
kite
-
500万token巨兽,一次读完全套「哈利波特」!比ChatGPT长1000多倍




记性差是目前主流大型语言模型的主要痛点,比如ChatGPT只能输入4096个token(约3000个词),经常聊着聊着就忘了之前说什么了,甚至都不够读一篇短篇小说的。 过短的输入窗口也限制了语言模型的应用场景,比如给一篇科技论文(约1万词)做摘要的时候,需要把文章手动切分后再输入到模型中,不同章节之…
-
上海交通大学溥渊学院教师在《先进材料》发表最新综述:全无机含锡钙钛矿太阳能电池,引领环保光伏技术新潮流
近期,上海交通大学溥渊未来技术学院未来光伏研究中心的赵一新与陈昊团队在国际知名材料科学期刊《先进材料》(《advanced materials》)上发表了题为“‘all-inorganic tin-containing perovskite solar cells: an emerging eco-…
-
Meta无限长文本大模型来了:参数仅7B,已开源


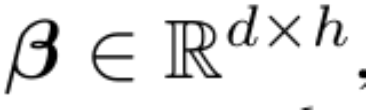
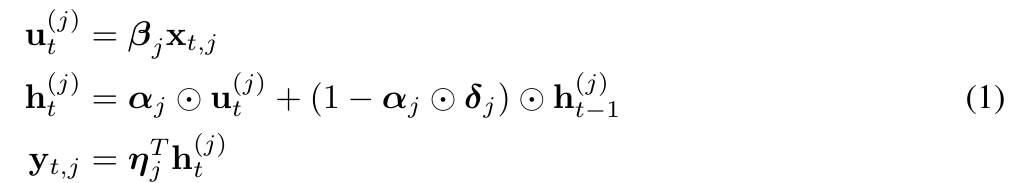
谷歌之后,Meta 也来卷无限长上下文。 transformers的二次复杂度和弱长度外推限制了它们扩展到长序列的能力,虽然存在线性注意力力和状态空间模型等次二次解决方案,但从以往经验来看,它们在预训练效率和下游任务准确性方面表现不佳。 近日,谷歌提出的Infini-Transformer引入了有效…
-
二次元专用超分AI模型APISR:在线可用,入选CVPR



动漫作品如《龙珠》、《神奇宝贝》、《新世纪福音战士》等上个世纪开播的动漫是许多人童年回忆的一部分,它们曾给我们带来了充满了热血、友情与梦想的视觉之旅。某些时候,我们会突然有重温这些童年回忆的冲动,但我们却可能会遗憾地发现这些童年回忆的辨识率非常低,根本无法在宽屏电视上创建出良好的视觉体验,以至于阻碍…
-
编程的“Devin AI 时代”,软件开发者的喜与忧


☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 作者 | Keith Pitt 编译 | 伊风 出品 | 51CTO技术栈(微信号:blog51cto) 这篇文章的作者基思-皮特(Keith Pitt),是一家软件开发公司Buildkite的…
-
大模型承重墙,去掉了就开始摆烂!苹果给出了「超级权重」

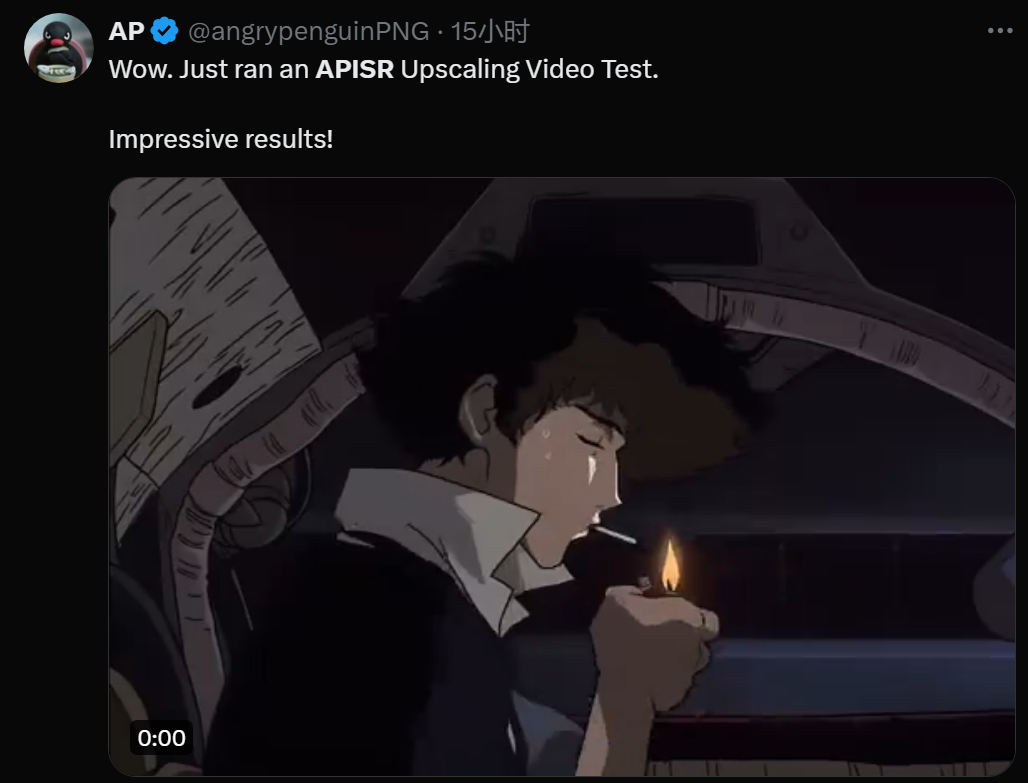
去掉一个「超权重」的影响,比去掉其他 7000 个离群值权重加起来还要严重。 大模型的参数量越来越大,越来越聪明,但它们也越来越奇怪了。 两年前,有研究者发现了一些古怪之处:在大模型中,有一小部分特别重要的特征(称之为「超权重」),它们虽然数量不多,但对模型的表现非常重要。 如果去掉这些「超权重」,…
-
创始人表示用户规模增长快但收入为零,「AI编程神器」Kite停止开发。


你敢相信吗? 曾经拥有50万月活用户的「AI编程神器」Kite,如今却要和我们彻底说拜拜了! Kite是一款由AI驱动的代码补全插件,可以帮助开发者更快地编写代码并保持流畅,并且支持13种语言和16款编辑器。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R…
-
抖音超900万人在用的「卡通脸」特效技术揭秘

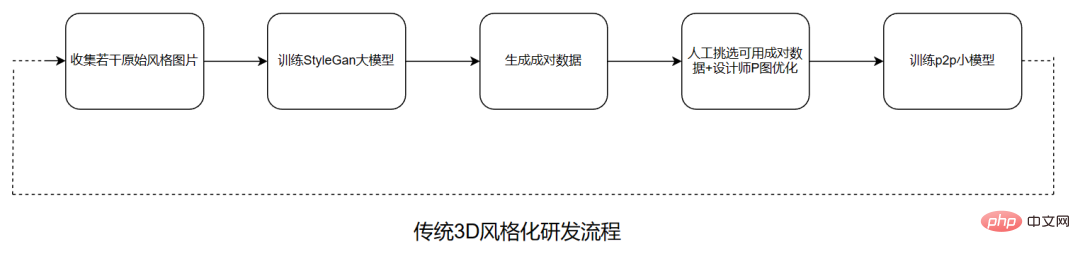
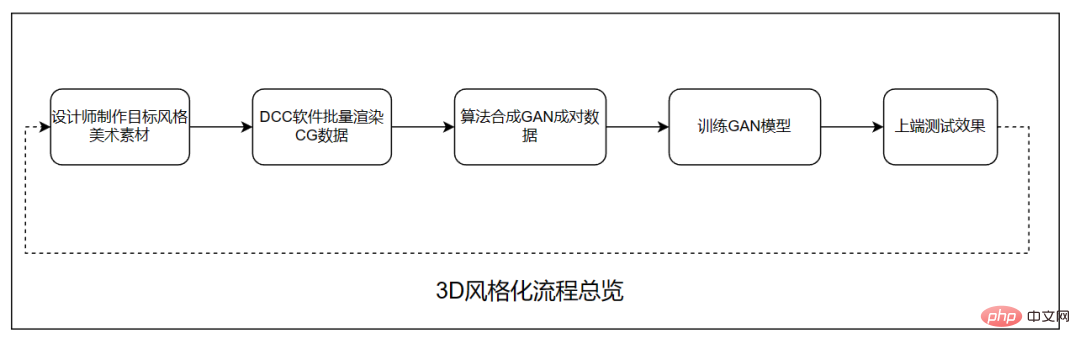
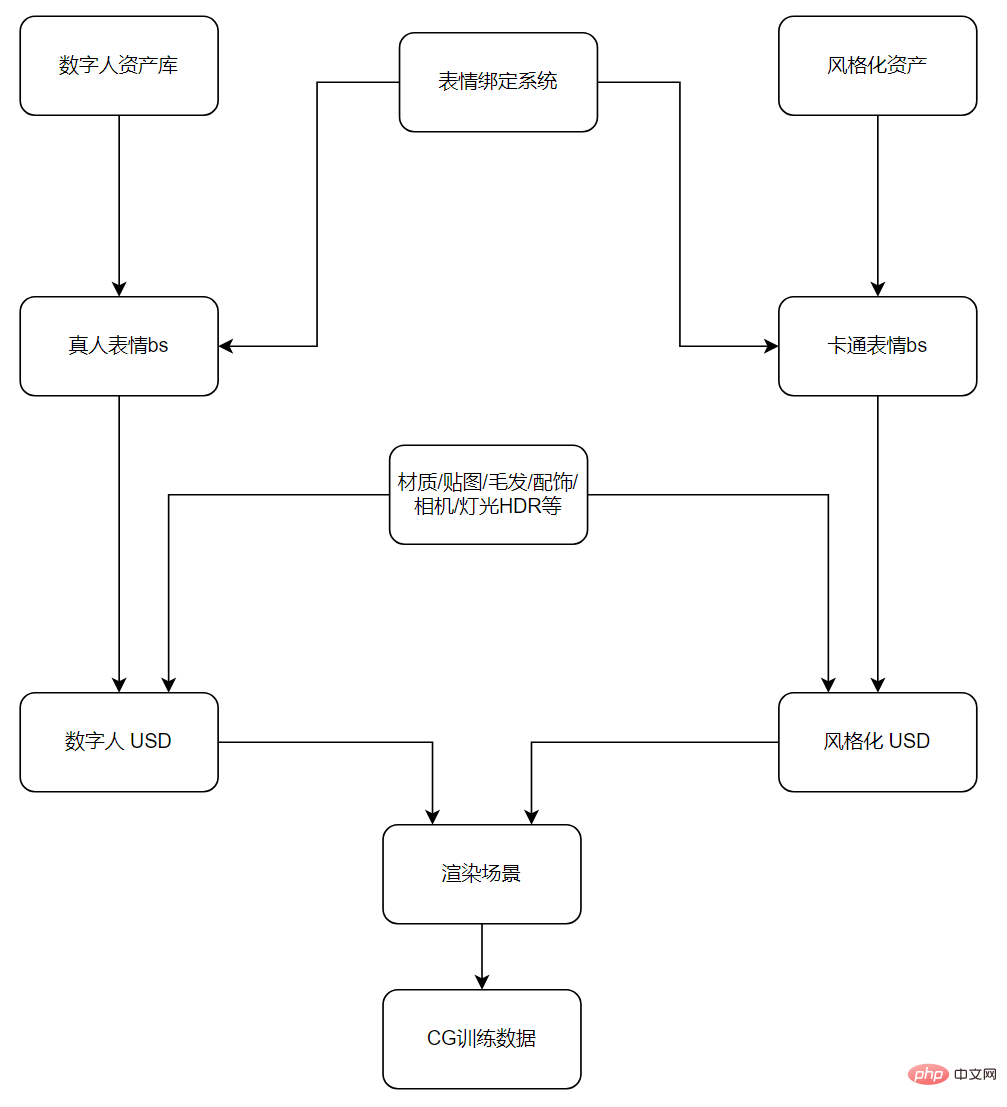
说到特效玩法,抖音的 “整活儿” 能力一直有目共睹。最近,风头正劲的是一款「卡通脸」特效。无论男女老少,用上这款特效后,都仿佛从迪士尼动画里走出来的人物一样灵动可爱。「卡通脸」一经上线,在抖音上迅速发酵,深受用户喜爱,“一键变身高甜卡通脸 ”“全抖音的在逃公主都来了”“用卡通脸花式晒娃 ”“王子公主…
-
将330亿参数大模型「塞进」单个消费级GPU,加速15%、性能不减

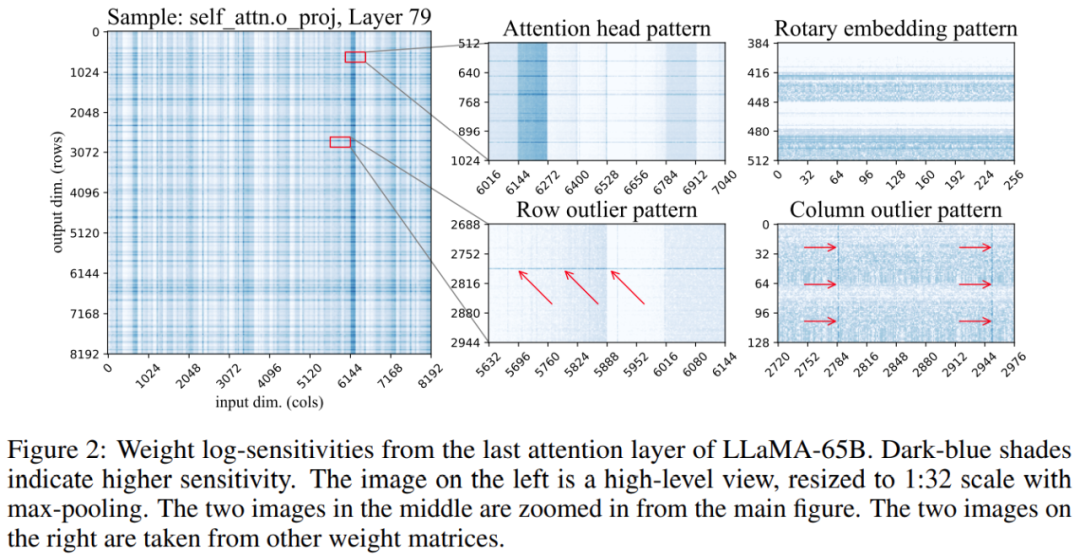
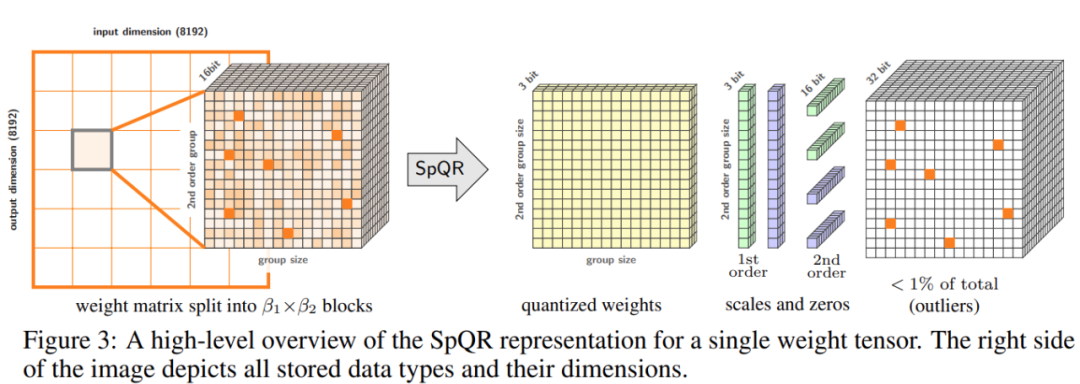

预训练大语言模型(LLM)在特定任务上的性能不断提高,随之而来的是,假如 prompt 指令得当,其可以更好的泛化到更多任务,很多人将这一现象归功于训练数据和参数的增多,然而最近的趋势表明,研究者更多的集中在更小的模型上,不过这些模型是在更多数据上训练而成,因而在推理时更容易使用。 举例来说,参数量…
-
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘


Transformer架构已经横扫了包括自然语言处理、计算机视觉、语音、多模态等多个领域,不过目前只是实验效果非常惊艳,对Transformer工作原理的相关研究仍然十分有限。 其中最大谜团在于,Transformer为什么仅依靠一个「简单的预测损失」就能从梯度训练动态(gradient train…

