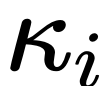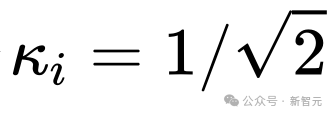Transformer 作为 NLP 预训练模型架构,能够有效的在大型未标记的数据上进行学习,研究已经证明,Transformer 是自 BERT 以来 NLP 任务的核心架构。
最近的工作表明,状态空间模型(SSM)是长范围序列建模有利的竞争架构。SSM 在语音生成和 Long Range Arena 基准上取得了 SOTA 成果,甚至优于 Transformer 架构。除了提高准确率之外,基于 SSM 的 routing 层也不会随着序列长度的增长而呈现二次复杂性。
本文中,来自康奈尔大学、 DeepMind 等机构的研究者提出了双向门控 SSM (BiGS),用于无需注意力的预训练,其主要是将 SSM routing 与基于乘法门控(multiplicative gating)的架构相结合。该研究发现 SSM 本身在 NLP 的预训练中表现不佳,但集成到乘法门控架构中后,下游准确率便会提高。
实验表明,在受控设置下对相同数据进行训练,BiGS 能够与 BERT 模型的性能相匹配。通过在更长的实例上进行额外预训练,在将输入序列扩展到 4096 时,模型还能保持线性时间。分析表明,乘法门控是必要的,它修复了 SSM 模型在变长文本输入上的一些特定问题。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/pdf/2212.10544.pdf
方法介绍
SSM 通过以下微分方程将连续输入 u (t) 与输出 y (t) 联系起来:
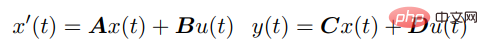
对于离散序列,SSM 参数被离散化,其过程可以近似为:
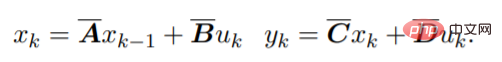
这个方程可以解释为一个线性 RNN,其中 x_k 是一个隐藏状态。y 也可以用卷积计算:
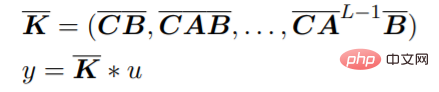
Gu 等人展示了一种在神经网络中使用 SSM 的有效方法,他们开发了参数化 A 的方法,称为 HiPPO,其产生了一个稳定而高效的架构,称为 S4。这保留了 SSM 对长期序列建模的能力,同时比 RNN 训练更有效。最近,研究人员提出了 S4 的简化对角化版本,它通过对原始参数更简单的近似实现了类似的结果。在高层次上,基于 SSM 的 routing 为神经网络中的序列建模提供了一种替代方法,而无需二次计算的注意力成本。
预训练模型架构
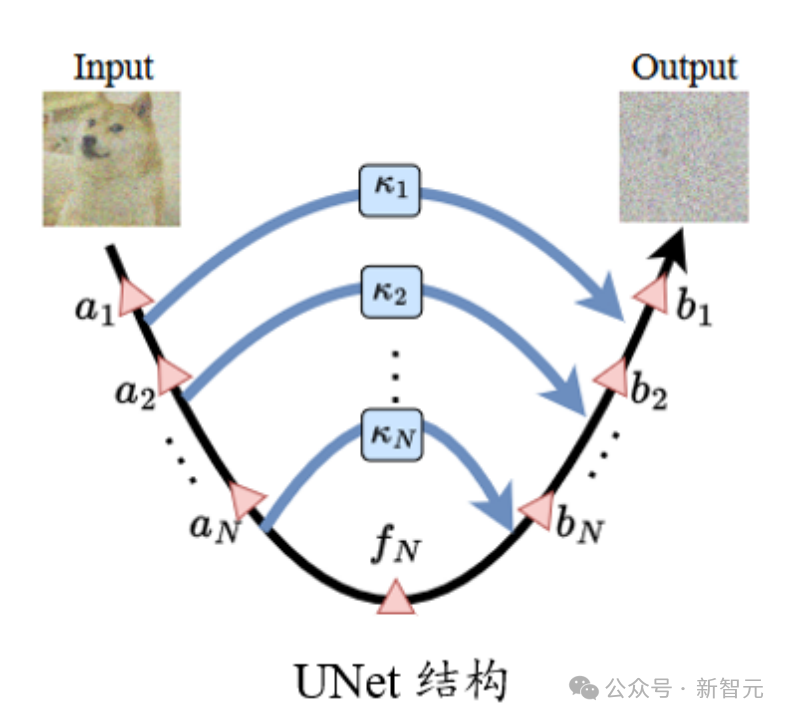
SSM 能取代预训练中的注意力吗?为了回答这个问题,该研究考虑了两种不同的架构,如图 1 所示的堆叠架构(STACK)和乘法门控架构(GATED)。
具有自注意力的堆叠架构相当于 BERT /transformer 模型,门控架构是门控单元的双向改编,最近也被用于单向 SSM。带有乘法门控的 2 个序列块(即前向和后向 SSM)夹在前馈层中。为了进行公平比较,门控架构的大小保持与堆叠架构相当。
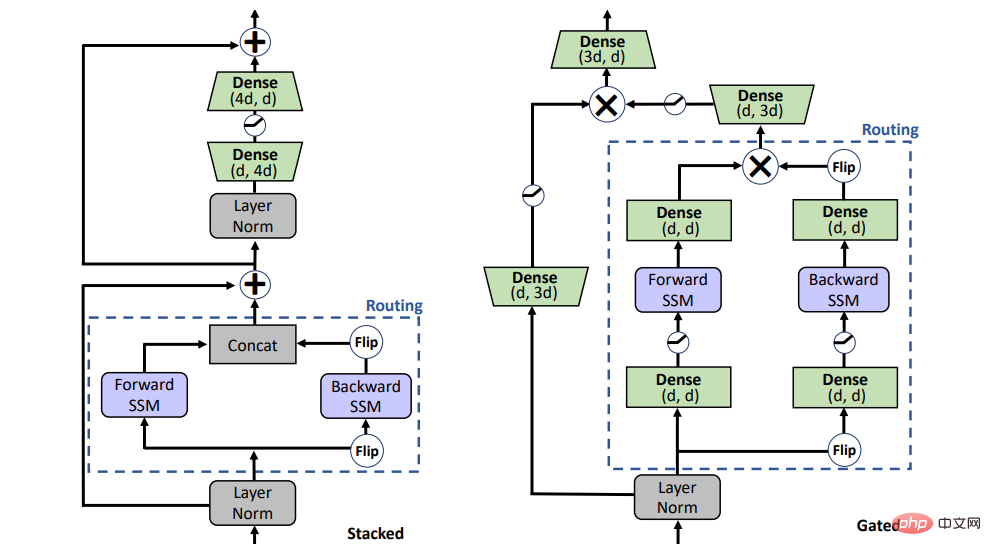
图 1:模型变量。STACK 是标准 transformer 架构,GATED 为基于门控单元。对于 Routing 组件(虚线),该研究同时考虑双向 SSM(如图所示)和标准自注意力。门控(X)表示逐元素乘法。
实验结果
预训练
表 1 显示了 GLUE 基准测试中不同预训练模型的主要结果。BiGS 在 token 扩展上复制了 BERT 的准确率。这一结果表明,在这样的计算预算下,SSM 可以复制预训练 transformer 模型的准确率。这些结果明显优于其他基于非注意力的预训练模型。想要达到这个准确率,乘法门控是必要的。在没有门控的情况下,堆叠 SSM 的结果明显更差。为了检查这种优势是否主要来自于门控的使用,本文使用 GATE 架构训练了一个基于注意力的模型;然而,结果显示该模型的效果实际上低于 BERT。
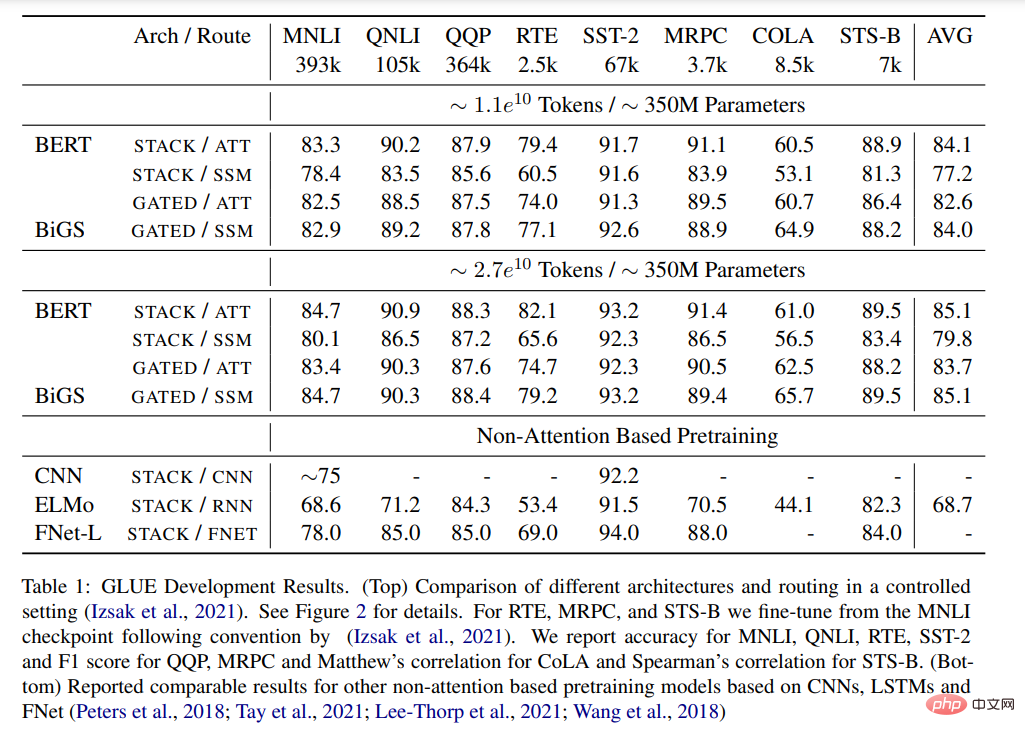
表 1:GLUE 结果。(Top)在控制设置下,不同架构和 routing 的比较。参见图 2 了解详细信息。(Bottom) 报告了基于 CNN、LSTM 和 FNet 的其他非注意力预训练模型的可比结果。
 通义万相
通义万相
通义万相,一个不断进化的AI艺术创作大模型
 596 查看详情
596 查看详情 
Long-Form 任务
表 2 结果显示,可以将 SSM 与 Longformer EncoderDecoder (LED) 和 BART 进行比较,但是,结果显示它在远程任务中表现得也不错,甚至更胜一筹。与其他两种方法相比,SSM 的预训练数据要少得多。即使 SSM 不需要在这些长度上进行近似,长格式也依旧很重要。
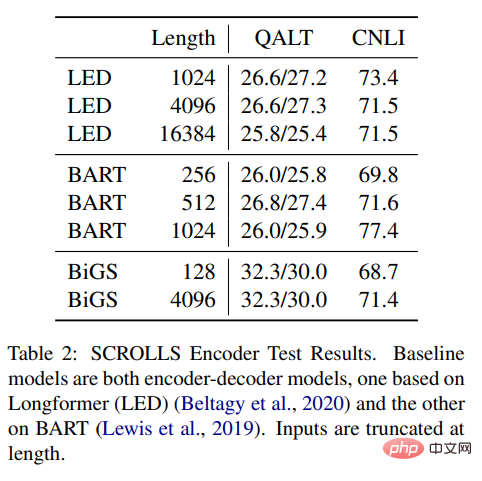
表 2:SCROLLS Encoder 测试结果。基线模型都是编码器 —— 解码器模型,一个基于 Longformer (LED),另一个基于 BART。输入的长度有截断。
更多内容请查看原论文。
以上就是预训练无需注意力,扩展到4096个token不成问题,与BERT相当的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/550180.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫