
百度手机助手如何绑定苹果账号?
1、启动百度手机助手,进入主界面后点击右上角的“设置”选项,如下图所示:
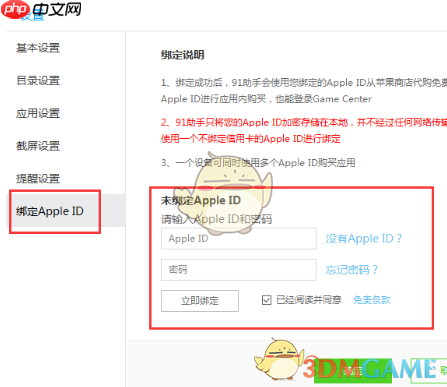
2、进入“设置”页面后,在左侧菜单中选择“绑定Apple ID”,右侧即可看到相关功能入口;
 百度GBI
百度GBI
百度GBI-你的大模型商业分析助手
 104 查看详情
104 查看详情 
3、在“未绑定Apple ID”区域,根据提示输入您的Apple ID及密码,确认无误后点击“立即绑定”完成操作。
以上就是《百度手机助手》绑定苹果id教程的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/573201.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















