim for m in self.model_list]) self.fc = nn.Linear(last_input_dim, 1) def forward(self, x): if not self.use_self_emb: x = self.emb_layer(x) out_list = [m(x) for m in self.model_list] out = paddle.concat(out_list, axis=-1) out = self.fc(out) return F.sigmoid(out)
xDeepFM
In [ ]
class CIN(paddle.nn.Layer): def __init__(self, batch_size, h_0, emb_dim, hk_list=[100, 100, 50]): super(CIN, self).__init__() self.batch_size = batch_size self.h_0 = h_0 self.emb_dim = emb_dim self.hk_list = hk_list self.wk_list, self.cin_out_size = self.create_cross_ws() def create_cross_ws(self): cin_out_size = 0 # 创建对应每一层的权重(也就是滤波器) self.hk_list.insert(0, self.h_0) wk_list = paddle.nn.ParameterList() for k in range(1, len(self.hk_list)): w_k = paddle.static.create_parameter(shape=[self.hk_list[k-1] * self.h_0, self.hk_list[k]], dtype="float32")#, #default_initializer=paddle.nn.initializer.Constant(1.0)) wk_list.append(w_k) cin_out_size += self.hk_list[k] return wk_list, cin_out_size def forward(self, x): x_0 = x # 原始输入 xk_list = [x_0] # x_k各层的计算结果 sum_pool_list = [] # x_K各层的sum_pooling结果, 不包括第一层 # 分割原始输入 split_x_0 = paddle.split(x_0, self.emb_dim, axis=-1) # 计算x_k for k in range(len(self.hk_list)-1): # 取出x(k-1) x_km1 = xk_list[-1] # 分割x(k-1) split_x_km1 = paddle.split(x_km1, self.emb_dim, -1) # 计算x(k-1) 与 x(0)的外积 -> zk z_k = paddle.concat([paddle.matmul(split_x_km1[i], split_x_0[i], transpose_y=True).unsqueeze(0) for i in range(self.emb_dim)], axis=0) # emb_dim * batch_size * h_km1 * h_0 z_k = paddle.transpose(z_k, perm=[1, 0, 2, 3]) # batch_size * emb_dim * h_km1 * h_0 # 将zk最后两维拉成一维 z_k = paddle.reshape(z_k, shape=[z_k.shape[0], self.emb_dim, -1]) # batch_size * emb_dim * (h_km1 * h_0) # 计算x_k = w * z_k x_k = paddle.matmul(z_k, self.wk_list[k]) # batch_size * emb_dim * h_k # 转置为正常形状 x_k = paddle.transpose(x_k, perm=[0, 2, 1]) # batch_size * h_k * emb_dim # 存储x_k xk_list.append(x_k) # 计算sum_pooling sum_pool_list.append(paddle.sum(x_k, axis=-1)) #print(x_k.shape) # concat sum_pooling的结果 return paddle.concat(sum_pool_list, axis=-1)
In [ ]
class xDeepFM(nn.Layer): def __init__(self, batch_size, emb_dict, emb_dim, cin_hk_list, mlp_size_list): super(xDeepFM, self).__init__() self.emb_layer = EmbLayer(emb_dict) self.field_num = len(emb_dict) self.batch_size = batch_size self.emb_dim = emb_dim self.cin = CIN(batch_size=batch_size, h_0=self.field_num, emb_dim=emb_dim, hk_list=cin_hk_list) # 嵌入总维度 = 域数量 * 单个嵌入维度 mlp_size_list.insert(0, self.emb_layer.emb_out_size) # 域数量 * 嵌入维度 self.mlp = MLP(mlp_size_list, bn=True, drop_out=0.5) self.fc = nn.Linear(self.emb_layer.emb_out_size + self.cin.cin_out_size + mlp_size_list[-1], 1) def forward(self, x): x = self.emb_layer(x) # batch_size * (field_num * emb_dim) # 将原始一维嵌入转换为二维的形式 cin_in = paddle.reshape(x, shape=[x.shape[0], self.field_num, self.emb_dim]) # batch_size * field_num * emb_dim # 计算cin的输出 cin_out = self.cin(cin_in) # 计算mlp的输出 mlp_out = self.mlp(x) # 拼接 原始嵌入 CIN MLP x = paddle.concat([x, cin_out, mlp_out], axis=-1) x = F.sigmoid(self.fc(x)) return x
PlainDNN
In [ ]
class PlainDNN(nn.Layer): def __init__(self, emb_dict, emb_dim, mlp_size_list): super(PlainDNN, self).__init__() self.emb_layer = EmbLayer(emb_dict, concat_axis=None) mlp_size_list.insert(0, self.emb_layer.emb_out_size) self.mlp = MLP(mlp_size_list, bn=True, drop_out=0.5) self.fc = nn.Linear(mlp_size_list[-1], 1) def forward(self, x): x = self.emb_layer(x) x = paddle.concat(x, axis=-1) x = self.mlp(x) x = F.sigmoid(self.fc(x)) return x
DeepFM
In [ ]
class DeepFM(nn.Layer): def __init__(self, emb_dict, mlp_size_list, emb_out_size=EMB_OUT_SIZE, use_self_emb=True, use_last_fc=True): super(DeepFM, self).__init__() self.use_self_emb = use_self_emb self.use_last_fc = use_last_fc # embedding feat_num = len(emb_dict) if self.use_self_emb: self.emb_layer = EmbLayer(emb_dict, concat_axis=None) self.cross_w_list = nn.ParameterList([paddle.static.create_parameter(shape=[1, 32], dtype="float32")] * feat_num) # 为每个特征域生成一个对应的可学习参数,用于交叉 self.emb_out_size = emb_out_size self.sum_w_list = nn.ParameterList([paddle.static.create_parameter(shape=[1, 1], dtype="float32")] * ((feat_num * (feat_num-1))//2 + feat_num)) # mlp mlp_size_list.insert(0, self.emb_out_size) self.mlp = MLP(mlp_size_list, bn=True, drop_out=0.5) # print(self.emb_out_size) self.last_input_dim = self.emb_out_size//feat_num + mlp_size_list[-1] # 拼接fm和mlp if self.use_last_fc: self.fc = nn.Linear(self.last_input_dim, 1) def crossFeats(self, emb_out_list): cross_out_list = [] # 对应位置权重相乘 for i in range(len(emb_out_list)): for j in range(i+1, len(emb_out_list)): cross_out_list.append(self.cross_w_list[i].dot(self.cross_w_list[j]) * emb_out_list[i] * emb_out_list[j]) return cross_out_list def sumFeats(self, cross_list): out = paddle.zeros_like(cross_list[0]) for i in range(len(cross_list)): out += self.sum_w_list[i] * cross_list[i] return out def forward(self, x): # 对所有特征进行依次嵌入 if self.use_self_emb: emb_out_list = self.emb_layer(x) else: # 如果不使用自己的emb层,公用层输出默认就是emb之后的List emb_out_list = x # 计算二阶特征交叉,返回交叉后的List cross_out_list = self.crossFeats(emb_out_list) # 将所有交叉过的2阶特征和原始1阶特征concat #shallow_out = paddle.concat(emb_out_list + cross_out_list, axis=1) # 将一阶特征(原始emb输出)和二阶交叉list拼接之后求和 shallow_out = self.sumFeats(emb_out_list + cross_out_list) # bz * (n + (n-1)*n/2) * emb_dim -> bz * emb_dim # DNN输出 deep_out = self.mlp(paddle.concat(emb_out_list, axis=1)) out = paddle.concat([shallow_out, deep_out], axis=-1) if self.use_last_fc: out = self.fc(out) return F.sigmoid(out) # 如果不使用最后一层fc,则直接把当前模型训练的最后一个隐层输出,用于模型融合 return out
DeepFFM
In [ ]
class DeepFFM(nn.Layer): def __init__(self, cardi_dict, emb_dim, dnn_list): super(DeepFFM, self).__init__() self.cardi_dict = cardi_dict self.emb_layers = nn.LayerList() self.cross_w_list = nn.ParameterList() self.emb_dim_sum = self.createEmbeddingLayers(emb_dim) dnn_list.insert(0, self.emb_dim_sum) self.mlp = MLP(dnn_list, bn=True, drop_out=0.5) feat_num = len(cardi_dict) self.sum_w_list = nn.ParameterList([paddle.static.create_parameter(shape=[1, 1], dtype="float32")] * (np.int(np.power(feat_num-1, 2)) + feat_num)) #last_dim = np.int(np.power(feat_num-1, 2)) * emb_dim + feat_num * emb_dim + dnn_list[-1] last_dim = emb_dim + dnn_list[-1] self.fc = nn.Linear(last_dim, 1) def createEmbeddingLayers(self, emb_dim): emb_dim_sum = 0 for feat in feat_list: cardi = self.cardi_dict[feat] self.emb_layers.append(nn.Embedding(cardi, emb_dim)) # 每个特征域对应一个权重矩阵: emb_dim * m w_dim = 16 self.cross_w_list.append(paddle.static.create_parameter(shape=[emb_dim, w_dim], dtype="float32")) emb_dim_sum += emb_dim return emb_dim_sum def crossFeats(self, emb_out_list): cross_out_list = [] # 对应位置权重相乘 for i in range(len(emb_out_list)): for j in range(len(emb_out_list)): if i == j: break hadma_prod = emb_out_list[i] * emb_out_list[j] w_prod = paddle.matmul(self.cross_w_list[i], self.cross_w_list[j], transpose_y=True) w_emb_prod = paddle.matmul(w_prod, hadma_prod, transpose_y=True) cross_out_list.append(paddle.transpose(w_emb_prod, perm=[1, 0])) return cross_out_list def sumFeats(self, cross_list): out = paddle.zeros_like(cross_list[0]) for i in range(len(cross_list)): out += self.sum_w_list[i] * cross_list[i] return out def forward(self, x): # 对所有特征进行依次嵌入 emb_out_list = [self.emb_layers[i](x[:, i]) for i in range(len(self.emb_layers))] # 对所有特征进行交叉 cross_out_list = self.crossFeats(emb_out_list) # 将所有交叉过的2阶特征和原始1阶特征concat #shallow_out = paddle.concat(emb_out_list + cross_out_list, axis=1) shallow_out = self.sumFeats(emb_out_list + cross_out_list) # bz * 64 # DNN输出 deep_out = self.mlp(paddle.concat(emb_out_list, axis=1)) out = paddle.concat([shallow_out, deep_out], axis=-1) out = self.fc(out) return F.sigmoid(out)
模型实例化
In [ ]
# DeepFFM模型# model_dffm = DeepFFM(cardi_dict=cardi_dict, emb_dim=64, dnn_list=[512, 256, 64]) # DeepFM模型# model_dfm = DeepFM(emb_dict=emb_dim_dict, mlp_size_list=[512, 256, 64], emb_out_size=EMB_OUT_SIZE, use_self_emb=True, use_last_fc=True) # xDeepFM模型# model_xdfm = xDeepFM(batch_size=BATCH_SIZE, # emb_dict=emb_dim_dict, # emb_dim=CIN_EMB_DIM, # cin_hk_list=CIN_HK_LIST, # mlp_size_list=[512, 256, 64])# MaskNet-并行结构# model_pmb = ParaMaskNet(emb_dict=emb_dim_dict, # igm_reduce_r_list=[1, 2, 3], # mb_hid_list=[512 * i for i in range(1, 4)], # mlp_size_list=[512, 128])# MaskNet + CIN# model_mpmb = ModifyParaMaskNet(emb_dict=emb_samedim_dict, # igm_reduce_r_list=[1, 2, 3], # mb_hid_list=[256, 512, 768], # cin_hk_list=[128, 128, 64], # mlp_size_list=[256], # emb_out_size=EMB_SAMEOUT_SIZE)# MaskNet-序列结构# model_smb = ParaMaskNet(emb_dict=emb_dim_dict, # igm_reduce_r_list=[1, 2, 3], # mb_hid_list=[-1, -1, 512], # mlp_size_list=[128])# 集成模型model_ensem = EnsembleModel(emb_dim_dict=emb_dim_dict)
定义训练及验证函数
In [ ]
def getTrue(a, b): """ 计算a和b有多少相同元素,要求a和b长度相同 :param a: list :param b: list :return: a和b中相同元素数量 """ res = 0 for i in range(len(a)): if a[i] == b[i]: res += 1 return res
In [ ]
def validation(model, loss_fn, data_loader, mode="valid"): """ 计算模型在指定数据上的损失和准确 :param model: 需要评估的模型 :param loss_fn: 损失函数 :param data_loader: 数据迭代器 :param mode: 标识当前验证的数据类型 :return: 返回当前model在当前数据上的acc """ model.eval() acc = 0 loss_ave = 0 for idx, (x, y) in enumerate(data_loader): y = y.numpy() x = paddle.to_tensor(x) y = paddle.to_tensor(y, dtype="float32") y_pre = model(x) y_pre = y_pre.squeeze(-1) loss = loss_fn(y_pre, y) loss_ave += loss.numpy()[0] a = y_pre.numpy() a = list(map(lambda x: 1 if x >= 0.5 else 0, a)) b = y.numpy() b = list(map(lambda x: np.int(x), b)) acc += getTrue(a, b) acc /= len(data_loader) * BATCH_SIZE loss_ave /= len(data_loader) * BATCH_SIZE print(mode + f":loss_ave:{loss_ave}, acc:{acc}") model.train() return acc
In [ ]
def trainModel(model, loss_fn, optimizer, device, data_loader, start_epoch=0, epoches=10, model_name="DNN", start_save_acc=0.8801, use_all_data=USE_ALL_DATA): """ 模型训练 :param model: 需要训练的模型 :param loss_fn: 损失函数 :param optimizer: 优化器 :param device: 使用的设备,cpu or gpu :param data_loader: 训练使用的数据 :param start_epoch: 起始训练的epoch编号 :param epoches: 需要训练的epoches数量 :param model_name: 当前训练的模型名,用于保存参数的时候命名 :param start_save_acc: 大于当前值则开始保存模型参数 :param use_all_data: 是否使用全部数据 :return: loss_list, acc_list """ print(device) paddle.set_device(device) model.train() loss_list = [] loss_min = 9999 acc_list = [] acc_max = start_save_acc #for epoch in range(epoches): for epoch in range(start_epoch, start_epoch + epoches): epoch_ave_loss = 0 for idx, (x, y) in enumerate(data_loader): y = y.numpy() x = paddle.to_tensor(x) y = paddle.to_tensor(y, dtype="float32") y_pre = model(x) y_pre = y_pre.squeeze(-1) loss = loss_fn(y_pre, y) epoch_ave_loss += loss.numpy()[0] if idx % 500 == 0: print(f"epoch:{epoch}, idx:{idx}, batch_sum_loss:{loss.numpy()[0]}") loss.backward() optimizer.step() optimizer.clear_grad() epoch_ave_loss /= len(data_loader) * BATCH_SIZE loss_list.append(epoch_ave_loss) print(f"epoch:{epoch}, ave_loss:{epoch_ave_loss}") # 计算训练集准确率 train_acc = validation(model, loss_fn, data_loader, mode="train") if not use_all_data: acc = validation(model, loss_fn, valid_loader) acc_list.append(acc) if acc > acc_max: acc_max = acc paddle.save(model.state_dict(), "./work/" + model_name + "_acc_epoch" + str(epoch) + ".pdparams") else: if epoch_ave_loss < loss_min: loss_min = epoch_ave_loss paddle.save(model.state_dict(), "./work/" + model_name + "_loss_epoch" + str(epoch) + ".pdparams") print("-------------------------------------------------------------------") if epoch_ave_loss < 0.27: print("Early Stopping!") return loss_list, acc_list return loss_list, acc_list
模型训练
In [ ]
# 定义损失函数、优化器,选择设备loss_fn = nn.BCELoss(reduction="sum")device = paddle.get_device()optimizer = optim.Adam(parameters=model_ensem.parameters(), learning_rate=0.001, weight_decay=0.01)
In [40]
# 模型训练loss_list, acc_list = trainModel(model_ensem, loss_fn, optimizer, device, train_loader, start_epoch=1, epoches=20, model_name="ensem_pd", start_save_acc=0, use_all_data=False)
In [ ]
# 保存训练loss和准确率# with open("./work/loss_list.pkl", "wb") as f:# pickle.dump(loss_list, f)# with open("./work/acc_list.pkl", "wb") as f:# pickle.dump(acc_list, f)
绘制损失及ACC变化曲线
In [ ]
plt.figure()plt.plot(loss_list)plt.show()plt.plot(acc_list)plt.show()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator):/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data
读取测试集数据并进行推断
In [41]
if USE_TIME: test = pd.read_csv(DATA_PATH + "lbe_raw_test_with_time.csv")else: test = pd.read_csv(DATA_PATH + "lbe_raw_test.csv")test = reduce_mem_usage(test, use_uint=False)
StartMem:28.61Mb, EndMem:6.87Mb (76.0% reduction)
In [42]
X_test = test[feat_list].values
In [43]
def predict(model, data): """ 计算model在data上的预测值 :param model: 需要推断的模型 :param data: 测试集数据 :return: model在测试集上得到的预测结果 """ data = paddle.to_tensor(data) y_pre = model(data) y_pre = y_pre.squeeze(-1) return y_pre.numpy()
In [44]
def getYtest(model, data): """ 计算model在data上的预测标签 :param model: 模型 :param data: 测试集 :return: 测试集预测值和对应的标签 """ # 分割一下data data_list = [] # 每块大小变更为batch_size, 然后统一装到list中 i = 0 while i = 0.5 else 0, y_test_pre)) return y_test_pre, y_test_label
In [46]
# 加载最优参数model_param = paddle.load("./work/ens_pds_loss_epoch21_89172.pdparams")model_ensem.set_state_dict(model_param)
In [47]
# 生成预测标签y_test_pre, y_test_label = getYtest(model_ensem, X_test)
In [ ]
# 把模型预测输出存储至文件# with open("./work/y_pred.pkl", "wb") as f:# pickle.dump(y_test_pre, f)
生成提交文件
In [45]
def getSubmission(df, y_test_label, save_path): """ 生成提交结果 :param df: 测试集dataframe :param y_test_label: 测试集对应的预测标签 :param save_path: 提交文件保存路径 """ df["label"] = y_test_label submission = df[["sid", "label"]] submission.to_csv(save_path, index=False)
In [ ]
# 生成提交文件getSubmission(test, y_test_label, "./work/ens_ps_17.csv")
以上就是飞桨常规赛:点击反欺诈预测 5月第2名方案的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/51926.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























