
该项目针对百度网盘AI大赛文档检测优化赛,采用回归方式处理,用Res2Net101_vd_26w_4s+注意力双分支Linear层结构回归文档四角坐标。经数据预处理、模型调优,对比不同backbone、损失函数等,发现注意力双支、L1Loss更优,最终模型在评测中表现良好。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

百度网盘AI大赛-图像处理挑战赛:文档检测优化赛
基于Baseline,我们替换backbone,使用预训练好的模型Res2Net101_vd_26w_4s来回归图像中文档的拐角坐标完成百度网盘AI大赛-图像处理挑战赛:文档检测优化赛。
比赛链接
一、比赛介绍
生活中人们使用手机进行文档扫描逐渐成为一件普遍的事情,为了提高人们的使用体验,我们期望通过算法技术去除杂乱的拍摄背景并精准框取文档边缘,选手需要通过深度学习技术训练模型,对给定的真实场景下采集得到的带有拍摄背景的文件图片进行边缘智能识别,并最终输出处理后的扫描结果图片。
评测方式说明
参赛选手提交的代码和模型只预测文档边缘的heatmap图,由后台评测脚本中预置的算法回归出文档区域的四个角的坐标点,并生成规则的四边形,与GT计算IoU值;参赛选手提交的代码和模型直接回归文档区域的四个角的坐标点,并生成规则的四边形,与GT计算IoU值。 注:两种评测方式的结果会放在一个排行榜内,评测脚本中预置的角点回归算法会存在一定的局限性,如果各位参赛选手希望获得更高的分数,建议采用第二种评测方式。
二、赛题分析
本次比赛要求选手设计算法在给定图片中划定一块四边形区域,以尽可能与图片中的文档部分重合。
因此,本次任务可以同时看作回归问题和分割问题。
作为回归问题,设计模型直接回归四个角点坐标(x1, y1; x2, y2; x3, y3; x4, y4),并利用L1Loss、L2Loss等损失函数优化模型作为分割问题,直接将数据中的segments作为标签训练选取/设计的分割模型,然后根据预测的heatmap图回归出角点坐标
本项目将本次任务看作回归问题来处理,使用Res2Net101_vd_26w_4s+注意力双分支Linear层的网络结构回归四个角的坐标。
三、数据处理
获取数据
In [ ]
! wget https://staticsns.cdn.bcebos.com/amis/2022-4/1649731549425/train_datasets_document_detection_0411.zip! unzip -oq /home/aistudio/train_datasets_document_detection_0411.zip! rm -rf __MACOSX! rm -rf /home/aistudio/train_datasets_document_detection_0411.zip
构造数据读取器
通过paddle.io.dataset构造读取器,便于读取数据。
数据预处理包括:
根据data_info.txt文件中提供的边缘轮廓信息分别提取四个角点的x,y坐标对图片进行resize和数据增强(调整明暗对比度等参数)
查看数据
通过get_corner函数得到四个角点的x,y坐标
In [1]
def get_corner(positions, corner_flag, w, h): # corner_flag 1:top_left 2:top_right 3:bottom_right 4:bottom_left if corner_flag == 1: target_pos = [0,0] elif corner_flag == 2 : target_pos = [w,0] elif corner_flag == 3 : target_pos = [w,h] elif corner_flag == 4 : target_pos = [0,h] min_dis = h**2+w**2 best_x = 0 best_y = 0 for pos in positions: now_dis = (pos[0]-target_pos[0])**2+(pos[1]-target_pos[1])**2 if now_dis<min_dis: min_dis = now_dis corner_x = pos[0] corner_y = pos[1] return corner_x, corner_y
In [2]
import os, cv2import numpy as nptrain_imgs_dir = '/home/aistudio/train_datasets_document_detection_0411/images/'train_txt = '/home/aistudio/train_datasets_document_detection_0411/data_info.txt'data_info = []with open(train_txt,'r') as f: for line in f: line = line.strip().split(',') image_name = line[0] img = cv2.imread(os.path.join(train_imgs_dir, image_name+'.jpg')) h, w, c = img.shape positions = [] for i in range(1,len(line),2): #从data_info.txt文件中获得该图片对应的边缘轮廓信息 positions.append([float(line[i]), float(line[i+1])]) label = [] for i in range(4): #从边缘轮廓信息提取出四个角点的x,y坐标 corner_x, corner_y = get_corner(positions, i+1, w, h) label.append(corner_x) label.append(corner_y) data_info.append((image_name+'.jpg', label, (w, h))) break
利用边缘轮廓信息和四个角点的x,y坐标绘图来验证我们提取的四个角点的x,y坐标是否正确。 其中蓝色点为边缘轮廓信息,红色线连接的四个点即为四个角点。
In [3]
import matplotlib.pyplot as plt%matplotlib inlineplt.figure()positions = np.array(positions)label = np.array(label)plt.plot(positions[:, 0], h-positions[:, 1], "ob")plt.plot(label[[0, 2, 4, 6, 0]], h-label[[1, 3, 5, 7, 1]], "r")
[]
我们将数据处理与构造的所有代码存放在work/dataset.py中,实验发现Baseline的数据增强操作的确能够带来少量性能提升
四、模型实现
我们认为强大的backbone有助于性能的提升,在保证满足要求的推理时间下,我们选择了预训练的resnet18、resnet50、resnet152、Res2Net101_vd_26w_4s作为backbone来选取较优的模型,在A榜的成绩证实了在Imagenet上效果更好的Res2Net101_vd_26w_4s在本次任务上性能更优。最初采用的模型结构如下图所示: 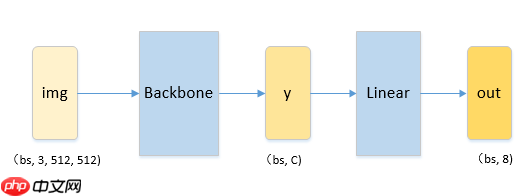
实验发现单分支的Linear层预测的角点坐标,不如以注意力值为权重双分支求和的双分支Linear层的预测效果好,有种按样本自适应集成的效果。如下图所示,为了简洁,忽略激活函数,将两个分支的输出out1、out2求和后输入到两个线性层变换后,经过sigmoid函数输出一个通道注意力系数,然后将out1与out2按注意力系数进行逐通道加权求和作为最后的输出。关于模型耗时与大小,B榜显示每张图片推理耗时0.15832s,要远低于比赛限制的1s,我们所测得参数量为43.3M,单张512×512的图片浮点数运算量为43.6G。 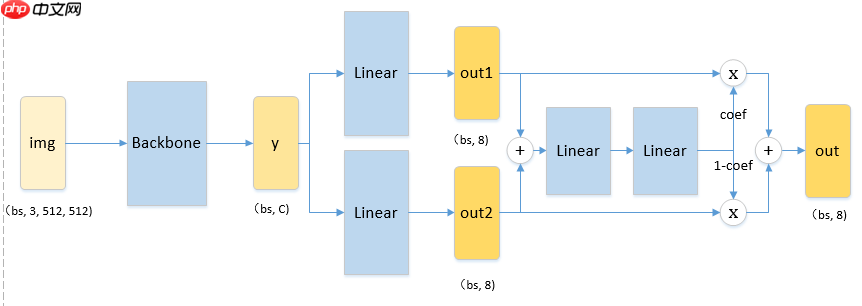
代码实现如下所示:
class MyNet(paddle.nn.Layer): def __init__(self): super(MyNet,self).__init__() self.backbone = Res2Net_vd(layers=101, scales=4, width=26) state_dict = paddle.load("Res2Net101_vd_26w_4s_ssld_pretrained.pdparams") self.backbone.set_state_dict(state_dict) self.fc1 = paddle.nn.Linear(self.backbone.pool2d_avg_channels, 8) self.fc2 = paddle.nn.Linear(self.backbone.pool2d_avg_channels, 8) self.attn = paddle.nn.Sequential( paddle.nn.ReLU(), paddle.nn.Linear(8, 32), paddle.nn.ReLU(), paddle.nn.Linear(32, 8), paddle.nn.Sigmoid() ) def forward(self, img): y = self.backbone(img) y1 = self.fc1(y) y2 = self.fc2(y) coef = self.attn(y1+y2) y = y1*coef+y2*(1.-coef) return y
完整代码见work/model.py
五、调优设置
简要说一下我们所做的一些调优尝试。我们将数据集按4:1的比例划分出训练集和验证集,我们使用模型性能度量标准miou选取验证集上最优的模型为提交测试模型,验证集miou与A榜miou相差0.01~0.02个点。如此表所示,我们一步步地修改超参数与模型结构、损失函数等不断提高模型性能。由第二列和第三列对比可以看出,注意力双支要优于单支,由第四列和第五列对比可以看出,L1Loss优于L2Loss。从最后两列对比可以看出Res2Net101要略优于resnet152。而且使用更多迭代次数和更大的学习率与合适的衰减策略有助于模型更好的收敛。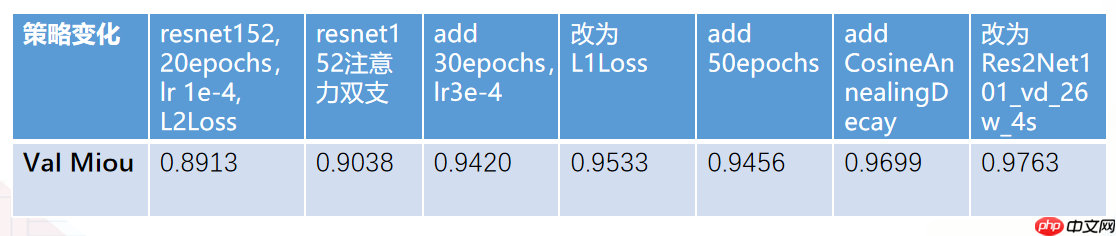
基于角点的miou实现如下所示:
def cal_miou(bs, h, w, pred, label, mode='mean'): miou = 0 for i in range(bs): mask_pre = Image.new('L', (w, h), 0) draw = ImageDraw.Draw(mask_pre, 'L') corner_xy = [(pred[i, j]*w, pred[i, j+1]*h) for j in range(0, 8, 2)] draw.polygon(corner_xy, fill=1) mask_pre = np.array(mask_pre, dtype=np.float32) mask_gt = Image.new('L', (w, h), 0) draw = ImageDraw.Draw(mask_gt, 'L') corner_xy = [(label[i, j]*w, label[i, j+1]*h) for j in range(0, 8, 2)] draw.polygon(corner_xy, fill=1) mask_gt = np.array(mask_gt, dtype=np.float32) mul = (mask_gt*mask_pre).sum() iou = mul/(mask_gt.sum()+mask_pre.sum()-mul) miou = miou+iou if mode=="mean": return miou/bs elif mode=="sum": return miou
criterion = paddle.nn.L1Loss()#MSELoss()
In [ ]
#划分训练集、验证集训练%cd work/!python main.py --save_dir output/train_val --epochs 100 --learning_rate 3.0e-4 --use_schedule True --train_ratio 0.8%cd ../
In [ ]
#全料数据训练%cd work/!python main.py --save_dir output/all_data --epochs 100 --learning_rate 3.0e-4 --use_schedule True%cd ../
六、预测与结果提交
本题目提交需要提交对应的模型和预测文件。predict.py需要读取同目录下的模型信息,并预测坐标点-保存为json或预测分割后的图片-保存为图片形式。
想要自定义训练模型,只需要将predict.py中的模型和process函数中的do something 替换为自己的模型内容即可。
提交分割模型时,取消predict中52行的注释部分即可保存分割后的图片信息
注意model.eval()不要漏掉,不然分数会下降10个点左右
In [2]
# 压缩可提交文件,这里我们提供了全料数据训练得到的最终模型为B榜提交模型,A榜是train:val=4:1下训练的最佳模型(没有放上来)%cd work/! zip submit_detection.zip model_best.pdparams predict.py%cd ../
/home/aistudio/work adding: model_best.pdparams (deflated 8%) adding: predict.py (deflated 73%)/home/aistudio
以上就是百度网盘AI大赛-文档检测优化赛第7名方案的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/52432.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























