
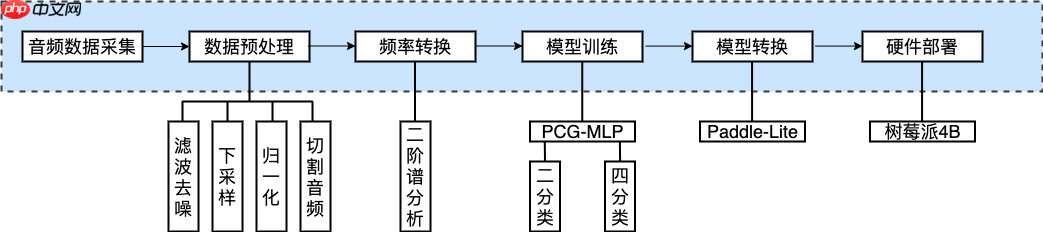
该项目基于PaddlePaddle框架构建智能心音检测模型,并部署于树莓派4B。通过电子听诊器采集心音,先经模型检测正常与否,异常则进一步分为四种病症。数据经降噪、下采样等预处理,用二阶谱分析法提取特征,构建融合卷积与MLP的模型。训练后,经Paddle-Lite转换部署到树莓派,结合显示屏实现实时检测。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于PaddlePaddle框架的智能心音检测模型+树莓派4B部署实践
竞赛简介
“中国高校计算机大赛 — 人工智能创意赛”(以下简称“竞赛”)是面向全国高校各专业在校学生的科技创新类竞赛,由教育部高等学校计算机类专业教学指导委员会、教育部高等学校软件工程专业教学指导委员会、教育部高等学校大学计算机课程教学指导委员会、全国高等学校计算机教育研究会于 2018 年联合创办,在国内外高校产生了广泛影响 ,并已被列入中国高等教育学会“全国普通高校大学生竞赛排行榜”。第四届(2021年)竞赛由全国高等学校计算机教育研究会主办,浙江大学、百度公司联合承办。竞赛旨在激发学生创新意识,提升人工智能创新实践应用能力,培养团队合作精神,促进校际交流,丰富校园学术气氛,推动“人工智能 + X”知识体系下的人才培养
竞赛官网:http://aicontest.baidu.com
项目背景
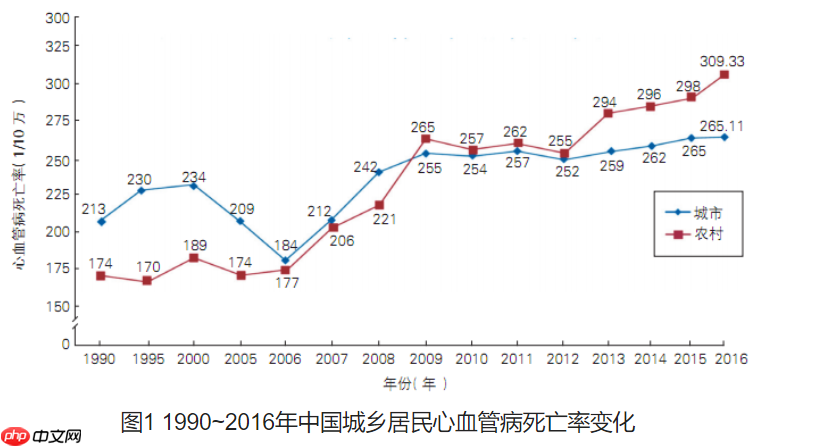
心脏病是全球致命疾病之首,尤其潜伏在大量中老年人群体中,而心音信号在心血管疾病检测、临床诊断等方面具有重要支撑作用。随着社会人口老龄化的不断加剧以及人们生活压力的不断增加,中老年人身体状况的日常化实时监控凸显地尤为重要。心音实时监控可为潜在心脏病患者提供智能监控和及时提醒,同时缓解人力医疗资源不足等问题。针对当下心音监测设备诊断方式简易、监测结果单一且易受外界条件干扰、受众群体对设备可信度较低等问题,本项目研究旨从心音频率信号解读的角度实现实时精准的潜在心脏病患者日常化监控,提升大众对智能化心音监测的信心。下图是1990~2016年中国城乡居民心血管病死亡率变化。
任务目标
通过听诊器实时采集病人心音信号,然后调用树莓派上部署好的心音检测模型进行预测。
首先检测病人心音是正常信号或不正常信号,若是不正常信号再进行四分类。
目前仅支持四种病情分类,包含主动脉瓣狭窄(AS)、二尖瓣狭窄(MS)、二尖瓣反流(MR)、二尖瓣脱垂(MVP)。
任务流程如下所示:
硬件准备
树莓派4B装好Raspberry Pi OS的镜像源的SD卡(注意⚠️: Paddle Lite目前不支持arm Ubuntu)树莓派1.3寸IPS LCD扩展板 显示屏(1.3inch LCD HAT)ETZ-1A(C)型电子听诊器
数据准备
本项目中的模型训练数据主要来源于各类心音相关比赛的公开数据集,数据链接在下面。
Dataset1:https://github.com/yaseen21khan/Classification-of-Heart-Sound-Signal-Using-Multiple-Features-
Dataset2:https://physionet.org/content/challenge-2016/1.0.0/#files
Dataset3:https://www.kaggle.com/kinguistics/heartbeat-sounds
Dataset4:http://www.peterjbentley.com/heartchallenge/
通过对这些数据集进行融合处理,最后组成两套数据。分别用来训练识别正常心音与非正常心音,另外一套用来识别四分类。
项目代码结构
项目代码结构如下所示,包含数据预处理和网络训练及树莓派上运行的脚本文件。
PCG_Categrieos_Detection/├── Dataset│ ├── dataset_2_categories # 二分类数据(共4399个)│ └── dataset_4_categories # 四分类数据(共800个)├── dataset2.npy # 预处理后保存的二分类数据├── dataset4.npy # 预处理后保存的四分类数据├── model_weights # 模型训练完成后保存的权重文件│ ├── model_2.pdiparams│ ├── model_2.pdiparams.info│ ├── model_2.pdmodel│ ├── model_4.pdiparams│ ├── model_4.pdiparams.info│ └── model_4.pdmodel├── extract_bispectrum.py # 数据预处理├── PCG_MLP.py # 网络定义├── polycoherence.py # 二阶谱分析法├── rasbeery_inference.py # 在树莓派运行的脚本├── read_data.py # 读取数据└── train.py # 训练网络
0 深度学习任务开发流程
对于一个任务,当你想使用深度学习来解决时,一般流程如下:

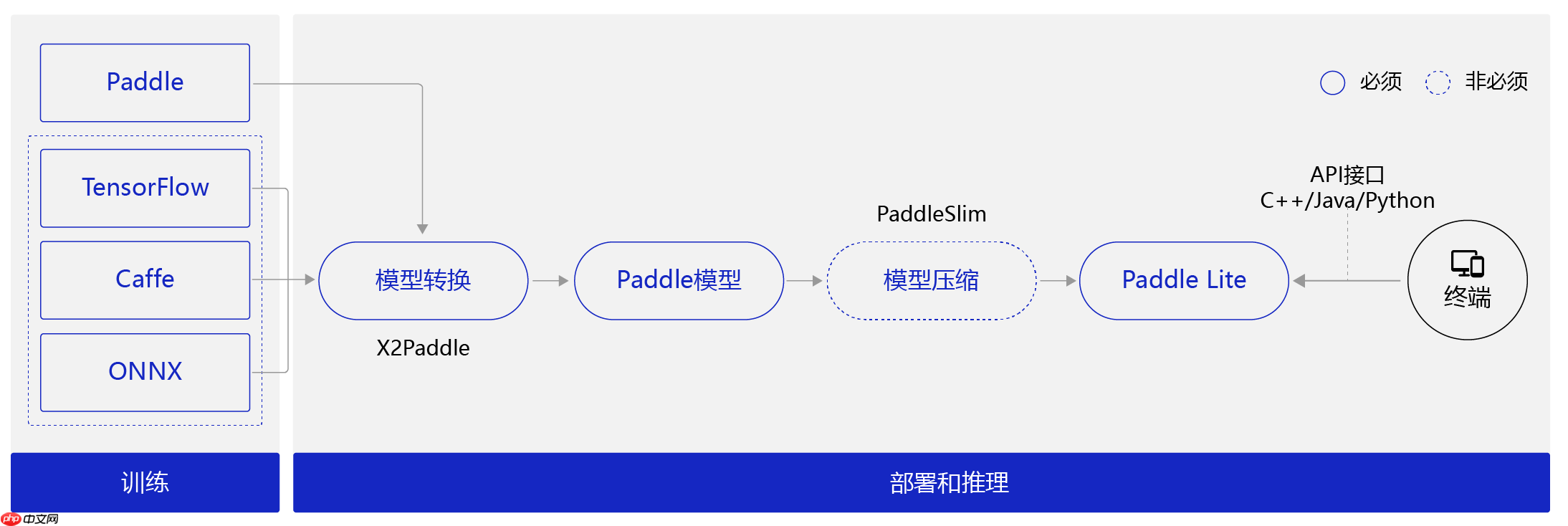
我们使用收集到的数据集,搭建深度学习模型,训练并调优,最后还需要将模型部署到树莓派4B设备上,实现离线方式的部署。由于Paddle暂时不支持在arm架构的系统上安装,所以我们选择采取在树莓派上使用Paddle-Lite进行部署。
因为受到部署侧限制,部署的设备算力并不高,内存也小,在没有GPU、NPU等加速的情况下使用CPU进行深度学习运算。虽然深度学习的前向传播运算并没有反向传播那么的吃算力,但是对于移动端设备来说也是非常大的计算量了。
所以我们在模型选择时需要轻量级小参数的模型。使用小模型还需要保证精度,这也是面临的一个难点。最后我们参考了目前比较热门的MLP网络结构,将其应用在心音信号识别任务上,取得了不错的效果,最后保存的模型大小在600KB以内。
树莓派上使用Paddle-Lite部署需要哪些准备?
模型训练阶段:主要解决模型训练,利用标注数据训练出对应的模型文件。(PS:面向端侧进行模型设计时,需要考虑模型大小和计算量)
模型部署阶段:
模型转换:对于非Paddle框架训练的模型,Paddle提提供了X2Paddle工具将模型转换到飞桨的格式。
模型压缩:由于移动端硬件性能的限制,如果模型过于庞大不便于部署。借助PaddleSlim提供的剪枝、量化等手段优化模型大小,以便在端上使用。
将模型部署到Paddle Lite。
在终端上通过调用Paddle Lite提供的API接口(C++、Java、Python等API接口),完成推理相关的计算。
1 模型训练
准备数据(数据预处理)搭建网络(基础API&动态图)模型训练&保存(动态图转为静态图再保存)模型测试
1.1 准备数据(数据预处理)
不同数据集的音频数据制作标准差异很大,这种差异包括:音频采样率,通道数,长短,降噪法等等。我们在融合数据集之前需要最大可能地统一这些标准。因此,我们需要对所有的音频文件进行数据预处理。
读取音频音频降噪下采样归一化切割音频In [7]
# 读取音频import librosaimport matplotlib.pyplot as pltdef plot_signal(audio_data, title=None): plt.figure(figsize=(9, 3.0), dpi=300) plt.plot(audio_data, linewidth=1) plt.title(title,fontsize = 16) plt.tick_params(labelsize=12) plt.grid() plt.show()# 路径需根据实际情况修改,这里以‘work/dataset2/normal/b0031.wav’为例audio_path = 'work/PCG_Categrieos_Detection/Dataset/dataset_2_categories/normal/New_N_001.wav'audio_data, fs = librosa.load(audio_path, sr=None)plot_signal(audio_data, title='Initial Audio')
In [7]
# 音频降噪# 由于音频在制作时不可避免地会保存一部分噪声,我们需对音频文件进行数字滤波,旨在滤除高频噪声以及直流噪声,同时尽可能保留心音信号。我们把音频送入二阶25-400hz的巴特沃斯中值滤波器,并可视化音频。from scipy import signaldef band_pass_filter(original_signal, order, fc1,fc2, fs): ''' 中值滤波器 :param original_signal: 音频数据 :param order: 滤波器阶数 :param fc1: 截止频率 :param fc2: 截止频率 :param fs: 音频采样率 :return: 滤波后的音频数据 ''' b, a = signal.butter(N=order, Wn=[2*fc1/fs,2*fc2/fs], btype='bandpass') new_signal = signal.lfilter(b, a, original_signal) return new_signalaudio_data = band_pass_filter(audio_data, 2, 25, 400, fs)plot_signal(audio_data, title='After Filter')
In [11]
# 音频下采样# 为了降低模型的计算量,我们对所有的音频信号进行下采样,考虑到我们已经对音频进行了25-400hz的中值滤波,根据奈奎斯特采样定律,我们把信号下采样到1000hz。这里我们调用samplerate包来完成这项工作,并可视化音频。import samplerate# AIStudio自带环境中并没有samplerate工具包,需要先下载,在终端中输入 pip install samplerate 即可完成安装# 下采样down_sample_audio_data = samplerate.resample(audio_data.T, 1000 / fs, converter_type='sinc_best').Tplot_signal(down_sample_audio_data, title='Down_sampled')
In [12]
# 归一化# 由于不同数据集中的音频文件尺度差异较大,我们对所有的音频信号进行归一化,使其范围在[-1,1]区间内,并可视化音频import numpy as npdown_sample_audio_data = down_sample_audio_data / np.max(np.abs(down_sample_audio_data))plot_signal(down_sample_audio_data, title='Normalized')
In [13]
# 切割音频# 由于最终数据集数据来源于不同渠道,音频的时间不一致。为了尽可能多利用已有的数据集,我们对较长的音频进行切割。我们以2.5s为单位对音频进行切割。total_num = len(down_sample_audio_data)/(2500)# 计算切割次数fig = plt.figure(figsize=(12, 5), dpi=300)ax1 = fig.add_subplot(2,1,1)plt.plot(down_sample_audio_data,linewidth=1)plt.title('Cut Audio(With Overlap)',fontsize=16)plt.tick_params(labelsize=12)plt.ylim([-1.2,1.2])plt.grid()for j in range(int(total_num)): plt.vlines(j*2500, -1.2, 1.2, color="red",linestyle='--',linewidth=1.1)ax2 = fig.add_subplot(2, 1, 2)plt.plot(down_sample_audio_data, linewidth=1)for j in range(int(total_num)): plt.vlines(j*2500 + 1250, -1.2, 1.2, color="green",linestyle='--',linewidth=1.1)plt.ylim([-1.2,1.2])plt.grid()plt.show()
构建Dataset,飞桨2.0关于数据集定义与加载的使用方式可参考官方文档
In [16]
from paddle.io import Dataset, DataLoaderclass MyDataset(Dataset): """ 步骤一:继承paddle.io.Dataset类 """ def __init__(self, data, label): """ 步骤二:实现构造函数,定义数据集大小 """ super(MyDataset, self).__init__() self.data = data self.label = label def __getitem__(self, index): """ 步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签) """ # for img, lab in zip(self.data, self.label): return self.data[index], self.label[index] def __len__(self): """ 步骤四:实现__len__方法,返回数据集总数目 """ return len(self.data)
1.2 特征工程(二阶谱分析法)
数据集整理得到后,那么我们开始对所有的数据进行频率转换。Ali Mohammad Alqudah等人的研究已证明,现代数字信号处理领域中的高阶谱分析方法提取出的特征明显优于短时傅里叶变换、小波变换等低阶特征提取方法的结果。
此外,高阶谱方法中的二阶谱法使用最为广泛,它可以很好地抑制信号中的相位关系,检测与量化非高斯信号的相位耦合,常被用于非平稳的医学信号,如EEG、ECG、EMG。因此我们采用二阶谱分析法来进行特征提取,二阶谱分析法可用如下公示表示:
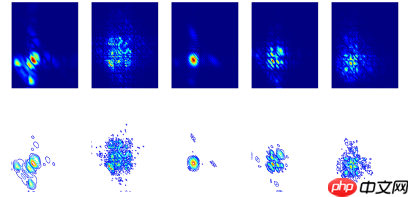
我们选了五种不同类别的心音信号,可发现不同类别的心音信号的二阶谱图差异是很大。这将大大帮助我们进行心音分类。
这里指给出部分关键代码,具体代码请见extract_bispectrum.py
【代码】
import librosa # librosa是一个用于音乐和音频分析的 python 包。它提供了创建音乐信息检索系统所需的构建块。from scipy.fftpack import next_fast_len # fftpack用于进行傅立叶变换计算from scipy.signal import spectrogram # 处理声音信号def get_bi_spectrum(file_folder, class_list, data_num=2000): # dataset = np.zeros((1,1,256,256)) dataset = [] for class_nam in class_list: path = os.path.join(file_folder, class_nam) all_files = get_all_filenames(path) # index = 0 for name in all_files[:data_num]: file_path = os.path.join(path, name) sig, sr = librosa.load(file_path, sr=1000) # load heart sound data freq1, freq2, bi_spectrum = polycoherence(sig,nfft=1024, fs = 1000, norm=None,noverlap = 100, nperseg=256) bi_spectrum = np.array(abs(bi_spectrum)) # calculate bi_spectrum bi_spectrum = 255 * (bi_spectrum - np.min(bi_spectrum)) / (np.max(bi_spectrum) - np.min(bi_spectrum)) bi_spectrum = bi_spectrum.reshape((1, 256, 256)) dataset.append(bi_spectrum) # concat the dataset return dataset
1.2 搭建网络
网络介绍
传统心音分类算法需要人工设定特征提取算子,这类方法一般缺乏模型普适性,且在非线性数据特征提取具有一定的局限性。近年来,学者提出通过一些变换,如短时傅里变换、小波变换等,将原始心音信号转化为二维心音时频图,在频域训练深度卷积网络进行分类。
最近,在深度学习中Transformer与多层感知机(Multi-Layer Perceptron, MLP)技术引起了广大研究者的关注,受到这些研究的启发,我们设计了一种卷积(Convolution, Conv)与MLP混合的轻量化模型。
传统卷积神经网络通过卷积核的局部权值共享,拥有自动提取数据局部信息的能力,但是对全局信息的获取较差。从心音数据的二阶谱特征图分析看出,心音信号除了存在一定的局部显著性特点,全局分布特性对心音分类依然至关重要。
在最近的研究中,一般通过自注意力(self-attention)机制对数据进行特征提取得到注意力图,这样可以得出不同局部信息在整个图像中的重要性。因此,本项目在在训练模型的构建部分,巧妙地利用MLP算法、全局池化(Gloval Average Pooling, GAP)以及Conv技术替代self-attention,设计了一种混合模型。
如图所示,网络按照感知能力大小将网络划分为三个部分,即全局感知(Global Perceptron, GP),区域感知(Partition Perceptron, PP),局部感知(Local Perceptron, LP)。
首先,模型的输入为心音信号的二阶谱特征图(具体参考后续数据处理部分),并且网络在初始输入中将特征图划分为若干个相等大小的块。PP部分正是在各划分块分别独立进行感知编码,即针对区域进行特征图的全局感知。
由于等分划分导致图像块与块之间的关系丢失,导致MLP对整张图像的感受能力丢失,即每个块的重要性丢失。所以模型设计了GP模块,该模块首先对图像进行GAP,即每个块被池化为一个像素点,然后再对特征进行重构送入MLP层,最终得到一个关于全局感知的向量,将其与PP特征融合,这样可弥补PP部分全局信息丢失的缺陷。
由于一般的MLP对局部信息的感知能力较弱,因此,模型进一步设计了LP模块,且在该部分使用一个Conv与批归一化(Batch Normalization, BN)构成的多个平行模块,每个平行模块通过分别使用不同卷积核大小的Conv提取多尺度局部信息,然后再将所有局部特征与PP部分特征融合。
这样做的目的是将局部先验信息(因为Conv可以学习局部先验)加入到后续特征中,并且加速MLP层收敛。通过上述操作,最终模型具备了GP、PP、LP三个不同层次的信号感知能力。
使用Paddle框架搭建模型
使用Sequential形式组网使用paddle.static将动态图转静态图,这样才可以调用paddle.jit.save()函数存储模型,这点很重要!!!刚开始模型一直转换不成功而找不到原因,最后才发现是这个问题。 具体介绍可以看官方文档模型的保存与载入使用paddle.summary模型结构可视化
注意 :在模型的搭建的过程中发现一些Paddle的问题,当输入的特征图为单通道时,使用Sequential方法组网时,BatchNorm操作不能和其他操作一起使用。否则训练过程中就会出现反向梯度传播中断的情况,要将BatchNorm操作拿出来单独定义才可进行训练。
网络实现的具体代码如下所示:
In [15]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.vision.transforms import ToTensorimport numpy as npimport matplotlib.pyplot as pltimport copyfrom paddle.static import InputSpecclass RepMLP(nn.Layer): def __init__(self, in_channels, out_channels, H, W, h, w, reparam_conv_k=None, fc1_fc2_reduction=1, fc3_groups=1, classes = 2, deploy=False,): super(RepMLP, self).__init__() self.C = in_channels self.O = out_channels self.fc3_groups = fc3_groups self.H, self.W, self.h, self.w = H, W, h, w self.h_parts = self.H // self.h self.w_parts = self.W // self.w assert self.H % self.h == 0 assert self.W % self.w == 0 self.target_shape = [-1, self.O, self.H, self.W] self.deploy = deploy self.classes = classes self.need_global_perceptron = (H != h) or (W != w) if self.need_global_perceptron: internal_neurons = int(self.C * self.h_parts * self.w_parts // fc1_fc2_reduction) self.fc1_fc2 = nn.Sequential( ('fc1', nn.Linear(self.C * self.h_parts * self.w_parts, internal_neurons)), ('relu', nn.ReLU()), ('fc2', nn.Linear(internal_neurons, self.C * self.h_parts * self.w_parts)) ) if deploy: self.avg = nn.AvgPool2d(kernel_size=(self.h, self.w)) else: self.avg = nn.Sequential( ('avg', nn.AvgPool2D(kernel_size=(self.h, self.w))), # ('bn', nn.BatchNorm2D(self.C)) ) self.avg_bn = nn.BatchNorm2D(self.C) self.fc3 = nn.Conv2D(self.C * self.h * self.w, self.O * self.h * self.w, 1, 1, 0, bias_attr=deploy, groups=fc3_groups) self.fc3_bn = nn.Identity() if deploy else nn.BatchNorm1D(num_features = self.O * self.h * self.w) self.reparam_conv_k = reparam_conv_k if not deploy and reparam_conv_k is not None: for k in reparam_conv_k: conv_branch = nn.Sequential( ('conv', nn.Conv2D(in_channels=self.C, out_channels=self.O, kernel_size=k, padding=k // 2, bias_attr=False, groups=fc3_groups)) #, ('bn', nn.BatchNorm(self.O)) ) conv_branch_bn = nn.Sequential( ('bn', nn.BatchNorm(self.O)) ) self.__setattr__('repconv{}'.format(k), conv_branch) self.__setattr__('repconv_bn{}'.format(k), conv_branch_bn) self.end_avg = nn.AvgPool2D(kernel_size=(self.h, self.w)) self.fc4 = nn.Linear(self.h_parts*self.w_parts*self.O, self.classes) @paddle.jit.to_static(input_spec=[InputSpec(shape=[None, 1, 256, 256], dtype='float32')]) def forward(self, inputs): if self.need_global_perceptron: v = self.avg(inputs) v = paddle.reshape(v, [-1, self.C * self.h_parts * self.w_parts]) v = self.fc1_fc2(v) v = paddle.reshape(v, [-1, self.C, self.h_parts, 1, self.w_parts, 1]) inputs = paddle.reshape(inputs, [-1, self.C, self.h_parts, self.h, self.w_parts, self.w]) inputs = inputs + v else: inputs = paddle.reshape(inputs, [-1, self.C, self.h_parts, self.h, self.w_parts, self.w]) partitions = paddle.transpose(inputs, perm=[0, 2, 4, 1, 3, 5]) # Feed partition map into Partition Perceptron fc3_inputs = paddle.reshape(partitions, [-1, self.C * self.h * self.w, 1, 1]) fc3_out = self.fc3(fc3_inputs) fc3_out = paddle.reshape(fc3_out, [-1, self.O * self.h * self.w]) fc3_out = self.fc3_bn(fc3_out) fc3_out = paddle.reshape(fc3_out, [-1, self.h_parts, self.w_parts, self.O, self.h, self.w]) # Feed partition map into Local Perceptron if self.reparam_conv_k is not None and not self.deploy: conv_inputs = paddle.reshape(partitions, [-1, self.C, self.h, self.w]) conv_out = 0 for k in self.reparam_conv_k: conv_branch = self.__getattr__('repconv{}'.format(k)) conv_branch_bn = self.__getattr__('repconv_bn{}'.format(k)) conv_out += conv_branch_bn(conv_branch(conv_inputs)) conv_out = paddle.reshape(conv_out, [-1, self.h_parts, self.w_parts, self.O, self.h, self.w]) fc3_out += conv_out fc3_out = paddle.transpose(fc3_out, perm=[0, 3, 1, 4, 2, 5]) # N, O, h_parts, out_h, w_parts, out_w fc3_out = paddle.reshape(fc3_out, self.target_shape) out = self.end_avg(fc3_out) out = paddle.reshape(out, [-1, self.h_parts*self.w_parts*self.O]) out = self.fc4(out) return outif __name__ == '__main__': N = 1 C = 1 H = 256 W = 256 h = 32 w = 32 O = 1 groups = 1 net = RepMLP(C, O, H=H, W=W, h=h, w=w, reparam_conv_k=(1,3,5), fc1_fc2_reduction=1, fc3_groups=groups, classes = 4, deploy=False) net.eval() params_info = paddle.summary(net, (1, 1, 256, 256), ['float32']) print(params_info)
1.3 训练&保存模型(使用基础API)
配置optimizer优化器:paddle.optimizer.Adam()配置loss损失函数:paddle.nn.CrossEntropyLoss()配置accuracy精度计算:paddle.metric.accuracy()使用paddle.jit.save()保存动/静态模型配置GPU训练(Paddle2.0可自动根据环境使用GPU,此步骤可省略)
具体代码请见train.py
【代码】
def train(train_loader, valid_loader, model, optim, loss, epoch_num, use_gpu): print('start training ... ') paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu') val_loss_history = [] val_acc_history = [] for epoch in range(epoch_num): model.train() for batch_id, (data, label) in enumerate(train_loader()): x_data = paddle.to_tensor(data) y_data = paddle.to_tensor(label) y_data = paddle.unsqueeze(y_data, 1) logits = model(x_data) # print('logits:', logits.shape) # print('y_data:', y_data.shape) # pred = paddle.argmax(logits) loss = F.cross_entropy(logits, y_data) if (batch_id+1) % 10 == 0: print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy())) optim.clear_grad() loss.backward() optim.step() # evaluate model after one epoch model.eval() accuracies = [] losses = [] for batch_id, (data, label) in enumerate(valid_loader()): x_data = paddle.to_tensor(data) y_data = paddle.to_tensor(label) y_data = paddle.unsqueeze(y_data, 1) logits = model(x_data) loss = F.cross_entropy(logits, y_data) acc = paddle.metric.accuracy(logits, y_data) accuracies.append(acc.numpy()) losses.append(loss.numpy()) avg_acc, avg_loss = np.mean(accuracies), np.mean(losses) print("[validation] accuracy/loss: {}/{}".format(avg_acc, avg_loss)) val_acc_history.append(avg_acc) val_loss_history.append(avg_loss) path = "./model_weights/model_2" paddle.jit.save( layer=model, path=path) return val_acc_history, val_loss_history
训练完成后会产生*.pdmodel,*.pdiparams后缀的文件,分别保存模型信息和参数。
2 模型部署
硬件上的软件环境准备(树莓派Raspberry Pi OS操作系统)编译Paddle-Lite基于Python API转换Paddle模型实现预测效果
2.1 环境准备
前面提到Paddle-Lite不能在Ubuntu系统下进行编译,所以这里一定要注意自己当前系统版本和位数。如果你已经安装好了系统,可使用以下命令查看系统信息。
输入命令:uname -a
输出结果:Linux raspberrypi 5.10.17-v7l+ #1421 SMP Thu May 27 14:00:13 BST 2021 armv7l GNU/Linux
输入命令:getconf LONG_BIT
输出结果:32
镜像烧录
如果未安装系统,请按照以下步骤进行系统镜像烧录。
首先我们需要在树莓派官网下载最新版的桌面系统(官方桌面系统),官方网站通常下载速度较慢,这里我推荐使用国内的镜像网站,我下载的是目前最新的桌面版本点击下载。
TUNA 镜像站(位于北京):https://mirrors.tuna.tsinghua.edu.cn/raspberry-pi-os-images/
SJTUG 镜像站(位于上海):https://mirrors.sjtug.sjtu.edu.cn/raspberry-pi-os-images/
在下载好镜像文件后,需要将其烧录到SD卡上,这时我们可以使用树莓派官方提供的镜像烧录软件点击下载,选择与自己当前正在使用的系统匹配的软件版本下载,具体使用界面如下。 开启SSH连接。由于树莓派连接键鼠操作不方便,一般都采用SSH远程连接,树莓派镜像在烧录好了后是默认不开启SSH服务的。这时我们不着急插入SD卡开机,在刚刚SD的根目录新建一个空名为ssh的文件 。如果你是采用Wi-Fi连接网络,那么还需要配置相关文件。仍然是在根目录下新建wpa_supplicant.conf文件,然后在文件中写入一下内容
开启SSH连接。由于树莓派连接键鼠操作不方便,一般都采用SSH远程连接,树莓派镜像在烧录好了后是默认不开启SSH服务的。这时我们不着急插入SD卡开机,在刚刚SD的根目录新建一个空名为ssh的文件 。如果你是采用Wi-Fi连接网络,那么还需要配置相关文件。仍然是在根目录下新建wpa_supplicant.conf文件,然后在文件中写入一下内容
country=CNctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdevupdate_config=1 network={ssid="WIFI Name" # WIFI名称psk="*********" # WIFI密码key_mgmt=WPA-PSKpriority=1}
在做好上述准备后,就可以开启远程连接了,树莓通常默认的账号:pi 密码:raspberry。但是连接之前需要知道树莓派IP地址,网上找了很多方法都觉得很麻烦,最后发现树莓派官方提供了方法,使用ssh pi@raspberrypi.local就可以连接到同一局域网下的树莓派了。
Paddle-Lite相关编译库准备
首先更新一下系统的软件列表
sudo apt-get update
sudo apt-get upgrade
安装相关依赖
sudo apt-get install -y gcc g++ make wget python unzip patchelf python-dev -y的作用是对后续的操作都选择yes
下载CMake并安装
下载:wget https://cmake.org/files/v3.20/cmake-3.20.0-rc4.tar.gz
解压:tar -zxvf cmake-3.20.0-rc4.tar.gz
启用配置文件:cd cmake-3.20.0-rc4 && ./configure,某些版本的系统这一步可能回缺少一些依赖,比如OpenSSL包可以使用sudo apt-get install libssl-dev命令安装。
编译cmake:make
安装cmake:sudo make install
验证安装:cmake –version ,如果输出cmake version 3.20.0-rc4 CMake suite maintained and supported by Kitware (kitware.com/cmake).则表明安装成功了。
Paddle-Lite源码编译
由于PaddlePaddle是不支持ARM架构CPU的,所以我们在树莓派上只可以安装Paddle-Lite。同时我们可以从其官网了解到,树莓派安装Paddle-Lite只可以使用本地源码编译的方式。除了下载源码并编译之外,我们也可以直接下载编译好的whl包并安装即可。(但是编译好的whl包要和自己的硬件和系统版本相适配才可以安装),具体说明可以参考Paddle-Lite官方文档。
首先从GitHub下载Paddle-Lite源码,由于GitHub在国内访问比较慢,这里也可以使用Gitee下载,下面提供了两种下载方式,本文使用的是GitHub下载。
Gitee下载:git clone https://github.com/PaddlePaddle/Paddle-Lite.git
GitHub下载:git clone https://gitee.com/paddlepaddle/paddle-lite.git
源码下载完成后切换到分支v2.8
cd Paddle-Lite && git checkout release/v2.8
将其中的third-party目录删除,这将使得编译脚本自动从国内CDN下载第三方库文件
rm -rf third-party
编译Paddle-Lite库
在编译之前选择将默认4线程编译切换成单线程编译,更加稳定。
export LITE_BUILD_THREADS=1
使用源码中自带的shell脚本进行编译,脚本有多种参数可以选择
--arch: (armv8|armv7|armv7hf) arm版本,默认为armv8--toolchain: (gcc|clang) 编译器类型,默认为gcc--with_extra: (OFF|ON) 是否编译OCR/NLP模型相关kernel&OP,默认为OFF,只编译CV模型相关kernel&OP--with_python: (OFF|ON) 是否编译python预测库, 默认为 OFF--python_version: (2.7|3.5|3.7) 编译whl的Python版本,默认为 None--with_cv: (OFF|ON) 是否编译CV相关预处理库, 默认为 OFF--with_log: (OFF|ON) 是否输出日志信息, 默认为 ON--with_exception: (OFF|ON) 是否在错误发生时抛出异常,默认为 OFF
这里我们只选择–arch,–with_python,–python_version三个参数,其中–python_version需要根据自己python版本确定(这里我版本是3.7)。使用下面的命令就可以进行Paddle-Lite的源码编译了,编译过程有些长,可能会持续半个小时左右。
./lite/tools/build_linux.sh –arch=armv7hf –with_python=ON –python_version=3.7
安装Paddle-Lite
编译成功后会生成一个build.lite.linux.armv7hf.gcc文件夹,文件夹下有inference_lite_lib.armlinux.armv7hf的文件夹,里面有Python的的文件paddlelite-51fcbb609-cp37-cp37m-linux_armv7l.whl。
使用pip install paddlelite-51fcbb609-cp37-cp37m-linux_armv7l.whl
【文件结构】
inference_lite_lib.armlinux.armv7hf├── cxx C++ 预测库和头文件│ ├── include C++ 头文件│ │ ├── paddle_api.h│ │ ├── paddle_image_preprocess.h│ │ ├── paddle_lite_factory_helper.h│ │ ├── paddle_place.h│ │ ├── paddle_use_kernels.h│ │ ├── paddle_use_ops.h│ │ └── paddle_use_passes.h│ └── lib C++ 预测库│ ├── libpaddle_api_light_bundled.a C++ 静态库│ └── libpaddle_light_api_shared.so C++ 动态库├── demo│ └── python Python 预测库demo│└── python Python 预测库(需要打开with_python选项) ├── install │ └── dist Python whl包 │ └── paddlelite-51fcbb609-cp37-cp37m-linux_armv7l.whl └── lib └── lite.so Python 预测库
安装完成后,可以尝试导入包验证一下,若没有报错则证明安装成功。
使用opt工具转换模型
Paddle的原生模型需要经过opt工具转化为Paddle-Lite可以支持的naive_buffer格式,Linux X86_CPU 平台和MAC X86_CPU 平台可以直接使用paddle_lite_opt命令工具转换模型,具体详见官方文档。
但是树莓派是ARMLinux 平台只能编写python脚本转换模型,代码如下:
【代码】
import paddlelite.lite as litea=lite.Opt()# 非combined形式a.set_model_dir("Your model file path")# conmbined形式,具体模型和参数名称,请根据实际修改# a.set_model_file("Your model file path")# a.set_param_file("Your param file path")a.set_optimize_out("model") # 设置模型文件名a.set_valid_places("arm") # 设置为arma.run()
代码执行成功后会产生.nb后缀的naive_buffer格式文件。
通过调用*.nb文件实现预测效果
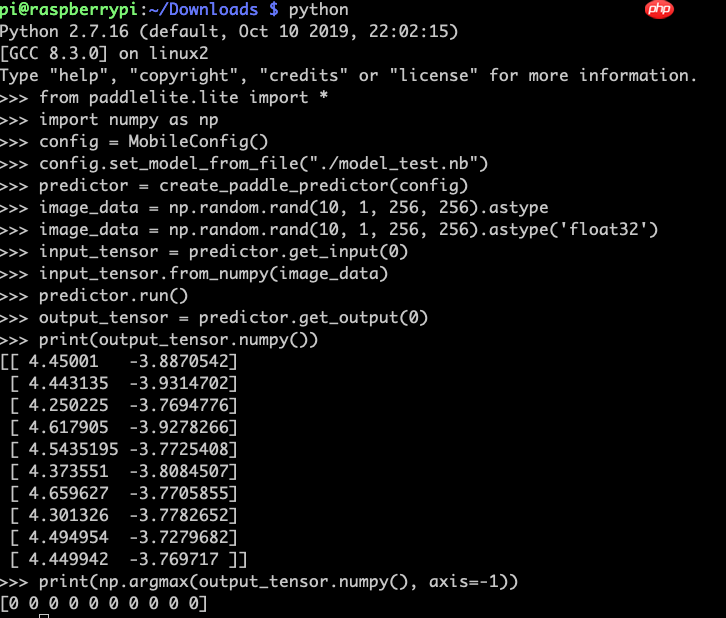
Python代码调用Paddle-Lite执行预测库仅需以下六步:
(1) 设置config信息
from paddlelite.lite import *import numpy as npconfig = MobileConfig()config.set_model_from_file("./model.nb") # 这里使用自己的*.nb文件路径
(2) 创建predictor
predictor = create_paddle_predictor(config)
(3) 从图片读入数据
image_data = np.random.rand(10, 1, 256, 256) # 这里我们先使用一组随机样本测试一下,这里可以替换成自己的读取数据代码。
(4) 设置输入数据
input_tensor = predictor.get_input(0)input_tensor.from_numpy(image_data)
(5) 执行预测
predictor.run()
(6) 得到输出数据
output_tensor = predictor.get_output(0)print(output_tensor.numpy())print(np.argmax(output_tensor.numpy(), axis=-1))
具体执行效果如下所示:
Paddle-Lite部署实战
LCD显示屏相关设置
考虑到设备的便携性,我们使用了一块1.3寸的LCD屏幕,屏幕相关参数如下所示

功能参数
工作电压: 3.3V通信接口: SPI屏幕类型: IPS控制芯片: ST7789VM分辨率: 240(H)RGB x 240(V)显示尺寸: 23.4(H)x 23.4(V)mm像素大小: 0.0975(H)x 0.0975(V)mm产品尺寸: 65 x 30.2(mm)
功能引脚
KEY1P21按键1GPIOKEY2P20按键2GPIOKEY3P16按键3GPIO摇杆UPP6摇杆上摇杆DownP19摇杆下摇杆LeftP5摇杆左摇杆RightP26摇杆右摇杆PressP13摇杆按下SCLKP11/SCLKSPI时钟线MOSIP10/MOSISPI数据线CSP8/CE0片选DCP25数据/命令选择RSTP27复位BLP24背光
开启SPI接口
打开树莓派终端,输入以下指令进入配置界面
sudo raspi-config选择Interfacing Options -> SPI -> Yes开启SPI接口
然后重启树莓派
sudo reboot
安装相关库
安装BCM2835,并运行以下指令
wget http://www.airspayce.com/mikem/bcm2835/bcm2835-1.60.tar.gztar zxvf bcm2835-1.60.tar.gzcd bcm2835-1.60/sudo ./configure && sudo make && sudo make check && sudo make install更多的可以参考官网:http://www.airspayce.com/mikem/bcm2835/
安装wiringPi
sudo apt-get install wiringpi,对于树莓派2019年5月之后的系统(早于之前的可不用执行),可能需要进行升级:wget https://project-downloads.drogon.net/wiringpi-latest.debsudo dpkg -i wiringpi-latest.debgpio -v运行gpio -v会出现2.52版本,如果没有出现说明安装出错
安装Python相关库
sudo apt-get updatesudo apt-get install ttf-wqy-zenheisudo apt-get install python-pipsudo pip install RPi.GPIOsudo pip install spidev
其它
对于树莓派4B及raspbian_lite-2019-06-20系统之后需要设置如下,按键才能正常输入
sudo nano /boot/config.txt
#添加如下:
gpio=6,19,5,26,13,21,20,16=pu
使用LCD功能引脚控制程序并显示输出结果
使用python API控制引脚输出
将模型部署到树莓派中的步骤具体如下:
对于树莓派的功能引脚及显示屏的设置可以参考官方文档:树莓派1.3寸显示屏使用教程
(1)配置引脚的输入输出
RST_PIN = 25CS_PIN = 8DC_PIN = 24KEY_UP_PIN = 6KEY_DOWN_PIN = 19KEY_LEFT_PIN = 5KEY_RIGHT_PIN = 26KEY_PRESS_PIN = 13KEY1_PIN = 21KEY2_PIN = 20KEY3_PIN = 16# 设置树莓派输入输出GPIO.setmode(GPIO.BCM)GPIO.setup(KEY_UP_PIN, GPIO.IN, pull_up_down=GPIO.PUD_UP)GPIO.setup(KEY_DOWN_PIN, GPIO.IN, pull_up_down=GPIO.PUD_UP)GPIO.setup(KEY_LEFT_PIN, GPIO.IN, pull_up_down=GPIO.PUD_UP)GPIO.setup(KEY_RIGHT_PIN, GPIO.IN, pull_up_down=GPIO.PUD_UP)GPIO.setup(KEY_PRESS_PIN, GPIO.IN, pull_up_down=GPIO.PUD_UP)GPIO.setup(KEY1_PIN, GPIO.IN, pull_up_down=GPIO.PUD_UP)GPIO.setup(KEY2_PIN, GPIO.IN, pull_up_down=GPIO.PUD_UP)GPIO.setup(KEY3_PIN, GPIO.IN, pull_up_down=GPIO.PUD_UP)
(2)导入显示图片
im_init = Image.open('./tupian/init.png')show_image(im_init)im_AS = Image.open('./tupian/AS.png')im_MR = Image.open('./tupian/MR.png')im_MS = Image.open('./tupian/MS.png')im_MVP = Image.open('./tupian/MVP.png')im_wait = Image.open('./tupian/wait.png')im_taking = Image.open('./tupian/taking.png')im_normal = Image.open('./tupian/normal.png')im_abnormal = Image.open('./tupian/abnormal.png')im_welcome = Image.open('./tupian/welcome.png')im_testing = Image.open('./tupian/testing.png')
(3)图片展示函数
# Raspberry Pi pin configuration:RST = 27DC = 25BL = 24bus = 0device = 0# 240x240 display with hardware SPI:disp = ST7789.ST7789(SPI.SpiDev(bus, device),RST, DC, BL)# Initialize library.disp.Init()# Clear display.disp.clear()# 展示图片def show_image(photo,t=3.0): disp.ShowImage(photo,0,0) time.sleep(t)
(4)导入模型文件并设置按键功能
声音录制功能设置
if not GPIO.input(KEY1_PIN) : show_image(im_taking,10) os.system('arecord --format S32_LE --rate 2000 -c 2 -d 10 ./sounds/test.wav') audio_path = './sounds/test.wav' show_image(im_wait,1) audio_data, fs = sf.read(audio_path) audio_data = band_pass_filter(audio_data, 2, 25, 400, fs) down_sample_audio_data = samplerate.resample( audio_data.T, 1000 / fs, converter_type='sinc_best').T down_sample_audio_data = down_sample_audio_data / np.max(np.abs(down_sample_audio_data)) plot_signal(down_sample_audio_data, title=audio_path) im = Image.open('./hs_data/hs_img.jpg') # show_image(im)freq1, fre2, bi_spectrum = polycoherence( down_sample_audio_data[-2500:], nfft=1024, fs=1000, norm=None, nperseg=256) bi_spectrum = np.array(abs(bi_spectrum)) # calculate bi_spectrum bi_spectrum = bi_spectrum.reshape((1, 256, 256)) bi_spectrum = 255 * (bi_spectrum - np.min(bi_spectrum)) / (np.max(bi_spectrum) - np.min(bi_spectrum)) dataset = np.array([bi_spectrum]) # dataset = np.delete(dataset, 0, 0) dataset = dataset.astype('float32')
运行结果如下:

 二分类功能设置
二分类功能设置
elif not GPIO.input(KEY2_PIN) : show_image(im_testing) config=MobileConfig() config.set_model_from_file("./model_2.nb") predictor=create_paddle_predictor(config) image_data=dataset input_tensor = predictor.get_input(0) input_tensor.from_numpy(image_data) predictor.run() output_tensor = predictor.get_output(0) print(output_tensor.numpy()) print(np.argmax(output_tensor.numpy(),axis=-1)[0]) if np.argmax(output_tensor.numpy(),axis=-1)[0] == 0: show_image(im_normal) else: show_image(im_abnormal)
运行结果如下:
 四分类功能设置
四分类功能设置
elif not GPIO.input(KEY3_PIN): config = MobileConfig() config.set_model_from_file("./model_4.nb") predictor = create_paddle_predictor(config) image_data = dataset input_tensor = predictor.get_input(0) input_tensor.from_numpy(image_data) predictor.run() output_tensor = predictor.get_output(0) print(output_tensor.numpy()) print(np.argmax(output_tensor.numpy(), axis=-1)) if np.argmax(output_tensor.numpy(),axis=-1)[0] == 0: show_image(im_AS) elif np.argmax(output_tensor.numpy(),axis=-1)[0] == 1: show_image(im_MS) elif np.argmax(output_tensor.numpy(),axis=-1)[0] == 2: show_image(im_MVP) elif np.argmax(output_tensor.numpy(),axis=-1)[0] == 3: show_image(im_MR)
运行结果如下:
 展示主页面
展示主页面
else: show_image(im_welcome,0.1)
运行结果如下:

以上就是心音智能检测的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/59339.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























