
预训练大语言模型(LLM)在特定任务上的性能不断提高,随之而来的是,假如 prompt 指令得当,其可以更好的泛化到更多任务,很多人将这一现象归功于训练数据和参数的增多,然而最近的趋势表明,研究者更多的集中在更小的模型上,不过这些模型是在更多数据上训练而成,因而在推理时更容易使用。
举例来说,参数量为 7B 的 LLaMA 在 1T token 上训练完成,尽管平均性能略低于 GPT-3,但参数量是后者的 1/25。不仅如此,当前的压缩技术还能将这些模型进一步压缩,在保持性能的同时还能大幅减少内存需求。通过这样的改进,性能良好的模型可以在终端用户设备(如笔记本)上进行部署。
然而,这又面临另一个挑战,即想要将这些模型压缩到足够小的尺寸以适应这些设备,怎样才能兼顾生成质量。研究表明,尽管压缩后的模型生成的答案准确率还可以,但现有的 3-4 位量化技术仍然会让准确性降低。由于 LLM 生成是顺序进行的,依赖于先前生成的 token,小的相对误差不断累积并导致严重的输出损坏。为了确保可靠的质量,关键是设计出低位宽的量化方法,与 16 位模型相比不会降低预测性能。
然而,将每个参数量化到 3-4 位通常会导致中等程度、甚至是高等程度的准确率损失,特别是那些非常适合边缘部署的 1-10B 参数范围内的较小模型。
为了解决准确性问题,来自华盛顿大学、苏黎世联邦理工学院等机构的研究者提出了一种新的压缩格式和量化技术 SpQR(Sparse-Quantized Representation,稀疏 – 量化表征),首次实现了 LLM 跨模型尺度的近无损压缩,同时达到了与以前方法相似的压缩水平。
SpQR 通过识别和隔离异常权重来工作,这些异常权重会导致特别大的量化误差,研究者将它们以更高的精度存储,同时将所有其他权重压缩到 3-4 位,在 LLaMA 和 Falcon LLMs 中实现了不到 1% 的困惑度相对准确率损失。从而可以在单个 24GB 的消费级 GPU 上运行 33B 参数的 LLM,而不会有任何性能下降,同时还能提高 15% 的速度。
SpQR 算法高效,既可以将权重编码为其他格式,也可以在运行时进行有效地解码。具体来说,该研究为 SpQR 提供了一种高效的 GPU 推理算法,可以比 16 位基线模型更快地进行推理,同时实现了超过 4 倍的内存压缩收益。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/pdf/2306.03078.pdf项目地址:https://github.com/Vahe1994/SpQR
方法
该研究提出一种混合稀疏量化的新格式 —— 稀疏量化表征(SpQR),可以将精确预训练的 LLM 压缩到每个参数 3-4 位,同时保持近乎无损。
具体来说,该研究将整个过程分为两步。第一步是异常值检测:该研究首先孤立了异常值权重,并证明其量化会导致高误差:异常值权重保持高精度,而其他权重以低精度(例如 3 位的格式)存储。然后,该研究以非常小的组大小实现分组量化(grouped quantization)的变体,并表明量化尺度本身可以被量化为 3 位表征。
SpQR 极大地减少了 LLM 的内存占用,而不会降低准确性,同时与 16 位推理相比,LLM 的生成速度快了 20%-30%。
此外,该研究发现,权重矩阵中敏感权重的位置不是随机的,而是具有特定的结构。为了在量化过程中突出显示其结构,该研究计算了每个权重的敏感度,并为 LLaMA-65B 模型可视化这些权重敏感度。下图 2 描绘了 LLaMA-65B 最后一个自注意力层的输出投影。
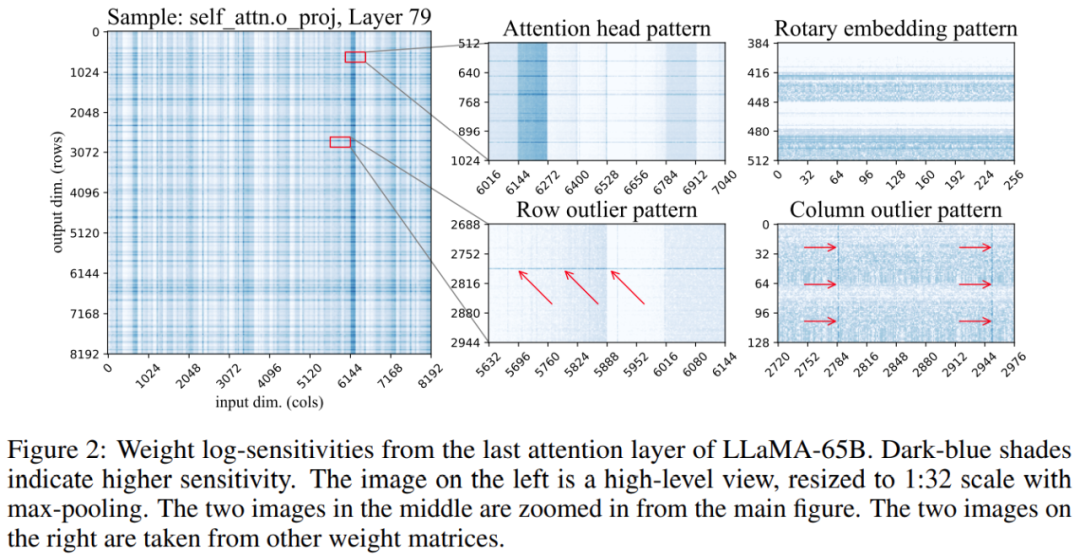
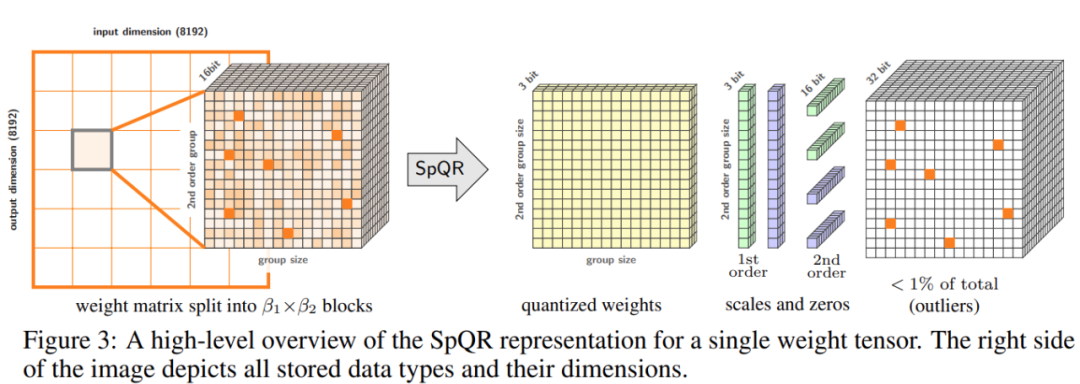
该研究对量化过程进行了两个改变:一个用于捕捉小的敏感权重组,另一个用于捕捉单个的异常值。下图 3 为 SpQR 的总体架构:
下表为 SpQR 量化算法,左边的代码片段描述了整个过程,右边的代码片段包含了二级量化和查找异常值的子程序:

实验
该研究将 SpQR 与其他两种量化方案进行了比较:GPTQ、RTN(rounding-to-nearest),并用两个指标来评估量化模型的性能。首先是困惑度的测量,所用数据集包括 WikiText2、 Penn Treebank 以及 C4;其次是在五个任务上的零样本准确率:WinoGrande、PiQA、HellaSwag、ARC-easy、ARC-challenge。
主要结果。图 1 结果显示,在相似的模型大小下,SpQR 的性能明显优于 GPTQ(以及相应的 RTN),特别是在较小的模型上。这种改进得益于 SpQR 实现了更多的压缩,同时也减少了损失退化。
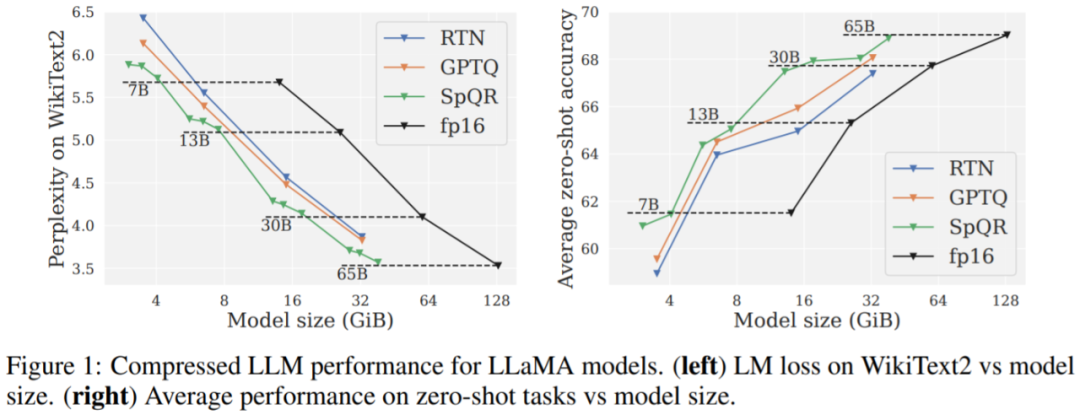
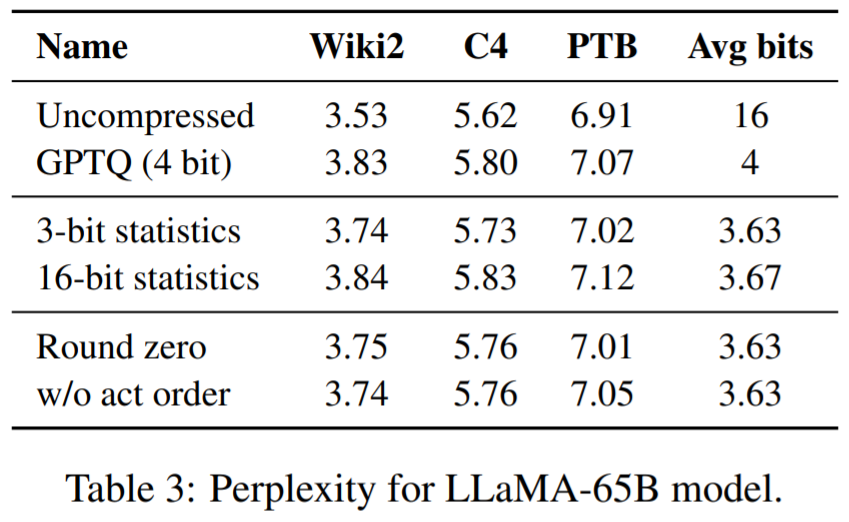
表 1、表 2 结果显示,对于 4 位量化,与 GPTQ 相比,SpQR 相对于 16 位基线的误差减半。
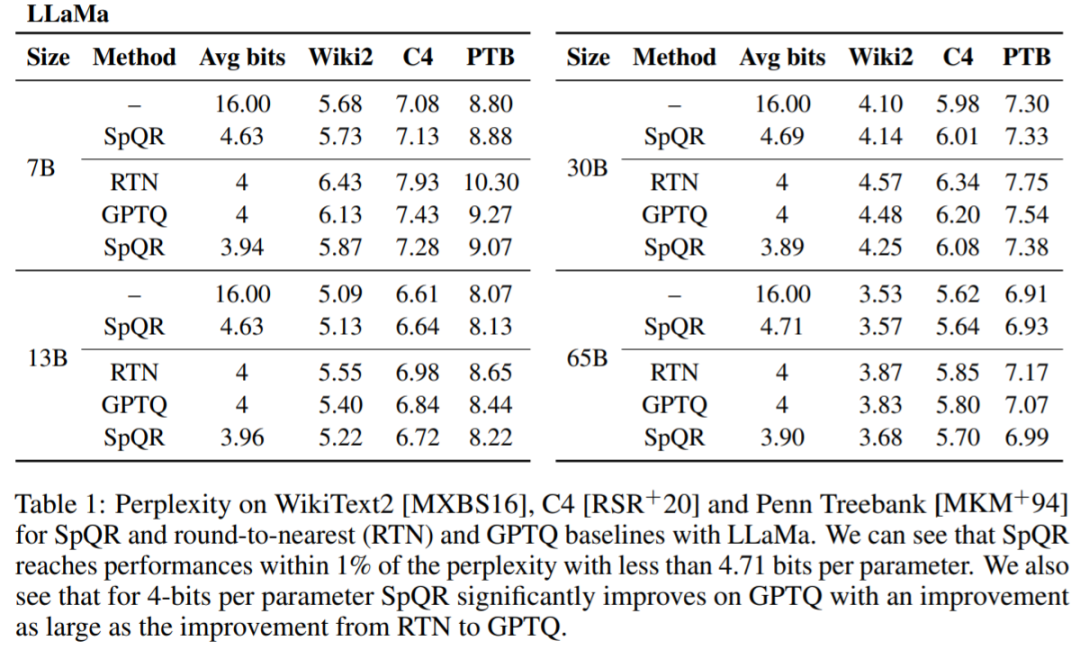
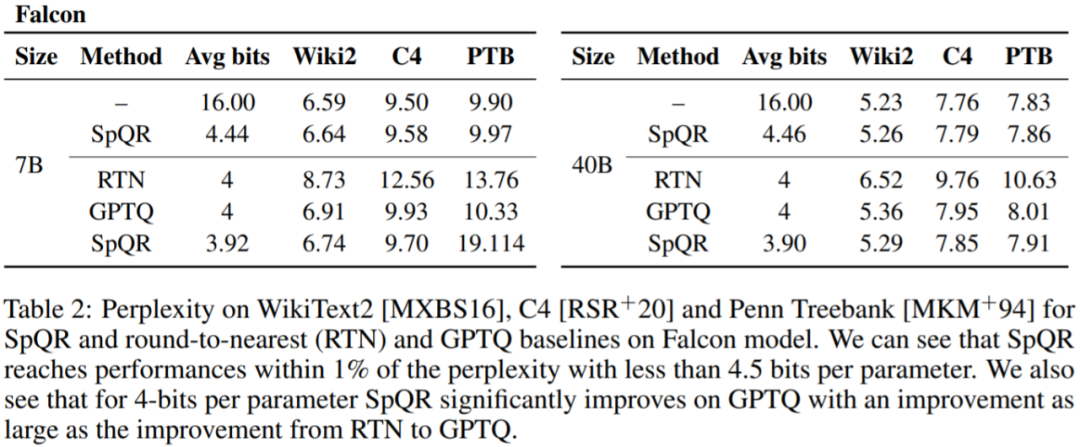
表 3 报告了 LLaMA-65B 模型在不同数据集上的困惑度结果。
最后,该研究评估了 SpQR 推理速度。该研究将专门设计的稀疏矩阵乘法算法与 PyTorch(cuSPARSE)中实现的算法进行了比较,结果如表 4 所示。可以看到,尽管 PyTorch 中的标准稀疏矩阵乘法并没有比 16 位推理更快,但本文专门设计的稀疏矩阵乘法算法可以提高约 20-30% 的速度。

以上就是将330亿参数大模型「塞进」单个消费级GPU,加速15%、性能不减的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/527893.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


















