
本项目构建了可自定义CNN结构的平台,以手写数字10分类任务为例,涵盖数据准备、网络设计、优化方法、训练验证及效果查看五步。提供含干扰的800张数据集及MNIST,支持自定义模型结构,介绍损失函数、优化器等,通过训练验证评估模型,助力学习者掌握从理论到实践的深度学习路径。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1 项目简介
在深度学习领域,卷积神经网络(CNN)已成为图像识别任务中不可或缺的一部分。本项目【可塑性CNN】旨在提供一个灵活、可自定义的CNN结构构建平台,以10分类的手写数字体任务为例。自己进行尝试和修改模型的结构,通过多次实验,来得到来得到最优的网络配置和参数设置。通过该项目的实验,我们还能够根据实际需求调整CNN的层数和大小,实现最佳的性能和资源平衡。本项目适合深度学习研究者、学生以及对图像识别感兴趣的开发者,旨在提供一个从理论到实践的完整学习路径。这个项目将提供一个平台,一个可自定义的CNN结构构建的平台。各位可通过此简单制作模型的结构,创造属于自己的高效模型。(欢迎大家一起来讨论自己最优的模型结构)
2 任务概述
该任务五个步骤,分别是数据准备、网络结构设计、模型优化方法、模型训练与验证、查看模型效果。
3 数据准备
该项目已经准备好数据集,0-9每一类各80张,共800张。数据拥有不同的,纸张,角度,光照,书写手法,有一定的混乱程度,有助于提升模型的泛化能力。(有干扰项,如光影的影响或实际上纸张的横线等等)也可以使用minist进行,此数据拥有60000张图片,有更好的训练效果。(无实际干扰,每一张图片大小为28*28的像素组成。)
3.1 解压数据
In [ ]
# 解压数据!unzip /home/aistudio/data/data296479/number.zip
3.2 数据加载
In [ ]
dataset = DatasetFolder( '/home/aistudio/number', # 如果更换数据集,需要更改此处和其他路径)# 打印数据集的大小print(f"数量: {len(dataset)}")# 打印数据集的类别print(f"类别: {dataset.classes}")
3.2 数据预处理
3.2.1 图像缩放与归一化
图像缩放(Resizing)和归一化(Normalization)是深度学习中常用的数据预处理技术,它们在图像识别和处理任务中扮演着重要的角色。
3.2.1.1 图像缩放
1.统一输入尺寸:深度学习模型通常需要固定尺寸的输入。图像缩放可以将不同尺寸的图像调整为模型所需的统一尺寸,以便能够输入到模型中。
2.适应网络结构:一些网络结构可能对输入图像的尺寸有特殊要求(如MobileNet输入向量为[1,3,214,214]),图像缩放可以确保图像尺寸与这些要求相匹配。
3.数据增强:通过随机缩放图像,可以生成更多的训练样本,增加数据集的多样性,有助于模型学习到更加鲁棒的特征。
4.改善模型性能:适当的图像缩放可以保留图像中的重要信息,同时减少不必要的细节,这有助于模型更快地收敛并提高性能。
3.2.1.2 图像归一化
1.减少数据方差:归一化可以减少不同特征之间的数值范围差异,使得数据分布更加均匀,有助于模型训练的稳定性和收敛速度。
2.提高模型收敛速度:归一化后的数据可以加快梯度下降的收敛速度,因为数据的分布更加接近标准正态分布,梯度的更新方向更加明3.确。
4.提高模型泛化能力:归一化可以减少数据中的异常值对模型训练的影响,提高模型对新数据的泛化能力。
5.模拟神经网络的激活函数:许多深度学习模型中的激活函数,如ReLU,对输入数据的尺度敏感。归一化可以确保输入数据的尺度适合这6.些激活函数,从而提高模型的性能。
7.数据预处理的标准步骤:在许多机器学习和深度学习任务中,归一化是数据预处理的标准步骤之一,它有助于提高模型训练的效率和效果。
3.2.2 图像缩放与归一化实现
In [ ]
# 定义数据变换,包括转换为Tensor,统一图像大小和归一化transform = paddle.vision.transforms.Compose([ Resize(size=(256, 256)), # 将输入图片resize成统一尺寸 ToTensor(), # 将图片转换为Tensor Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 归一化处理])
In [ ]
# 加载数据集,并应用数据变换dataset = DatasetFolder( '/home/aistudio/number', transform=transform)# 打印数据集的大小print(f"数量: {len(dataset)}")# 打印数据集的类别print(f"类别: {dataset.classes}")
3.2.3 数据增强方法
数据增强对模型泛化能力的提升有很大帮助,它通过对原始数据进行改动来生成新的数据,下面介绍一些数据增强方法。
1.随机裁剪:随机裁剪图像的一部分,生成新的图像样本。
2.随机缩放:改变图像的尺寸,可以是随机缩放或指定缩放到特定尺寸。
3.水平翻转:以一定的概率对图像进行水平翻转。
4.垂直翻转:以一定的概率对图像进行垂直翻转。
5.随机旋转:以一定的角度随机旋转图像。
6.调整亮度、对比度、饱和度:随机调整图像的亮度、对比度和饱和度。
7.灰度转换:将彩色图像转换为灰度图像。
8.随机混合:随机选择两张图像并按一定比例混合,生成新的图像样本。
9.添加噪声:在图像中添加随机噪声,如高斯噪声等。
3.2.4 数据增强实现
In [57]
# 随机混合Mixip和GasssianNoise需要自定义变换from paddle.vision.transforms import Composefrom paddle.vision.transforms import ToTensorfrom paddle.vision.transforms import Normalizefrom paddle.vision.transforms import Resizefrom paddle.vision.transforms import RandomCropfrom paddle.vision.transforms import RandomHorizontalFlipfrom paddle.vision.transforms import RandomVerticalFlipfrom paddle.vision.transforms import RandomRotationfrom paddle.vision.transforms import ColorJitterfrom paddle.vision.transforms import Grayscaletransform = Compose([ RandomCrop(size=32), # 随机裁剪图像到32x32的大小 Resize(size=(224, 224)), # 随机缩放到224x224的大小 RandomHorizontalFlip(), # 以0.5的概率进行水平翻转 RandomVerticalFlip(), # 以0.5的概率进行垂直翻转 RandomRotation(degrees=(0, 360)), # 随机旋转图像,度数范围在次为0°-360°,根据需要也可以是15°, 30°等。 ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), # 随机调整亮度、对比度、饱和度 Grayscale(num_output_channels=3), # 将彩色图像转换为灰度图像,并保持3个通道])
3.2.5 数据集划分
3.2.3.1划分类别
数据集的划分是机器学习项目中的一个关键步骤,它涉及到将数据集分割成不同的部分,用于模型的训练、验证和测试。 一般将数据划分为训练集验证集和测试集三个部分。
训练集:用于模型的训练。通常占大部分数据,如70%-80%。验证集:用于模型的调优,包括超参数的选择和模型结构的调整等等。它帮助模型泛化到未见过的数据上。占比为10%-15%。测试集:用于最终评估模型的性能,完全独立于训练过程(不进行训练),用于模拟模型在实际应用中的表现。占比为10%-15%。
3.2.3.2划分方法
1.随机划分: 最简单的方法,随机选择数据点分配到训练集、验证集和测试集中。
2.分层抽样: 数据集中的类别分布不均匀,可以使用分层抽样确保每个集合中类别的比例与整个数据集一致。
3.时间序列分割: 时间序列数据,通常按照时间顺序将数据划分,以确保训练集、验证集和测试集的时间顺序性。
3.2.6 数据划分实现
In [ ]
import paddlefrom paddle.io import random_splitfrom paddle.vision.datasets import DatasetFolder# 定义划分后的数据集大小train_size = int(0.7 * len(dataset))val_size = int(0.15 * len(dataset))test_size = len(dataset) - train_size - val_size# 划分数据集train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])# 打印各部分数据集的大小print(f"训练集数量: {len(train_dataset)}")print(f"验证集数量: {len(val_dataset)}")print(f"测试集数量: {len(test_dataset)}")
3.3 创建加载器
In [ ]
import paddlefrom paddle.io import DataLoader# 假设 train_dataset, val_dataset, test_dataset 已经被正确地划分和预处理# 创建 DataLoadertrain_loader = DataLoader( train_dataset, batch_size=32, shuffle=True, # 随机打乱数据 drop_last=True # 如果最后一个批次不完整,则丢弃)val_loader = DataLoader( val_dataset, batch_size=32, shuffle=False, # 顺序加载数据 drop_last=False # 保留最后一个不完整的批次)test_loader = DataLoader( test_dataset, batch_size=32, shuffle=False, # 顺序加载数据 drop_last=False # 保留最后一个不完整的批次)
4 网络结构设计
4.1 卷积神经网络
是一种在计算机视觉领域取得了巨大成功的深度学习模型。 它们的设计灵感来自于生物学中的视觉系统,旨在模拟人类视觉处理的方式。 在过去的几年中,CNN已经在图像识别、目标检测、图像生成和许多其他领域取得了显著的进展,成为了计算机视觉和深度学习研究的重要组成部分。 https://cloud.tencent.com/developer/article/2398357
4.2 自定义CNN架构
查看模型使用: https://netron.app/
4.2.1 尝试自定义
In [ ]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Fclass MyCNN(nn.Layer): def __init__(self): super(MyCNN_mycnn, self).__init__() def forward(self, x): return x# 实例化模型model_mycnn = MyCNN()# 打印模型结构paddle.summary(model_mycnn, (1, 3, 256, 256))# 保存模型参数paddle.save(model_mycnn.state_dict(), '/home/aistudio/work/model_mycnn.pdparams')
4.2.2 预定义简单模型
在一个cnn中,卷积层和激活函数是一定需要的,而池化层,归一化层,丢弃层,全连接层(此项目需要),全局池化层,残差链接层,注意力机制等等。不是必要的。
这里给出三个基础模型的结构和定义
最小

In [ ]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Fclass MyCNN_Small(nn.Layer): def __init__(self): super(MyCNN_Small, self).__init__() self.conv1 = nn.Conv2D(in_channels=3, out_channels=16, kernel_size=3, padding=1) self.pool1 = nn.MaxPool2D(kernel_size=2, stride=2) self.conv2 = nn.Conv2D(in_channels=16, out_channels=32, kernel_size=3, padding=1) self.pool2 = nn.MaxPool2D(kernel_size=2, stride=2) # 计算全连接层输入特征数 self.in_features = 32 * (256 // 4) * (256 // 4) # 256 输入大小, 4 两次下采样(2×2) self.fc1 = nn.Linear(in_features=self.in_features, out_features=10) def forward(self, x): x = self.pool1(F.relu(self.conv1(x))) x = self.pool2(F.relu(self.conv2(x))) x = paddle.flatten(x, start_axis=1) x = self.fc1(x) return x# 实例化模型model_small = MyCNN_Small()# 打印模型结构paddle.summary(model_small, (1, 3, 256, 256))# 保存模型参数paddle.save(model_small.state_dict(), '/home/aistudio/work/model_small.pdparams')
较小

In [ ]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Fclass MyCNN_Medium(nn.Layer): def __init__(self): super(MyCNN_Medium, self).__init__() self.conv1 = nn.Conv2D(in_channels=3, out_channels=32, kernel_size=3, padding=1) self.pool1 = nn.MaxPool2D(kernel_size=2, stride=2) self.conv2 = nn.Conv2D(in_channels=32, out_channels=64, kernel_size=3, padding=1) self.pool2 = nn.MaxPool2D(kernel_size=2, stride=2) self.conv3 = nn.Conv2D(in_channels=64, out_channels=128, kernel_size=3, padding=1) self.pool3 = nn.MaxPool2D(kernel_size=2, stride=2) # 计算全连接层输入特征数 self.in_features = 128 * (256 // 8) * (256 // 8) # 256 输入大小, 8 三次下采样 (2x2) self.fc1 = nn.Linear(in_features=self.in_features, out_features=10) def forward(self, x): x = self.pool1(F.relu(self.conv1(x))) x = self.pool2(F.relu(self.conv2(x))) x = self.pool3(F.relu(self.conv3(x))) x = paddle.flatten(x, start_axis=1) x = self.fc1(x) return x# 实例化模型model_medium = MyCNN_Medium()# 打印模型结构paddle.summary(model_medium, (1, 3, 256, 256))# 保存模型参数paddle.save(model_medium.state_dict(), '/home/aistudio/work/model_medium.pdparams')
较大

In [ ]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Fclass MyCNN_Large(nn.Layer): def __init__(self): super(MyCNN_Large, self).__init__() self.conv1 = nn.Conv2D(in_channels=3, out_channels=64, kernel_size=3, padding=1) self.pool1 = nn.MaxPool2D(kernel_size=2, stride=2) self.conv2 = nn.Conv2D(in_channels=64, out_channels=128, kernel_size=3, padding=1) self.pool2 = nn.MaxPool2D(kernel_size=2, stride=2) self.conv3 = nn.Conv2D(in_channels=128, out_channels=256, kernel_size=3, padding=1) self.pool3 = nn.MaxPool2D(kernel_size=2, stride=2) self.conv4 = nn.Conv2D(in_channels=256, out_channels=512, kernel_size=3, padding=1) self.pool4 = nn.MaxPool2D(kernel_size=2, stride=2) # 计算全连接层输入特征数 self.in_features = 512 * (256 // 16) * (256 // 16) # 256 输入大小, 16 四次下采样 (2x2) self.fc1 = nn.Linear(in_features=self.in_features, out_features=10) def forward(self, x): x = self.pool1(F.relu(self.conv1(x))) x = self.pool2(F.relu(self.conv2(x))) x = self.pool3(F.relu(self.conv3(x))) x = self.pool4(F.relu(self.conv4(x))) x = paddle.flatten(x, start_axis=1) x = self.fc1(x) return x# 实例化模型model_large = MyCNN_Large()# 打印模型结构paddle.summary(model_large, (1, 3, 256, 256))# 保存模型参数paddle.save(model_large.state_dict(), '/home/aistudio/work/model_large.pdparams')
4.3 模型可是化工具
此项目中使用此进行模型可视化 : https://netron.app/
5 模型优化方法
5.1 损失函数选择
损失函数(Loss Function)是衡量模型预测值与真实值之间差异的函数,它指导模型在训练过程中的优化方向。对于手写数字识别问题,通常使用交叉熵损失
交叉熵损失(Cross-Entropy Loss):多分类问题中最常用的损失函数,衡量模型输出的概率分布与真实标签的概率分布之间的差异。 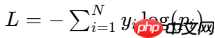
yi是真实标签的独热编码,pi是模型预测的概率。
其他的损失函数通常有;
1.平均绝对误差(Mean Absolute Error, MAE):计算预测值与真实值之间差的绝对值的平均值,通常用于回归问题。
2.对数损失(Log Loss):也称为对数似然损失,用于衡量模型输出的概率分布与真实标签之间的差异,常用于分类问题。
3.多类别交叉熵损失(Categorical Cross-Entropy Loss):用于多分类问题,衡量模型预测的概率分布与真实标签之间的差异。
4.二分类交叉熵损失(Binary Cross-Entropy Loss):用于二分类问题,衡量模型预测的概率与真实标签之间的差异。
5.余弦相似度损失(Cosine Similarity Loss):用于衡量两个向量之间的余弦相似度,常用于相似性学习任务。
6.希尔伯特-施密特口袋(Hilbert-Schmidt Independence Criterion, HSIC):用于衡量两个随机变量之间的独立性,可用于特征选择和独立性测试。
7.Huber损失(Huber Loss):结合了均方误差和平均绝对误差的特点,对异常值具有鲁棒性。
8.感知器损失(Perceptron Loss):用于线性分类问题,特别是在感知器算法中。
9.Hinge损失(Hinge Loss):用于支持向量机(SVM)中,确保正确分类的同时,最大化最近的类别边界。
10.Kullback-Leibler散度(KL散度):用于衡量两个概率分布之间的差异,常用于变分自编码器(VAE)等概率模型。
11.负对数似然损失(Negative Log Likelihood Loss):用于概率模型中,衡量模型预测的概率分布与真实标签之间的差异。
来自;https://blog.csdn.net/Next_SummerAgain/article/details/129550772
5.2 优化器算法
优化器(Optimizer)算法是用来更新模型参数的算法,它们根据损失函数的梯度来调整参数,以最小化损失函数。常用的优化器包括:
1.随机梯度下降(SGD):最基本的优化算法,通过随机采样的方式来更新模型参数。
2.Adam:结合了动量(Momentum)和RMSprop的思想,自适应调整每个参数的学习率,通常表现良好。
3.RMSprop:通过调整梯度的平方的累积平均值来调整学习率。 选择不同的优化器可能会影响模型的收敛速度和最终性能。
5.3 评估指标
评估指标(Evaluation Metrics)是用来衡量模型性能的指标,对于手写数字识别任务,常用的评估指标包括:
1.准确率(Accuracy):模型预测正确的样本数占总样本数的比例。
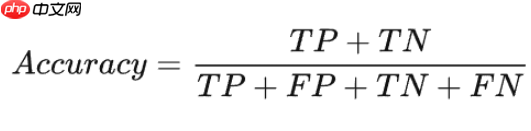
2.精确率(Precision):在预测为正的样本中,实际为正的样本比例。

3.召回率(Recall):在所有实际为正的样本中,被预测为正的样本比例。
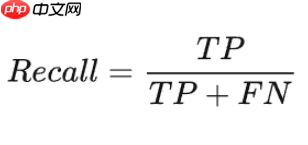
4.F1分数(F1 Score):精确率和召回率的调和平均值,是两者之间的平衡指标。
6 模型训练与验证
6.1 训练准备
6.1.1 选择损失函数和优化器
In [ ]
# 定义损失函数和优化器loss_fn = nn.CrossEntropyLoss()optimizer = paddle.optimizer.Adam(parameters=model_large.parameters(), learning_rate=0.001)
6.1.2 定义训练函数
In [ ]
# 训练函数def train(model, loader, loss_fn, optimizer): model.train() total_loss = 0 for batch_id, (data, label) in enumerate(loader): pred = model(data) loss = loss_fn(pred, label) loss.backward() optimizer.step() optimizer.clear_grad() total_loss += loss.item() return total_loss / len(loader)
6.1.3 定义验证函数
In [ ]
import paddledef valid(model, loader, loss_fn): model.eval() # 设置模型为评估模式 total_loss = 0 accuracy_metric = paddle.metric.Accuracy() # 创建准确率计算对象 with paddle.no_grad(): # 在验证过程中不需要计算梯度 for batch_id, (data, label) in enumerate(loader): pred = model(data) loss = loss_fn(pred, label) total_loss += loss.item() # 确保标签是二维的 label = paddle.unsqueeze(label, axis=1) # 计算预测正确的样本数和总样本数 correct = accuracy_metric.compute(pred, label) accuracy_metric.update(correct, label.shape[0]) # 获取累积准确率 accuracy = accuracy_metric.accumulate() return total_loss / len(loader), accuracy
6.2 设置训练和验证
In [ ]
# 训练和验证循环epochs = 10 # 定义为训练10轮for epoch in range(epochs): train_loss = train(model_large, train_loader, loss_fn, optimizer) val_loss, val_acc = valid(model_large, val_loader, loss_fn) print(f"Epoch {epoch+1}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}")
6.3 模型保存
In [ ]
# 保存模型参数paddle.save(model_large.state_dict(), '/home/aistudio/work/lager/final_model_1.pdparams')
7 查看模型效果
7.1 加载模型
In [ ]
import paddlepath = '/home/aistudio/work/lager/final_model_1.pdparams' ## 替换为模型路径model_large = MyCNN_Large()state_dict = paddle.load(path)model_large.set_state_dict(state_dict)
7.2 对图像进行预测
In [ ]
import matplotlib.pyplot as pltimport numpy as np# 确保模型处于评估模式model_large.eval()# 准备一个用于存储预测结果的列表predictions = []# 不计算梯度,节省内存和计算资源with paddle.no_grad(): for batch_id, (data, label) in enumerate(val_loader): # 进行预测 pred = model_large(data) # 应用 softmax 函数获取概率分布 pred_class = paddle.argmax(pred, axis=1).numpy() predictions.extend(pred_class) # 将预测结果添加到列表中
7.3 查看模型预测效果
In [ ]
# 选择一些样本进行展示num_samples = 10for i in range(num_samples): # 获取一张验证集图像 img, label = next(iter(val_loader)) img = img[i].numpy().transpose((1, 2, 0)) # 转换为HxWxC格式 label = label[i].numpy() # 获取模型的预测结果 pred_class = predictions[i] # 创建一个新的图形 plt.figure(figsize=(12, 6)) # 显示图像 plt.subplot(1, 2, 1) plt.imshow(img) plt.title(f"Actual: {label} predict:{predictions[i]}") plt.axis('off') plt.tight_layout() plt.show()
7.4 检查模型准确率
In [ ]
import paddlemodel_large.eval()# 初始化准确率计数器correct = 0total = 0# 不计算梯度,节省内存和计算资源with paddle.no_grad(): for data, label in test_loader: # 进行预测 pred = model_large(data) # 获取预测结果中最可能的类别 pred_class = paddle.argmax(pred, axis=1) # 计算正确预测的数量 correct += (pred_class == label).sum().item() # 计算总的样本数量 total += label.shape[0]# 计算准确率accuracy = correct / totalprint(f"Test 准确率: {accuracy:.4f}")
8 项目总结
随着项目的完成,我们逐渐完成构建了一个能够处理图像数据的卷积神经网络模型,当然通过项目的实践,我们能够自己组合不同的神经网络并泰索更多的什么网络,也可以通过这个项目来探索不同优化器和损失函数对模型的影响,此外,我们还可以加深对深度学习理论的理解。
以上就是【可塑性架构】自定义CNN手写数字识别的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/52869.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























