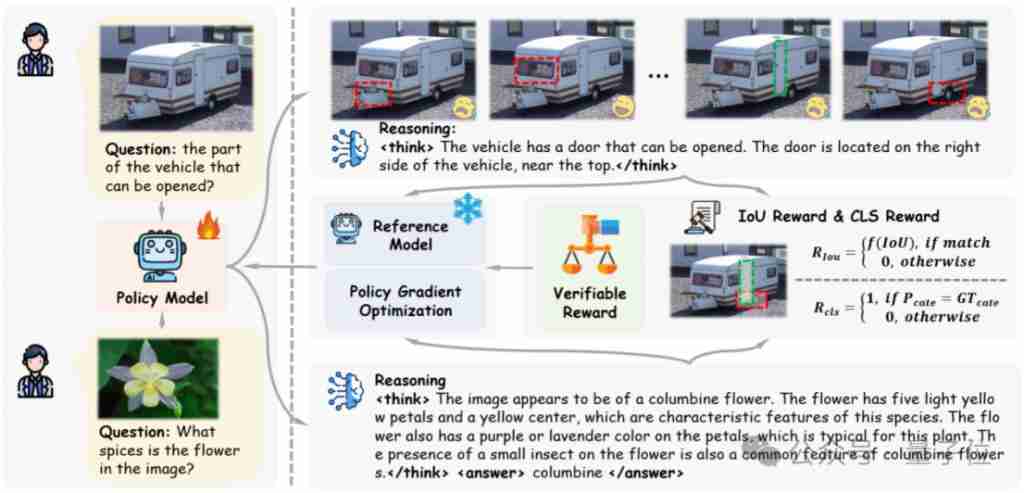
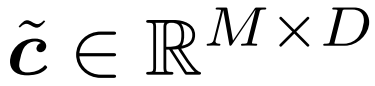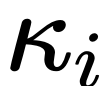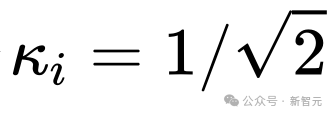大模型竞赛,又杀出一匹黑马——
Inflection-2.5,由DeepMind联创Mustafa Suleyman的大模型初创公司打造。
只用40%的计算资源训练,表现就超过了GPT-4的九成,尤其擅长代码和数学。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
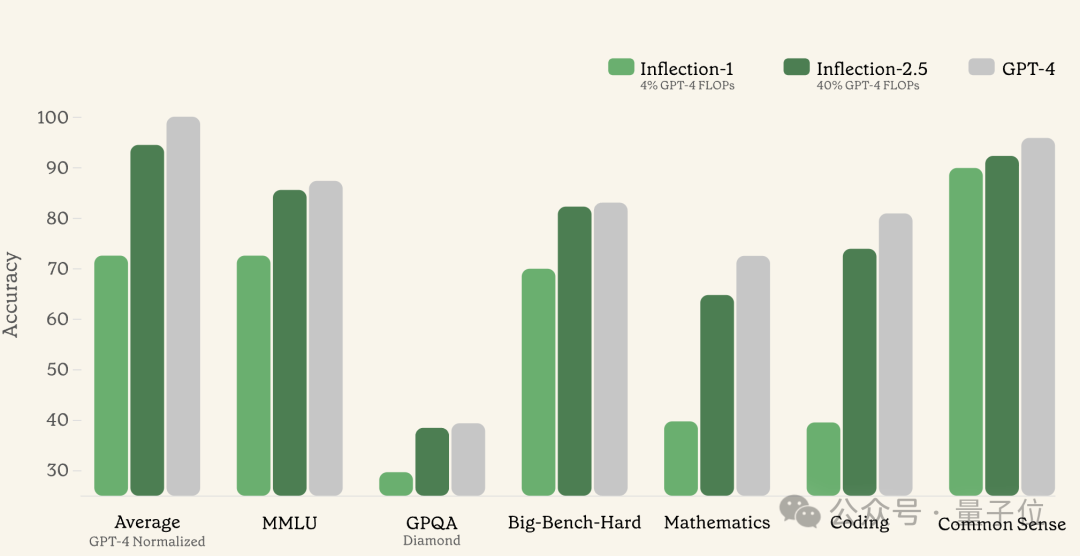
而早期的Inflection模型,训练时只消耗了4%的计算资源,就达到了GPT-4表现的72%。
以Inflection模型为基础,该公司还推出了网页端对话机器人Pi,主打“高情商”和“个性化”,还支持中文。
自诞生以来,Pi的最高日活达到了100万,累计产生了40亿条消息,平均对话时长来到了33分钟。
而随着这次基础模型的升级,Pi也迎来了它的新版本。
 图片
图片
那么,Inflection,或者说Pi,表现到底有没有那么强,量子位进行了一番实测。
无需登录即可使用
打开Pi的页面,映入眼帘的是这样一个极简界面,而且还可以不用登录,直接点击Next。
 图片
图片
连续Next几次后,输入希望Pi称呼我们的方式。
 图片
图片
之后是选择声音和推荐话题,直接跳过就可以了,然后就进入正式的聊天界面了。
 图片
图片
简单测试发现,Pi支持中文对话,既然如此那就先把弱智吧Benchmark给安排上。
第一题,老鼠生病了可以吃老鼠药治好吗,Pi成功解答。
 图片
图片
再来一道“陷阱”题,这次依旧没有上当。
 图片
图片
两道问题过后,虽然没有出现什么戏剧性效果,但看起来对中文也是有一定的理解了。
接下来就重点看看官方宣称“尤其擅长”的数学和代码能力。
首先是一道涉及动态规划的编程题目。
 图片
图片
Pi给出的代码成功解决了这个问题,并且配有清晰的解释。
 图片
图片
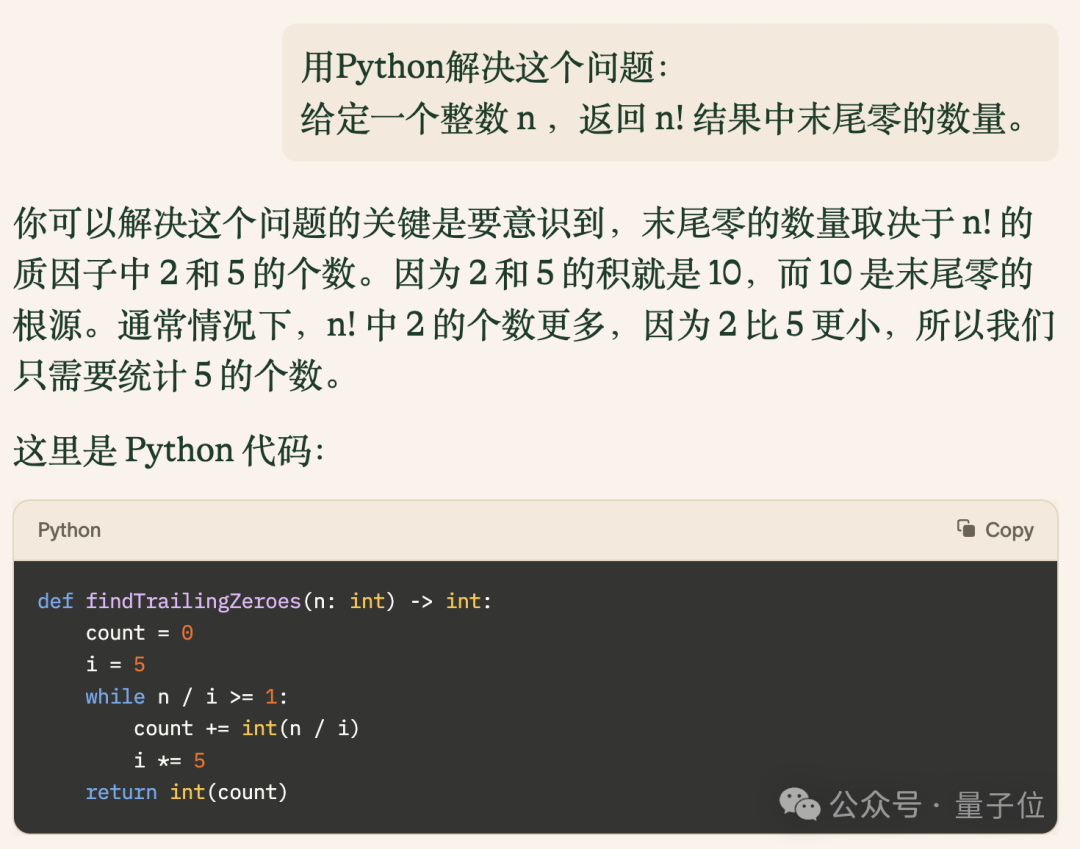
接下来再提升一下难度看看,让其分析一个数字的阶乘中末尾有多少个0。
 图片
图片
Pi给出的代码不仅正确,而且简洁高效,运行速度超过了LeetCode上73.8%的用户。
 图片
图片
最后再来增加一下难度,以一道47.5%通过率的题目结束代码部分的测试。
 银河易创
银河易创
一站式AIGC创作平台,集成GPT-3.5、GPT-4、文心一言等对话模型、Midjourney、DallE等绘画工具、AI音乐、AI视频和AI PPT等功能!
 52 查看详情
52 查看详情 
 图片
图片
看完代码,再来测测Pi的数学能力怎么样,让它做做关于导数的题目:
求出函数f(x)=x³+2x²-1的极值点
解答完全正确,而是十分详细。
当然要想数学好,逻辑思维是必不可少的,所以我们在常规的数学题之外,又用一道经典的题目考验了一下的Pi逻辑思维,结果还不错。
通过Pi的表现,可以看出其背后的Inflection-2.5模型的确可圈可点。
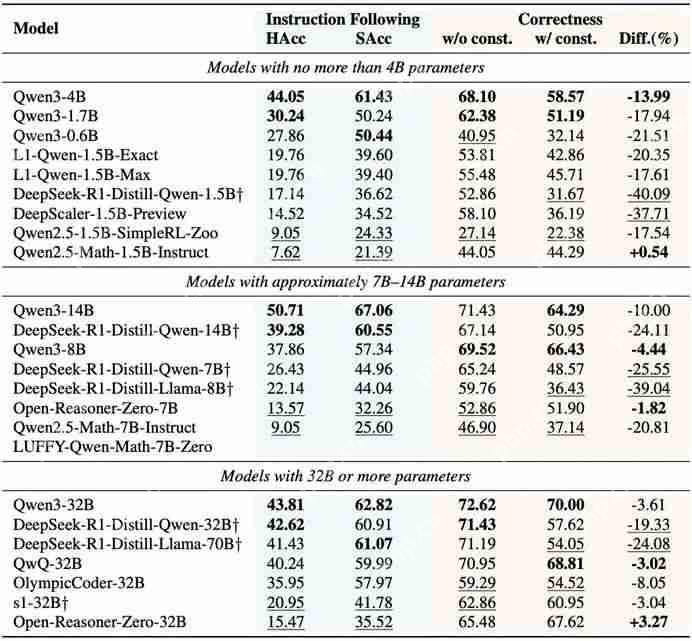
而从官方自己公布的测试数据来看,无论是综合能力还是各个子项,Inflection-2.5的表现都紧随GPT-4。
以数学和代码为例,Inflection-2.5在MATH、HumanEval等测试中都比1.0版本都有大幅飞跃。
在这些常规的数据集之外,Inflection还挑战了匈牙利高考数学试题和GRE物理测试,结果几乎与GPT-4打成平手。
更“刁钻”的,还有人专门用大模型难以理解的问题构建了一个BIG-Bench数据集,而Inflection-2.5挑战了其中的Hard子集,结果和GPT-4的差距不到一分。
那么,Inflection-2.5的背后,是怎样的一家公司呢?
DeepMind联创大模型创业
这家公司名叫Inflection AI,由DeepMind联创Mustafa Suleyman等人于2022年创立,目前共有70余人。
同样来自DeepMind的,还有资深研究员Karen Simonyan,现担任Inflection AI的首席科学家。
此外,LinkedIn联创Reid Hoffman也参与了Inflection AI的创立。
创立以来,Inflection AI已经获得了来自英伟达、微软、比尔盖茨等巨头的共计15亿美元的融资。
目前,基于Inflection的Pi还是免费的,但CEO Suleyman也表示,一直用爱发电不现实,长久地看以后还是要收费。
想要体验的朋友,可能要抓紧时间了~
传送门:https://pi.ai
以上就是40%算力训练效果比肩GPT-4,实测DeepMind联创大模型创业新成果的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/619932.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫