
各家大模型纷纷卷起上下文窗口,llama-1时标配还是2k,现在不超过100k的已经不好意思出门了。
然鹅一项极限测试却发现,大部分人用法都不对,没发挥出AI应有的实力。
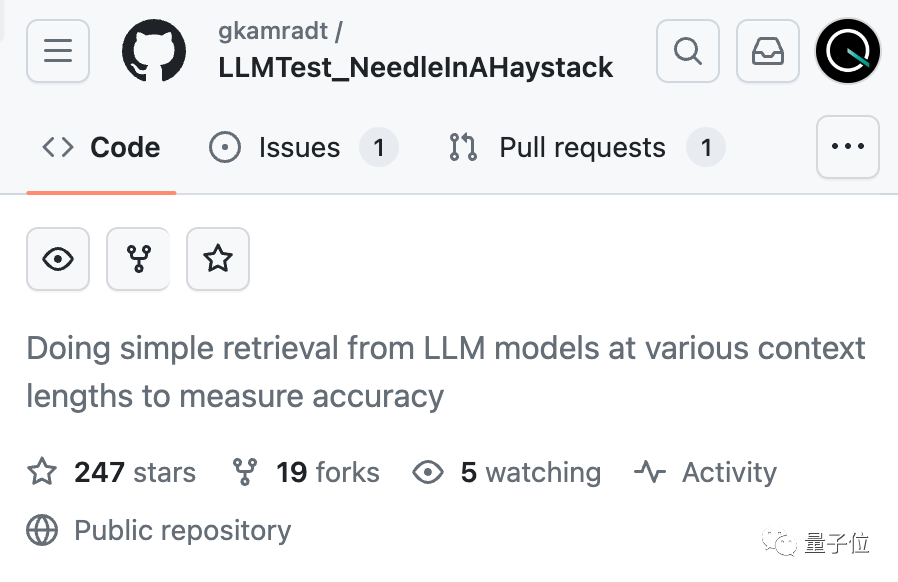
AI真的能从几十万字中准确找到关键事实吗?颜色越红代表AI犯的错越多。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
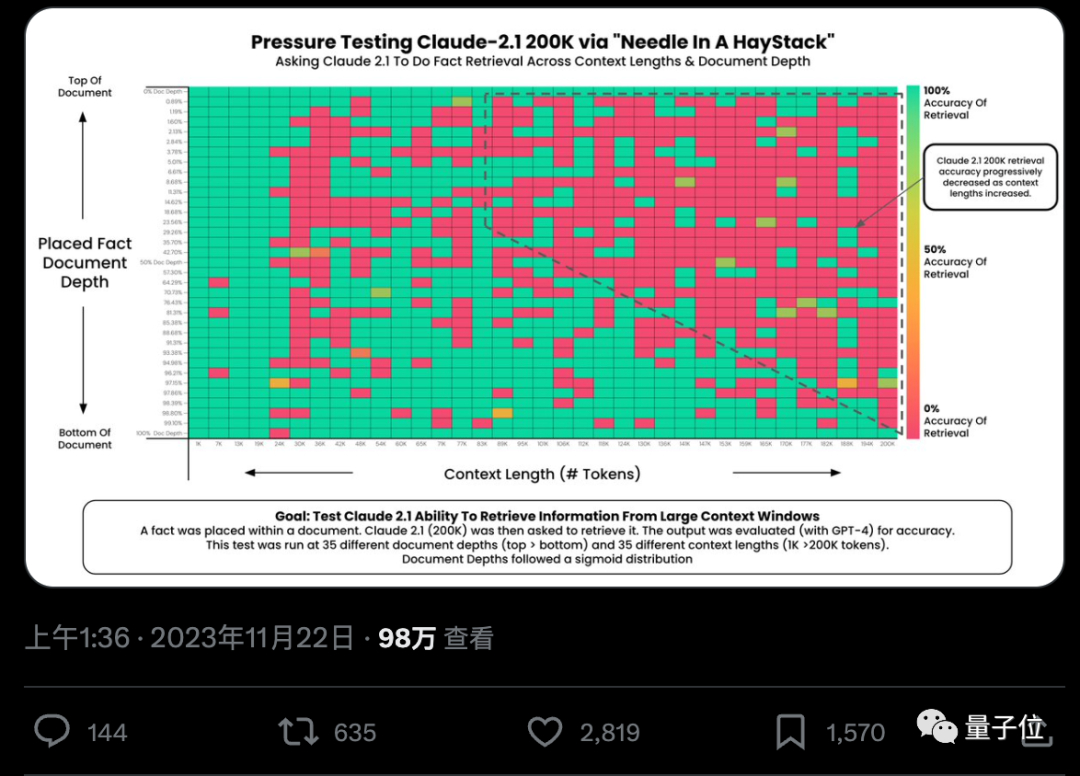
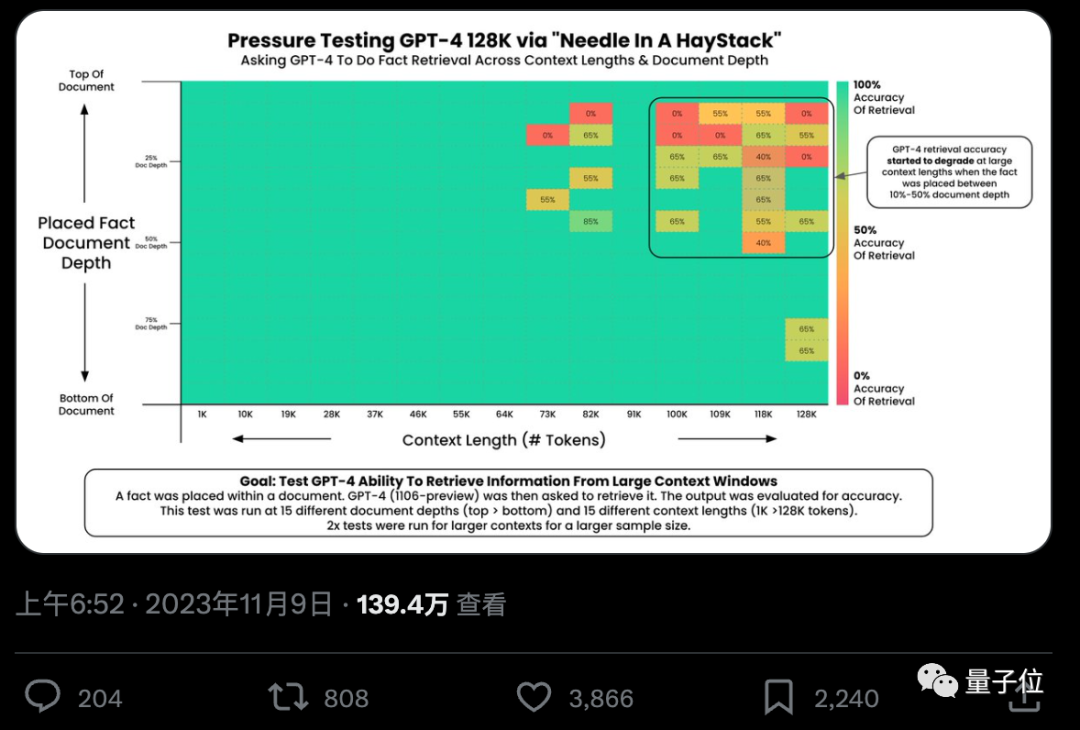
默认情况下,GPT-4-128k和最新发布的Claude2.1-200k成绩都不太理想。
但Claude团队了解情况后,给出超简单解决办法,增加一句话,直接把成绩从27%提升到98%。
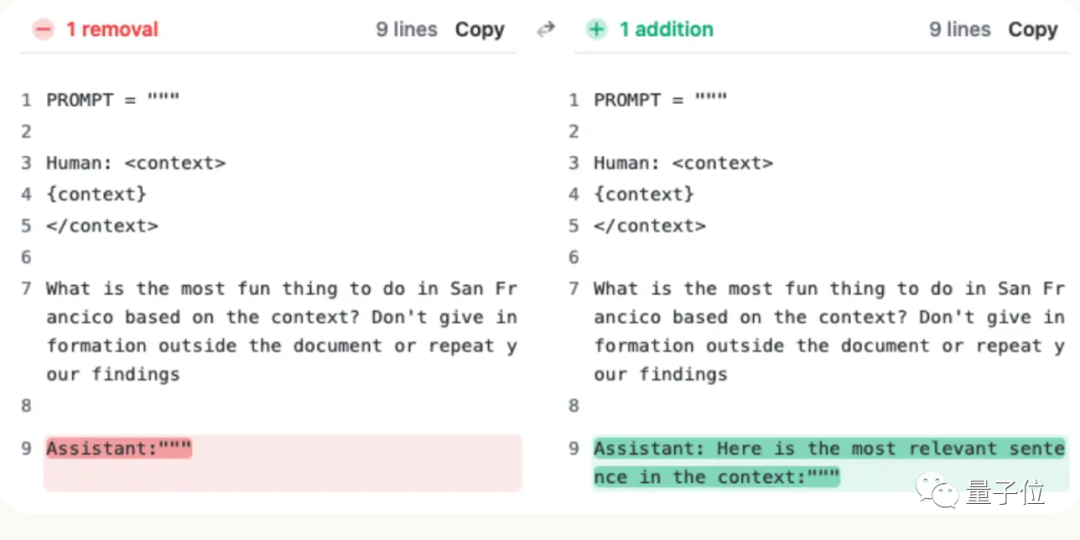
只不过这句话不是加在用户提问上的,而是让AI在回复的开头先说:
“Here is the most relevant sentence in the context:”
(这就是上下文中最相关的句子:)
让大模型大海捞针
为了做这项测试,作者Greg Kamradt自掏腰包花费了至少150美元。
在测试Claude2.1时,Anthropic提供了免费额度给他,幸好这样他就不用花费额外的1016美元了
其实测试方法也不复杂,都是选用YC创始人Paul Graham的218篇博客文章当做测试数据。
在文档的不同位置添加特定的语句:旧金山最美好的事情就是在阳光明媚的日子里,坐在多洛雷斯公园,享用一份三明治
请使用所提供的上下文来回答问题,在不同上下文长度和添加在不同位置的文档中,反复测试GPT-4和Claude2.1

最终使用Langchain Evals库对结果进行评估
作者把这套测试命名为“干草堆里找针/大海捞针”,并把代码开源在GitHub上,已获得200+星,并透露已经有公司赞助了对下一个大模型的测试。
AI公司自己找到解决办法
几周后,Claude背后公司Anthropic仔细分析后却发现,AI只是不愿意回答基于文档中单个句子的问题,特别是这个句子是后来插入的,和整篇文章关系不大的时候。
换句话说,如果AI判断这句话与文章主题无关,则会采取不查找每句话的方法
 文心大模型
文心大模型
百度飞桨-文心大模型 ERNIE 3.0 文本理解与创作
 56 查看详情
56 查看详情 

这时就需要用点手段晃过AI,要求Claude在回答开头添加那句“Here is the most relevant sentence in the context:”就能解决。
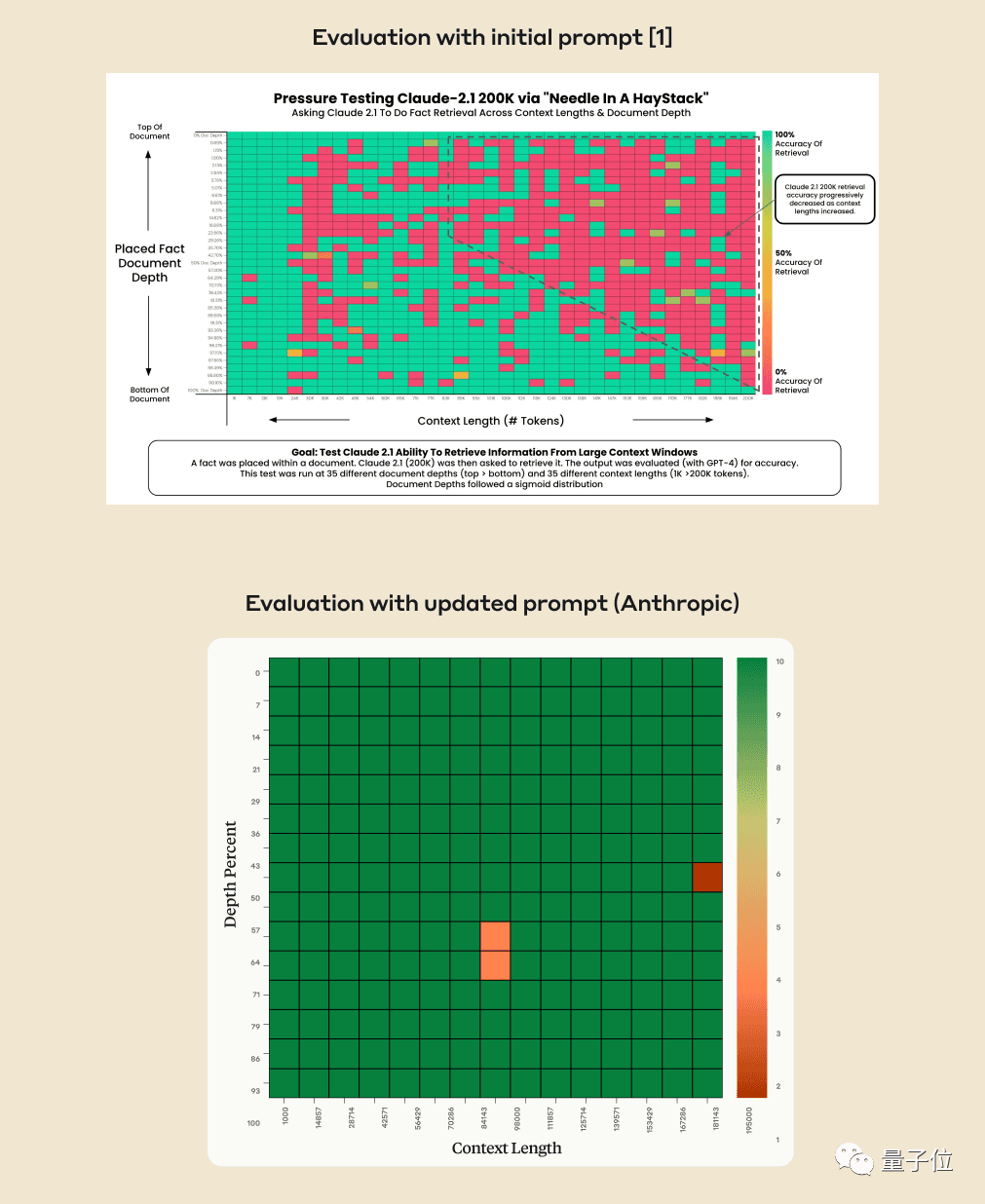
使用这种方法可以提高Claude的表现,即使在查找原文中未被人为添加的句子时也可以如此
Anthropic公司表示将来会不断的继续训练Claude,让它能更适应此类任务。
在使用API时,要求AI以特定的开头回答,并且还可以有其他巧妙的用途
马特·舒默(Matt Shumer)这个创业家在阅读该方案后给出了一些小技巧的补充
如果想让AI输出纯JSON格式,提示词的最后以“{”结尾。同理,如果想让AI列出罗马数字,提示词以“I:”结尾就行。
不过事情还没完……
国内的大型公司也开始注意到这项测试,并开始尝试他们自己的大型模型是否能够通过
同样拥有超长上下文的月之暗面Kimi大模型团队也测出了问题,但给出了不同的解决方案,也取得了很好的成绩。

在不改变原义的情况下,需要重写的内容是:这样做的好处是,修改用户提问提示比要求AI在回答中添加一句更容易实现,尤其是在不调用API而直接使用聊天机器人产品的情况下
我使用了一种新方法来帮助测试GPT-4和Claude2.1的月球背面,结果显示GPT-4取得了显著的改善,而Claude2.1只有轻微的改善
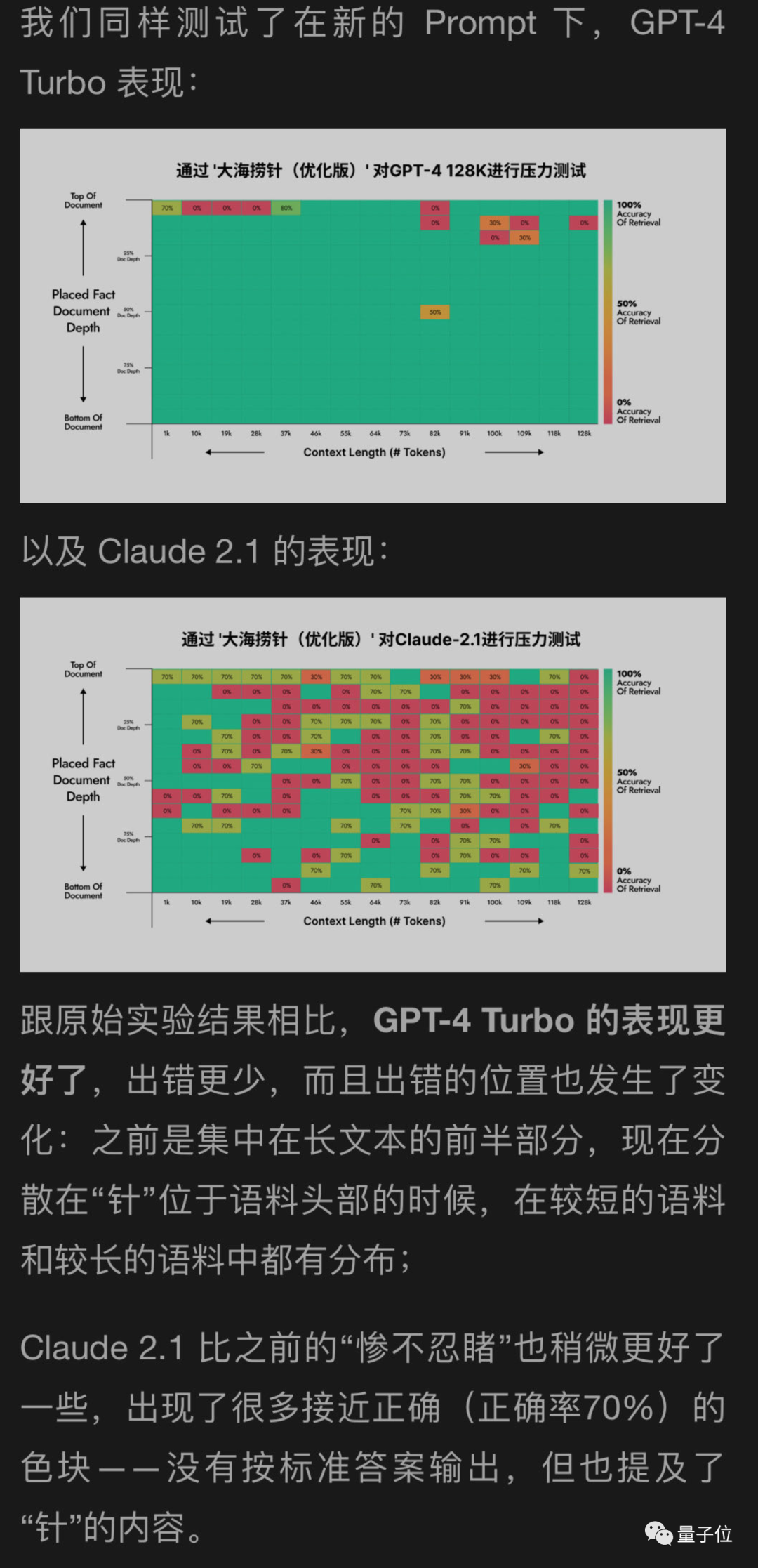
看来这个实验本身有一定局限性,Claude也是有自己的特殊性,可能与他们自己的对齐方式Constituional AI有关,需要用Anthropic自己提供的办法更好。
后来,月球背面的工程师继续进行了更多轮的实验,其中一个实验居然是……

糟糕,我变成测试数据了
以上就是解锁GPT-4和Claude2.1:一句话带你实现100k+上下文大模型的真实力,将27分提升至98的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/628582.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


















