
本文介绍了基于PaddleDetection的目标检测项目流程,包括克隆仓库、安装依赖、编译安装等步骤。还涵盖数据集准备,如查看COCO标注、解压和配置数据集,以及模型训练、预测、导出,最后说明代码提交及优化方法,如调整阈值等。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、安装PaddleDetection
In [ ]
# 克隆PaddleDetection仓库# 如果已经克隆,则不需要重复运行,可把第3行直接注释,从第6行开始运行!git clone https://gitee.com/PaddlePaddle/PaddleDetection.git# 安装其他依赖%cd PaddleDetection!pip install -r requirements.txt# 编译安装paddledet!python setup.py install%cd ~
二、数据集准备
1、数据标注查看
本次比赛为大家提供了COCO格式的数据集。
COCO数据标注是将所有训练图像的标注都存放到一个json文件中。数据以字典嵌套的形式存放。
json文件中包含以下key:
info,表示标注文件info。licenses,表示标注文件licenses。images,表示标注文件中图像信息列表,每个元素是一张图像的信息。annotations,表示标注文件中目标物体的标注信息列表,每个元素是一个目标物体的标注信息。In [1]
# 查看COCO标注文件import jsoncoco_anno = json.load(open('WisdomGuide/annotations/instance_train.json'))# coco_anno.keysprint('nkeys:', coco_anno.keys())# 查看类别信息print('n物体类别:', coco_anno['categories'])# 查看一共多少张图print('n图像数量:', len(coco_anno['images']))# 查看一共多少个目标物体print('n标注物体数量:', len(coco_anno['annotations']))# 查看一条目标物体标注信息print('n查看一条目标物体标注信息:', coco_anno['annotations'][0])
keys: dict_keys(['images', 'categories', 'annotations'])物体类别: [{'supercategory': 'component', 'id': 1, 'name': 'blind_path'}, {'supercategory': 'component', 'id': 2, 'name': 'green_light'}, {'supercategory': 'component', 'id': 3, 'name': 'block'}, {'supercategory': 'component', 'id': 4, 'name': 'no_light'}, {'supercategory': 'component', 'id': 5, 'name': 'red_light'}]图像数量: 7995标注物体数量: 25265查看一条目标物体标注信息: {'segmentation': [[3.0, 2.5380710659898478, 3.0, 479.0, 357.11167512690355, 479.0, 357.11167512690355, 2.5380710659898478]], 'iscrowd': 0, 'image_id': 1, 'bbox': [3.0, 2.5380710659898478, 354.11167512690355, 476.46192893401013], 'area': 168720.731789018, 'category_id': 1, 'id': 1}
2、解压数据集
In [2]
# 解压数据集!gzip -dfq /home/aistudio/data/data137625/WisdomGuide.tar.gz!tar -xf /home/aistudio/data/data137625/WisdomGuide.tar -C /home/aistudio/ #把数据集移到/home/aistudio下面
3、配置数据集
注意:生成版本,由于PaddleDetection文件夹下的文件较多,无法保存,因此数据集的配置文件需要我们自行配置
在PaddleDetection/configs/datasets/路径下新建一个coco_dog.yml文件,并配置数据集格式、类别、加载路径等信息:
metric: COCOnum_classes: 5TrainDataset: !COCODataSet image_dir: train anno_path: annotations/instance_train.json dataset_dir: /home/aistudio/WisdomGuide/ data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']EvalDataset: !COCODataSet image_dir: val anno_path: annotations/instance_val.json dataset_dir: /home/aistudio/WisdomGuide/TestDataset: !ImageFolder ! anno_path: annotations/instance_val.json image_dir: val dataset_dir: /home/aistudio/WisdomGuide/
三、模型训练
Baseline选择的模型是PP-Picodet,本项目就继续使用PP-Picodet,在Baseline的基础上进行微调
1.训练配置
在正式开始训练前,我们需要选择配置文件,并修改参数
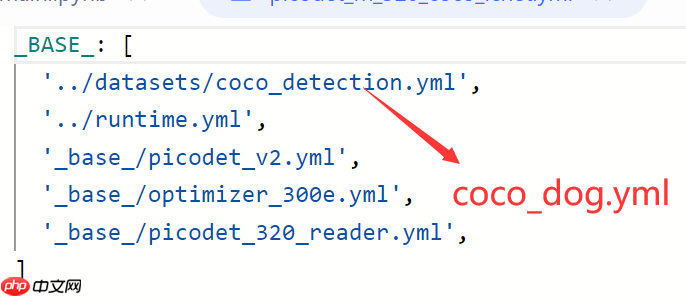
将PaddleDetection/configs/picodet/picodet_m_320_coco_lcnet.yml里的数据集配置改成我们前面自己新建的数据集配置,也就是coco_dog.yml
2、模型训练
注意:数据集配置一定要改为前面我们自行配置的
In [ ]
# 模型训练%cd ~%cd PaddleDetection!python tools/train.py -c configs/picodet/picodet_m_320_coco_lcnet.yml
如果需要更换模型,直接在上述代码中修改路径即可,注意:更换模型时,检查数据集是不是我们要用的数据集。
如果训练时,突然中断了,需要恢复训练,使用-r参数,后面加上模型路径即可
例:!python tools/train.py -c configs/picodet/picodet_m_320_coco_lcnet.yml -r -r output/picodet_m_320_coco_lcnet/best_model
想要边训练边评估,末尾加 –eval 即可
例:!python tools/train.py -c configs/picodet/picodet_m_320_coco_lcnet.yml –eval
训练时的日志输出已单独保存在vdl_log_dir/scalar/vdlrecords.1649487648.log
注意:以下代码运行,需等模型训练完成后
3.模型预测
训练好模型以后,我们可以检验一下效果。
In [ ]
%cd ~%cd PaddleDetection# 更换"--infer_img"里的图片路径以预测不同的图片!python tools/infer.py -c configs/picodet/picodet_m_320_coco_lcnet.yml --infer_img=/home/aistudio/WisdomGuide/val/no_light_629.png --output_dir=infer_output/ --draw_threshold=0.5 -o weights=/home/aistudio/PaddleDetection/output/picodet_m_320_coco_lcnet/best_model.pdparams --use_vdl=Ture

4.导出模型
转换并保存静态图模型。
这里假设我们已经在线训练10小时,获得了模型
如果要生成版本,由于PaddleDetection文件夹下的文件较多,无法保存,故要把训练好的模型单独拿出来,例如放在/home/aistudio/checkpoint/best_model.pdparams。
In [ ]
%cd ~%cd PaddleDetection# 将"-o weights"里的模型路径换成你自己训好的模型!export CUDA_VISIBLE_DEVICES=0!python tools/export_model.py -c configs/picodet/picodet_m_320_coco_lcnet.yml -o weights=/home/aistudio/PaddleDetection/output/picodet_m_320_coco_lcnet/best_model.pdparams TestReader.fuse_normalize=true
四、代码提交
这一步与Baseline操作基本一样
AI Studio上提供了一套测评系统,我们将训练好的模型和预测代码打包上传,测评系统会自动算分。
提交格式:
| -- model| | -- xxx.pb| | … | -- env| | -- | |…| -- predict.py| -- …
In [5]
%cd ~# 在work目录下整理提交代码# 创建model文件夹(已经创建好的话,就不用再创建了)!mkdir /home/aistudio/work/model# 将检测模型拷贝到model文件夹中!cp -r /home/aistudio/PaddleDetection/output_inference/picodet_m_320_coco_lcnet/ /home/aistudio/work/model/# 将训练脚本拷贝到work目录下,与model同级!cp /home/aistudio/PaddleDetection/tools/train.py /home/aistudio/work/# 将PaddleDetection也复制进来!cp -r /home/aistudio/PaddleDetection/ /home/aistudio/work/
/home/aistudio
这里为了让压缩包更小,建议把PaddleDetection里面不用的模型备份出来。特别地,隐藏文件.git占用存储空间较大,且在这里没有什么用,故可以手动删除。
In [9]
# 删除隐藏文件!rm -rf /home/aistudio/work/PaddleDetection/.git/
注意: 在打包前,请将work/PaddleDetection/deploy/python/preprocess.py的第17行改为:
from .keypoint_preprocess import get_affine_transform
否则会出现以下报错:
Traceback (most recent call last): File "predict.py", line 19, in from deploy.python.preprocess import preprocess, Resize, NormalizeImage, Permute, PadStride File "PaddleDetection/deploy/python/preprocess.py", line 17, in from keypoint_preprocess import get_affine_transformModuleNotFoundError: No module named 'keypoint_preprocess'
In [10]
# 打包代码%cd /home/aistudio/work/!zip -r -q -o submission.zip model/ PaddleDetection/ train.py predict.py
/home/aistudio/work
在提交前,我们需要改动一下predict.py文件,这样我们才能上0.8 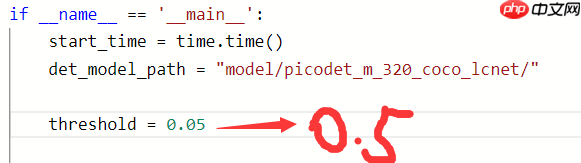
我们把阈值参数由0.05改为0.5,就OK啦。
预选赛时,有不少同学说:我模型的预测效果比Baseline好,为啥提交后分数比Baseline低啊,原因就是这个。
阈值由Baselin的0.05改为0.5,我们就会获得巨大提升。
然后从aistudio上下载打包好的submission.zip文件,就可以直接到官网提交啦!现在预选赛的通道关闭了,我们可以在练习赛进行提交。
如果提交成功,就可以看到自己的分数了。
本项目在baseline基础上,将阈值改为0.5,结果在0.8之上。大家可以试试。
五、优化方法
1、尝试不同的阈值,找出最佳阈值。
修改阈值能够提升一点我们的得分,0.5对有些模型来说,不是最佳阈值,我们可以试试不同阈值提交,找到该模型的最佳阈值。
2、加大训练轮数
有些模型原始的配置轮数不是最大,我们可以将训练轮数加大到,该模型最大轮数,例如Picodet-m-416模型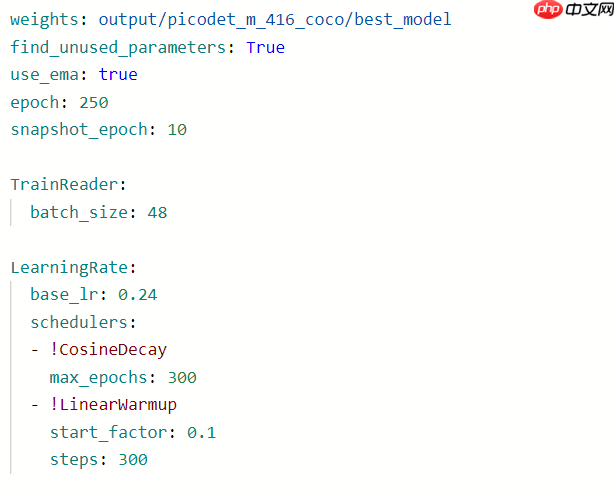
最大轮数是300轮,最初设置是250轮,我们可以将轮数设置最大轮数300轮。
3、尝试不同的模型
尝试一下其他的模型,例如PP-YOLO,YOLOv3等,这里透露一下,PP-Picodet能上0.87
4、加载COCO数据集预训练模型,使用预训练模型可以有效提升模型精度
以Picodet-m-320为例: 修改Picodet_v2.yml中的pretrain_weights即可 
5、修改loss
将picodet_v2.yml中的lossbbox name值由GIoU改为DIou 
6、修改lr
降低学习率,尝试调整为一半或十分之一,亦或是其他学习率
以上就是一些通用的方法,非常基础外加非常简单,大家可以逐一尝试,或者觉得麻烦的话,一口气全部试在一个模型里面,模型训练完成后,通过智慧导盲练习赛进行得分验证。此外这些方法也可以在以后的一些比赛使用,屡试不爽。
或许还有一些其他不动网络的提升方法,但我并不知道,欢迎各位大佬补充
我在work目录下面放了一个导出的Picodet-m-320模型,大家把predict.py的阈值改改,复制PaddleDetion,打包进行提交,验证第一个方法。
以上就是【第十五届中国计算机设计大赛】智慧导盲组,手把手教你超越0.8的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/52264.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























