天工大模型
天工大模型
中国首个对标ChatGPT的双千亿级大语言模型
 115 查看详情
115 查看详情 
以下为卢志武教授在机器之心举办的 ChatGPT 及大模型技术大会上的演讲内容,机器之心进行了不改变原意的编辑、整理:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

大家好,我是中国人民大学卢志武。我今天报告的题目是《ChatGPT 对多模态通用生成模型的重要启发》,包含四部分内容。

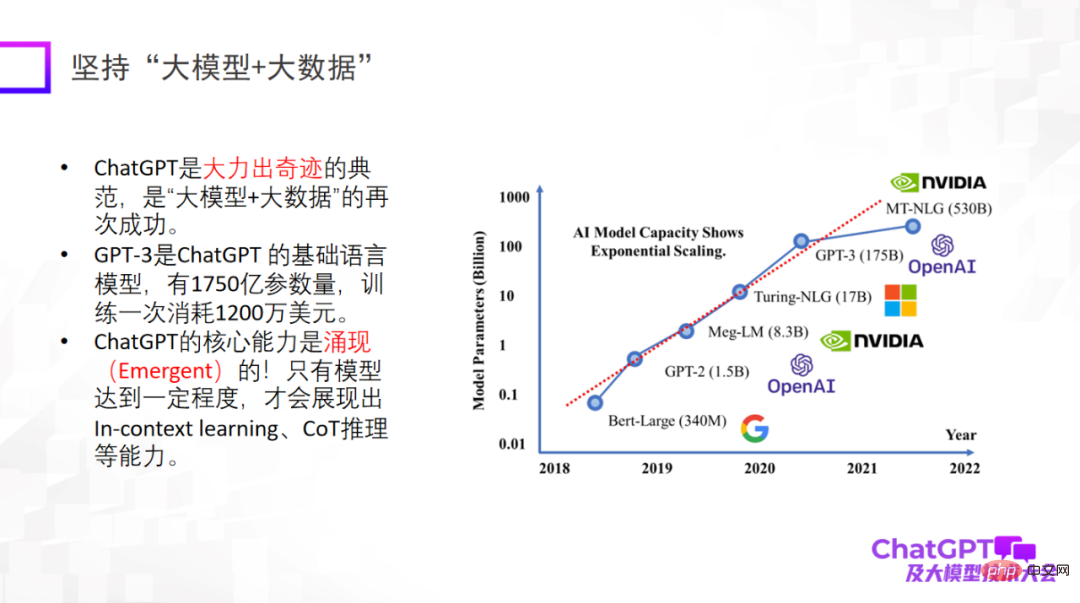
首先,ChatGPT 带给我们一些关于研究范式革新的启发。第一点就是要使用「大模型 + 大数据」,这是一个已经被再三被验证过的研究范式,也是 ChatGPT 的基础研究范式。特别要强调一点,大模型大到一定程度的时候才会有涌现(emergent)能力,比如 In-context learning、CoT 推理等能力,这些能力令人感到非常惊艳。
第二点是要坚持「大模型 + 推理」,这也是 ChatGPT 让我印象最深刻的一点。因为在机器学习或者人工智能领域,推理被公认为是最难的,而 ChatGPT 在这一点上也有所突破。当然,ChatGPT 的推理能力可能主要来自代码训练,但是否有必然的联系还不能确定。在推理方面,我们应该下更多的工夫,搞清楚它到底来自什么,或者还有没有别的训练方式把它的推理能力进一步增强。
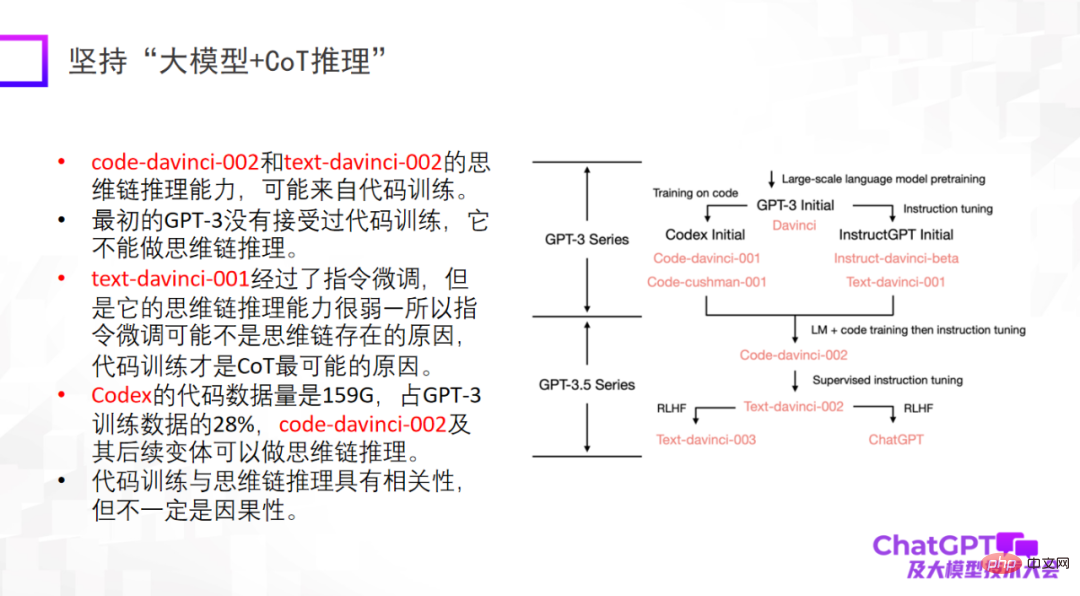
第三点是大模型一定要和人类对齐(alignment),这是 ChatGPT 在工程角度或模型落地角度给我们的重要启示。如果没有与人类对齐的话,模型会生成很多有害的信息,让模型无法使用。第三点不是说提高模型的上限,而是模型的可靠性和安全性的确非常重要。
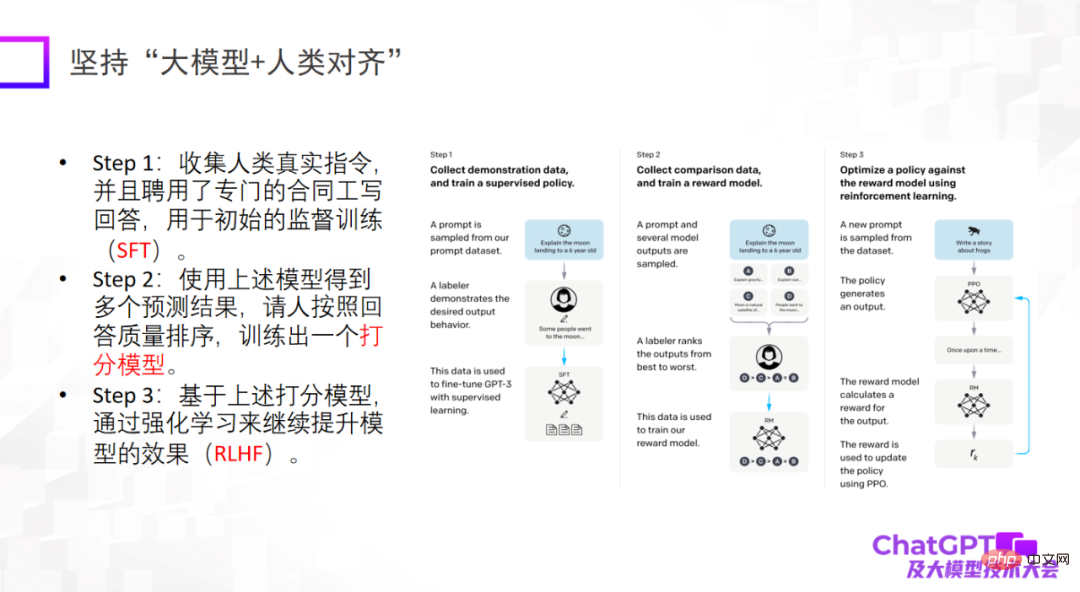
ChatGPT 的问世对很多领域,包括我自己,都有非常大的触动。因为我自己做多模态做了好几年,我会开始反思为什么我们没有做出这么厉害的模型。
ChatGPT 是在语言或者文字上的通用生成,下面我们来了解一下多模态通用生成领域的最新进展。多模态预训练模型已开始向多模态通用生成模型转变,并有了一些初步的探索。首先我们看一下谷歌 2019 年提出的 Flamingo 模型,下图是它的模型结构。
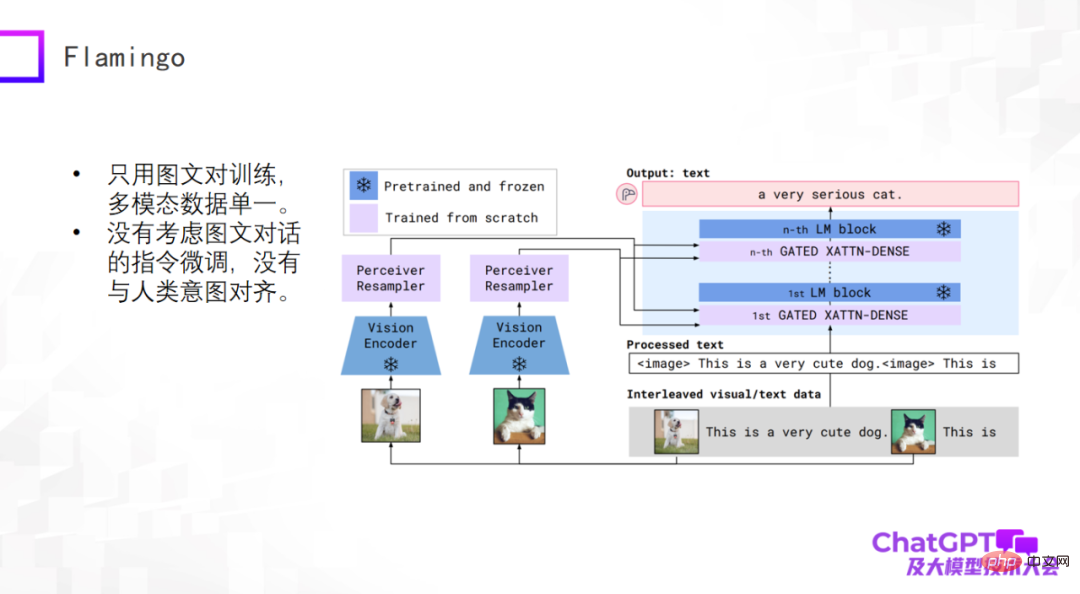
Flamingo 模型架构的主体是大型语言模型的解码器(Decoder),即上图右侧蓝色模块,在每个蓝色模块之间加了一些 adapter 层,左侧视觉的部分是添加了视觉编码器(Vision Encoder)和感知器重采样器(Perceiver Resampler)。整个模型的设计就是要把视觉的东西通过编码和转换,经过 adapter,跟语言对齐,这样模型就可以为图像自动生成文本描述。
Flamingo 这样的架构设计有什么好处呢?首先,上图中的蓝色模块是固定不动的(frozen),其中包括语言模型 Decoder;而粉色模块本身的参数量是可以控制的,所以 Flamingo 模型实际上训练的参数量是很少的。所以大家不要觉得多模态通用生成模型很难做,其实没有那么悲观。经过训练的 Flamingo 模型就可以做很多基于文本生成的通用任务,当然输入还是多模态的,比如做视频描述、视觉问答、多模态对话等。从这个角度看 Flamingo 算是一个通用生成模型。
第二个例子是前段时间新发布的 BLIP-2 模型,它是基于 BLIP-1 改进的,它的模型架构和 Flamingo 特别像,基本还是包含图像编码器和大型语言模型的解码器,这两部分是固定不动的, 然后中间加了一个具有转换器作用的 Q-Former—— 从视觉转换到语言。那么,BLIP-2 真正需要训练的部分就是 Q-Former。
如下图所示,首先将一张图(右边的图)输入到 Image Encoder,中间的 Text 是用户提出的问题或者指令,经过 Q-Former 编码以后输入到大型语言模型里,最后把答案生成出来,大概是这样一个生成过程。
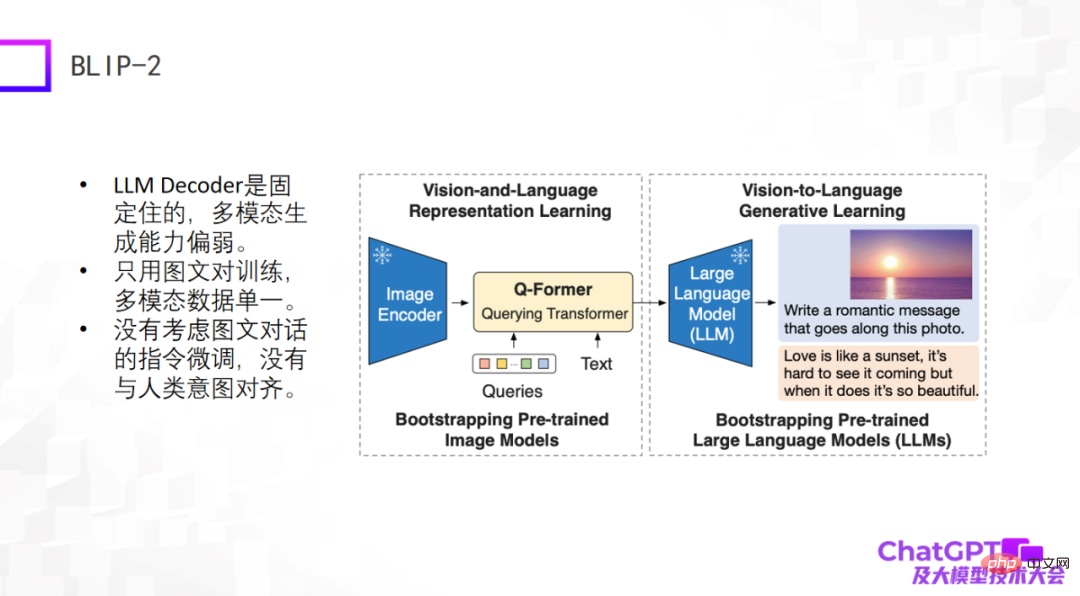
这两种模型的缺点很明显,因为它们出现的比较早或者刚出现,还没有考虑 ChatGPT 用到的工程手段,至少在图文对话或者多模态对话上没有做指令微调,所以它们整体的生成效果不尽如人意。
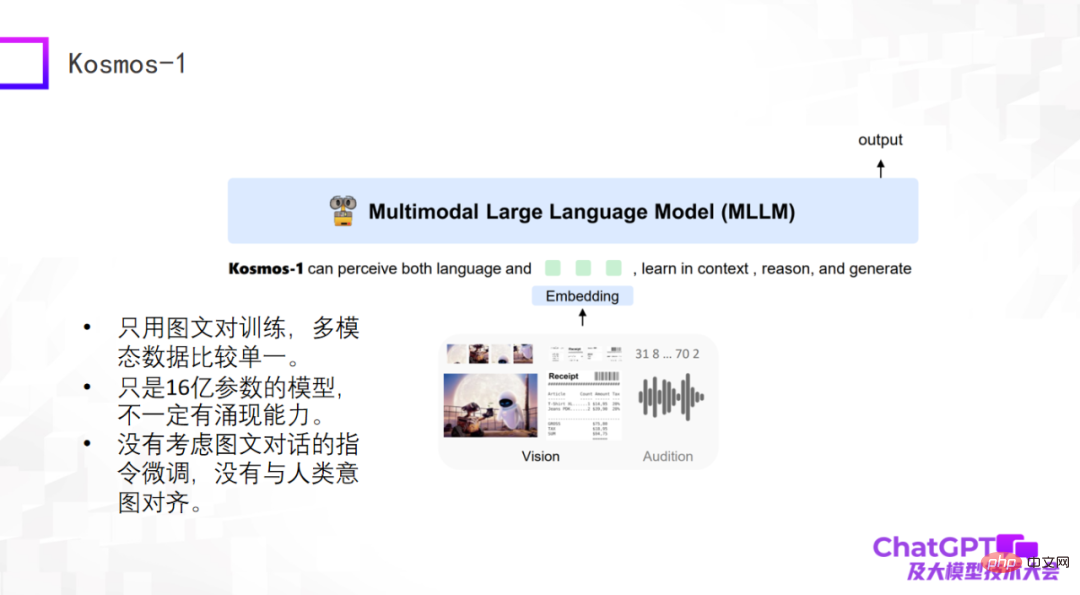
第三个是微软最近发布的 Kosmos-1,它的结构特别简单,并且只用图文对进行训练,多模态数据比较单一。Kosmos-1 跟上面两个模型最大的差别是:上面两个模型中的大语言模型本身是固定不动的,而 Kosmos-1 中的大型语言模型本身是要经过训练的,因此 Kosmos-1 模型的参数量只有 16 亿,而 16 亿参数的模型未必有涌现能力。当然,Kosmos-1 也没考虑图文对话上的指令微调,导致它有时也会胡说八道。
下一个例子是谷歌的多模态具身视觉语言模型 PaLM-E。PaLM-E 模型和前三个例子是大同小异的,PaLM-E 也用了 ViT + 大型语言模型。PaLM-E 最大的突破是它终于在机器人领域探索了一下多模态大语言模型的落地可能性。PaLM-E 尝试了第一步探索,但是它考虑的机器人任务类型很有限,并不能达到真正的通用。

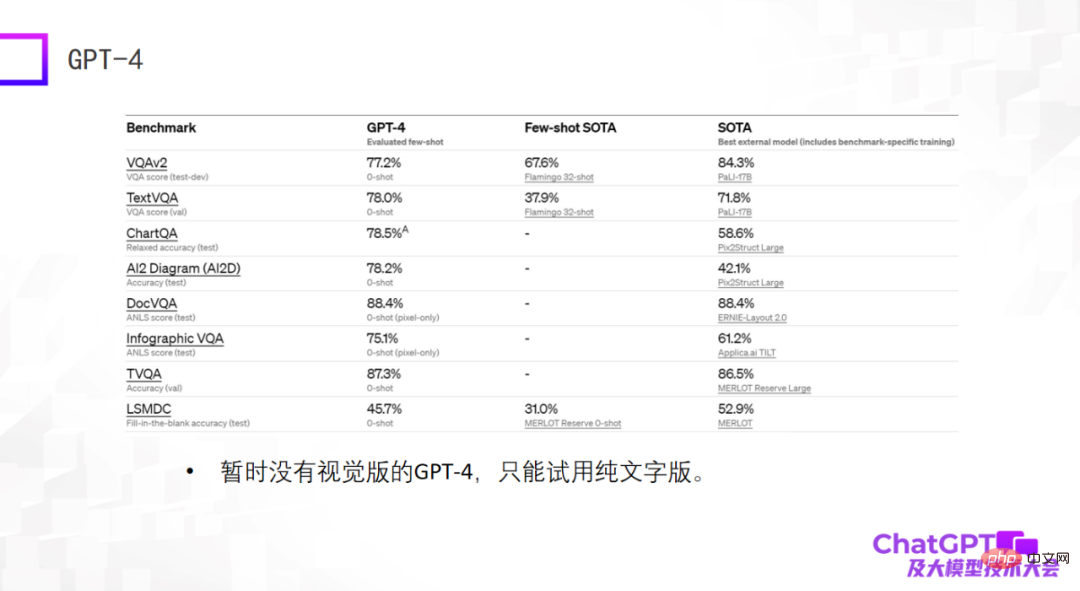
最后一个例子是 GPT-4—— 在标准数据集上给出了特别惊人的结果,很多时候它的结果甚至比目前在数据集上训练微调过的 SOTA 模型还要好。这可能会让人特别震惊,但实际上这个评测结果并不代表什么。我们在两年前做多模态大模型时就发现大模型的能力不能在标准数据集上评估,在标准数据集上表现好并不代表实际使用的时候效果好,这两个之间有很大的 gap。出于这个原因,我对目前的 GPT-4 有些许失望,因为它只给出了标准数据集上的结果。而且目前可用的 GPT-4 还不是视觉版的,只是纯文字版的。
上面几个模型总体来说是做通用的语言生成,输入是多模态输入,下面这两个模型就不一样了 —— 不仅要做通用语言生成,还要做视觉生成,既能生成语言也能生成图像。
首先是微软的 Visual ChatGPT,我简单评价一下。这个模型的思路特别简单,更多是产品设计上的考虑。与视觉有关的生成有很多种,还有一些视觉检测模型,这些不同任务的输入、指令千差万别,问题就是怎么用一个模型把这些任务全部包含进来,所以微软设计了 Prompt 管理器,核心部分用到了 OpenAI 的 ChatGPT,相当于把不同视觉生成任务的指令,通过 ChatGPT 翻译过来。用户的问题是自然语言描述的指令,通过 ChatGPT 把它翻译成机器能懂的指令。

Visual ChatGPT 就是做了这样一个事情。所以从产品的角度看确实很好,但从模型设计的角度看却没有新的东西。所以整体从模型的层面看是一个「缝合怪」,没有统一的模型训练,导致不同模态之间没有互相促进。我们为什么做多模态,因为我们相信不同模态数据之间一定是互相帮助的。并且 Visual ChatGPT 也没考虑多模态生成指令微调,它的指令微调只是依赖于 ChatGPT 本身。
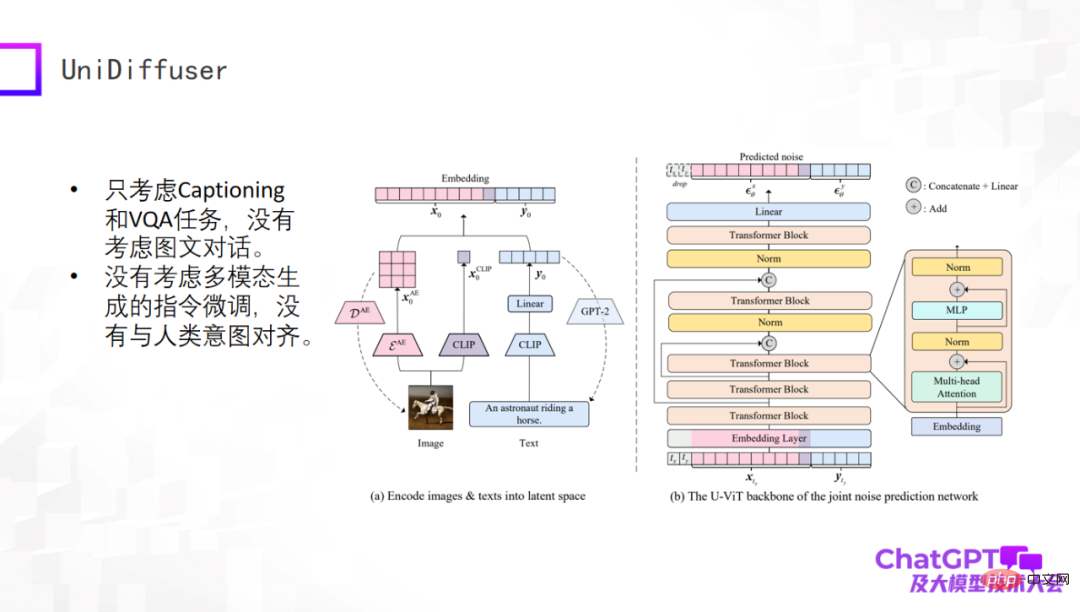
下一个例子是清华朱军老师的团队发布的 UniDiffuser 模型。这个模型从学术角度真正做到了多模态输入生成文字、生成视觉内容,这得益于他们基于 transformer 的网络架构 U-ViT,类似于 Stable Diffusion 最核心的部件 U-Net,进而把图像的生成和文本的生成统一在一个框架里。这个工作本身是很有意义的,但还是比较初期,比如只考虑了 Captioning 和 VQA 任务,没有考虑多轮对话,也没有做多模态生成上的指令微调。
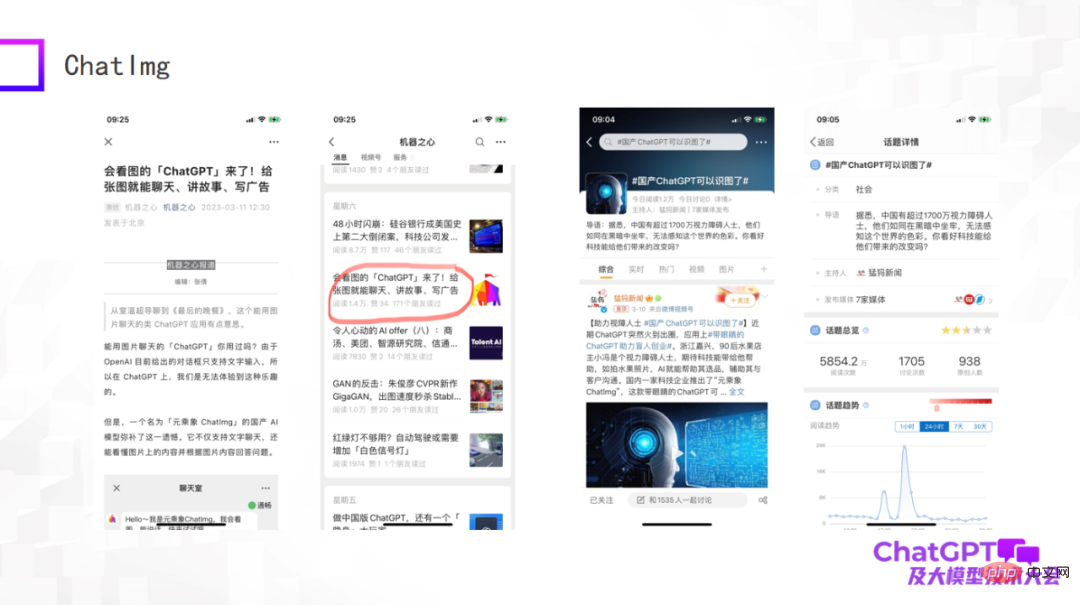
前面评价了这么多,那我们自己也做了一个产品叫 ChatImg,如下图所示。总体来说,ChatImg 包含图像编码器、图文多模态编码器和文本解码器,和 Flamingo、BLIP-2 是类似的,但是我们考虑的更多,具体实现的时候有细节差异。
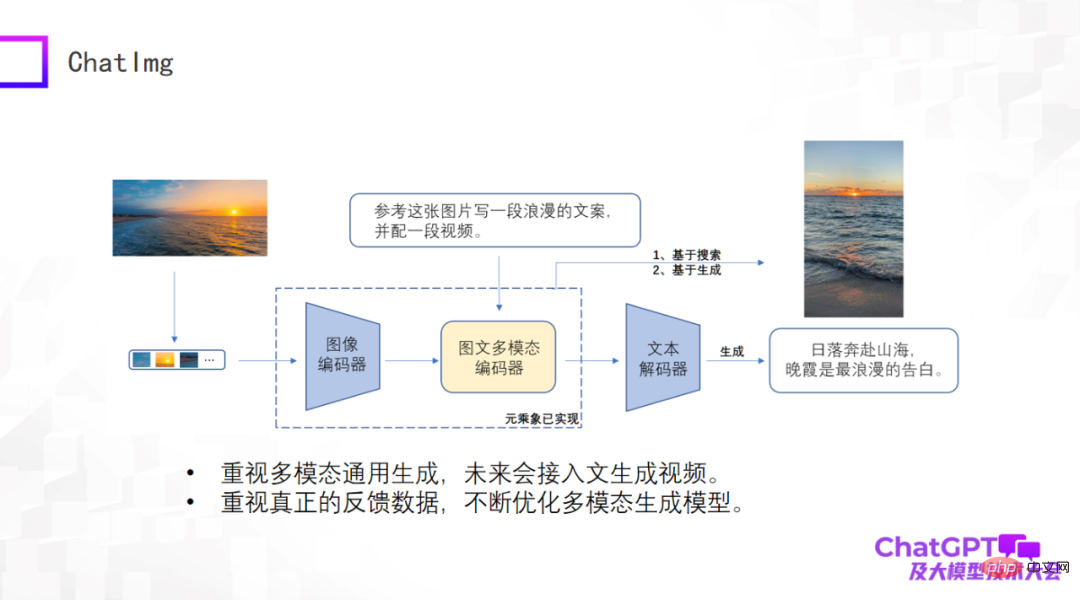
ChatImg 最大的一个优势是可以接受视频输入。我们特别重视多模态通用生成,包括生成文字、生成图像、生成视频。我们希望在这一个框架里实现多种生成任务,最终希望接入文字生成视频。
第二,我们特别重视真实用户的数据,我们希望得到真实用户数据以后不停优化生成模型本身,提高它的能力,所以我们发布了 ChatImg 应用。
下图是我们测试的一些例子,作为一个初期模型,虽然还有一些做得不好的地方,但总体来说 ChatImg 对图片的理解还是可以的。比如,ChatImg 可以在对话中生成对画作的描述,也能做一些 In-context learning。

上图第一个例子描述了《星夜》这幅画,在描述中 ChatImg 称梵高是美国画家,你告诉它错了,它马上就可以纠正过来;第二个例子 ChatImg 对图中的物体做出了物理推断;第三个例子是我自己拍的一张照片,这个照片里面有两道彩虹,它准确地识别到了。
我们注意到上图第三和第四个例子涉及到情绪方面的问题。这其实与我们接下来要做的工作有关,我们想把 ChatImg 接入到机器人里面去。现在的机器人通常是被动的,所有的指令全部是预设的,显得很呆板。我们希望接入 ChatImg 的机器人可以主动和人交流。怎么做到这一点呢?首先机器人一定要能感受到人,可能是客观地看到世界的状态和人的情绪,也可能是获得一种反映;然后机器人才能理解,才能跟人主动交流。通过这两个例子我感觉这个目标是可以实现的。
最后,我总结一下今天的报告。首先,ChatGPT 和 GPT-4 带来了研究范式的革新,我们所有人都应该去积极拥抱这个变化,不能抱怨,不能找借口说没有资源,只要去面对这个变化,总有办法克服困难。多模态研究甚至也不需要几百卡的机器,只要采用对应的策略,少量的机器也可以做出很好的工作。第二,现有的多模态生成模型都存在各自的问题,GPT-4 还没有开放视觉版,我们所有人也都还有机会。并且,我认为 GPT-4 还有一个问题,就是多模态生成模型最终应该是什么样子它没有给一个完美答案(实际上是没有透露 GPT-4 的任何细节)。这其实是一件好事,全世界的人都很聪明,每个人都有自己的想法,这可能会形成百花齐放的研究新局面。我的演讲就到这里,谢谢大家。

以上就是”中国人民大学研究员卢志武提出ChatGPT对多模态生成模型的重要影响”的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/555677.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫