
本文介绍基于PaddleDetection的PPYOLO tiny模型开发项目,可检测人眼和嘴的张闭以判断疲劳状态,适用于课堂学生打瞌睡提醒、驾驶员疲劳驾驶预警等场景。项目详述了PPYOLO tiny的优化策略、精度速度优势,还介绍了数据处理、模型训练、导出及部署等实施步骤。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

老规矩,先上 视频
背景介绍
背景一(老师的福音)
讲台上老师认真上课,口若悬河;讲台下同学频频点头,双目具闭!
45分钟是很紧张的,老师在这个时间段内需要把计划的教学任务完成,而如果学生无法积极配合、认真听讲,还在“闭目养神”、留着口水,老师还需要在课堂上叫醒那些“已经睡着了的人”,其实课堂效率就大大降低了。
而如果此时能够通过室内摄像头捕捉学生面部表情及动作,以此来识别学生是否在打瞌睡,并向同学及老师积极反馈,或许能够大大提高课堂效率,也方便老师及时了解学生课堂情况。
背景二(交通出行)
一个人开车是一件很累的事,尤其是开长途,到了行车后期,人会非常疲惫,会出现“闭目”、“打哈欠”等动作。而此时,由于人的反应能力受阻,很容易发生交通事故。
此时若有一个检测设备,监测驾驶员的面部表情,在其疲惫时及时提醒驾驶员注意休息,能够有效避免因疲劳驾驶而导致的车祸发生。
而“眼睛”的睁闭和“嘴”的张闭是检测人是否疲劳的一种合理方案。

技术方案
本项目基于PaddleDetection目标检测开发套件,选取1.3M超轻量PPYOLO tiny进行项目开发,并部署于windows端。
PPYOLO tiny是什么?
在当前移动互联网、物联网、车联网等行业迅猛发展的背景下,边缘设备上直接部署目标检测的需求越来越旺盛。生产线上往往需要在极低硬件成本的硬件例如树莓派、FPGA、K210 等芯片上部署目标检测算法。而我们常用的手机 App,也很难直接在终端采用超过 6M 的深度学习算法。如何在尽量不损失精度的前提下,获得体积更小、运算速度更快的算法呢?得益于 PaddleSlim 飞桨模型压缩工具的能力,体积仅为 1.3M 的 PP-YOLO Tiny 诞生了!!
精度速度数据
那 PP-YOLO Tiny 具体采用了哪些优化策略呢?
首先,PP-YOLO Tiny 沿用了 PP-YOLO 系列模型的 spp,iou loss, drop block, mixup, sync bn 等优化方法,并进一步采用了近 10 种针对移动端的优化策略:
1、更适用于移动端的骨干网络:
骨干网络可以说是一个模型的核心组成部分,对网络的性能、体积影响巨大。PP-YOLO Tiny 采用了移动端高性价比骨干网络 MobileNetV3。
2、更适用移动端的检测头(head):
除了骨干网络,PP-YOLO Tiny 的检测头(head)部分采用了更适用于移动端的深度可分离卷积(Depthwise Separable Convolution),相比常规的卷积操作,有更少的参数量和运算成本, 更适用于移动端的内存空间和算力。
3、去除对模型体积、速度有显著影响的优化策略:
在 PP-YOLO 中,采用了近 10 种优化策略,但并不是每一种都适用于移动端轻量化网络,比如 iou aware 和 matrix nms 等。这类 Trick 在服务器端容易计算,但在移动端会引入很多额外的时延,对移动端来说性价比不高,因此去掉反而更适当。
4、使用更小的输入尺寸
为了在移动端有更好的性能,PP-YOLO Tiny 采用 320 和 416 这两种更小的输入图像尺寸。并在 PaddleDetection2.0 中提供 tools/anchor_cluster.py 脚本,使用户可以一键式的获得与目标数据集匹配的 Anchor。例如,在 COCO 数据集上,我们使用 320*320 尺度重新聚类了 anchor,并对应的在训练过程中把每 batch 图⽚的缩放范围调整到 192-512 来适配⼩尺⼨输⼊图片的训练,得到更高性能。
5、召回率优化
在使⽤⼩尺寸输入图片时,对应的目标尺寸也会被缩⼩,漏检的概率会变大,对应的我们采用了如下两种方法来提升目标的召回率:
a.原真实框的注册方法是注册到网格⾥最匹配的 anchor 上,优化后还会同时注册到所有与该真实框的 IoU 不小于 0.25 的 anchor 上,提⾼了真实框注册的正例。
b.原来所有与真实框 IoU 小于 0.7 的 anchor 会被当错负例,优化后将该阈值减小到 0.5,降低了负例比例。
通过以上增加正例、减少负例的方法,弥补了在小尺寸上的正负例倾斜问题,提高了召回率。
6、更大的 batch size
往往更大的 Batch Size 可以使训练更加稳定,获取更优的结果。在 PP-YOLO Tiny 的训练中,单卡 batch size 由 24 提升到了 32,8 卡总 batch size=8*32=256,最终得到在 COCO 数据集上体积 4.3M,精度与预测速度都较为理想的模型。
7、量化后压缩
最后,结合 Paddle Inference 和 Paddle Lite 预测库支持的后量化策略,即在将权重保存成量化后的 int8 数据。这样的操作,是模型体积直接压缩到了 1.3M,而预测时使用 Paddle Lite 加载权重,会将 int8 数据还原回 float32 权重,所以对精度和预测速度⼏乎没有任何影响。
通过以上一系列优化,我们就得到了 1.3M 超超超轻量的 PP-YOLO tiny 模型,而算法可以通过 Paddle Lite 直接部署在麒麟 990 等轻量化芯片上,预测效果也非常理想。
实地操作
In [1]
# 先将PaddleDetection从gitee上download下来!git clone https://gitee.com/paddlepaddle/PaddleDetection.git
数据处理
解压数据集;对数据进行标准化处理,将其转化为COCO格式以符合PaddleDetection中所支持的数据集格式。In [ ]
# 数据集解压!unzip -oq /home/aistudio/data/data85880/fdd-dataset.zip
In [ ]
# 这里修改原数据集中标注文件里元素中的内容!mkdir dataset/Annotations1import xml.dom.minidomimport ospath = r'dataset/Annotations' # xml文件存放路径sv_path = r'dataset/Annotations1' # 修改后的xml文件存放路径files = os.listdir(path)cnt = 1for xmlFile in files: dom = xml.dom.minidom.parse(os.path.join(path, xmlFile)) # 打开xml文件,送到dom解析 root = dom.documentElement # 得到文档元素对象 item = root.getElementsByTagName('path') # 获取path这一node名字及相关属性值 for i in item: i.firstChild.data = 'dataset/JPEGImages/' + str(cnt).zfill(6) + '.jpg' # xml文件对应的图片路径 with open(os.path.join(sv_path, xmlFile), 'w') as fh: dom.writexml(fh) cnt += 1
In [ ]
# 然后对数据集进行标准化格式操作%cd dataset/!rm -ir Annotations!mv Annotations1 Annotations%cd ..
rm: descend into directory 'dataset/Annotations'? ^Cmv: cannot stat 'dataset/Annotations1': No such file or directory
由于原数据集中存在图片数据与标注数据不匹配的问题,故需要将不匹配的这部分数据删除。
In [ ]
import os,shutiljpeg = 'dataset/JPEGImages'jpeg_list = os.listdir(jpeg)anno = 'dataset/Annotations'anno_list = os.listdir(anno)for pic in jpeg_list: name = pic.split('.')[0] anno_name = name + '.xml' print(anno_name) if anno_name not in anno_list: os.remove(os.path.join(jpeg,pic))
这里我们通过paddlex中的数据集划分工具帮助我们进行数据集划分。
In [ ]
!pip install paddlex!pip install paddle2onnx
In [ ]
我们设置了训练集、验证集、测试集比例为8:1:1,训练集共2332个samples,验证集和测试集均为291个samples。
In [ ]
!paddlex --split_dataset --format VOC --dataset_dir dataset --val_value 0.1 --test_value 0.1
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import impDataset Split Done.Train samples: 2332Eval samples: 291Test samples: 291Split files saved in dataset
In [ ]
PaddleDetection中提供了VOC数据集转COCO数据集的脚本,但提供的脚本存在一些bug,本人在PaddleDetection的Github issue中找到了一个修复后的脚本:x2coco.py。 这里我们将前面修改完毕的VOC格式的数据集转化为符合PaddleDetection PPYOLO tiny的COCO数据集格式。
In [ ]
!python x2coco.py --dataset_type voc --voc_anno_dir /home/aistudio/dataset/Annotations/ --voc_anno_list /home/aistudio/dataset/ImageSets/Main/train.txt --voc_label_list /home/aistudio/dataset/labels.txt --voc_out_name voc_test.json!python x2coco.py --dataset_type voc --voc_anno_dir /home/aistudio/dataset/Annotations/ --voc_anno_list /home/aistudio/dataset/ImageSets/Main/val.txt --voc_label_list /home/aistudio/dataset/labels.txt --voc_out_name voc_val.json!python x2coco.py --dataset_type voc --voc_anno_dir /home/aistudio/dataset/Annotations/ --voc_anno_list /home/aistudio/dataset/ImageSets/Main/test.txt --voc_label_list /home/aistudio/dataset/labels.txt --voc_out_name voc_train.json!mv voc_train.json dataset/!mv voc_test.json dataset/!mv voc_val.json dataset/
Start converting !100%|████████████████████████████████████| 1631/1631 [00:00<00:00, 12327.36it/s]Start converting !100%|██████████████████████████████████████| 583/583 [00:00<00:00, 12504.37it/s]Start converting !100%|████████████████████████████████████| 1283/1283 [00:00<00:00, 12609.82it/s]
修改配置文件(./PaddleDetection/configs/ppyolo/ppyolo_tiny_650e_coco.yml)
在yolo系列模型中,可以运行tools/anchor_cluster.py来得到适用于你的数据集Anchor,使用方法如下:
In [ ]
%cd PaddleDetection!pip install -r requirements.txt!python tools/anchor_cluster.py -c configs/ppyolo/ppyolo_tiny_650e_coco.yml -n 9 -s 608 -m v2 -i 1000%cd ..
为了适配在自定义数据集上训练,需要对参数配置做一些修改:
数据路径配置: 在yaml配置文件中,依据数据准备中准备好的路径,配置TrainReader、EvalReader和TestReader的路径。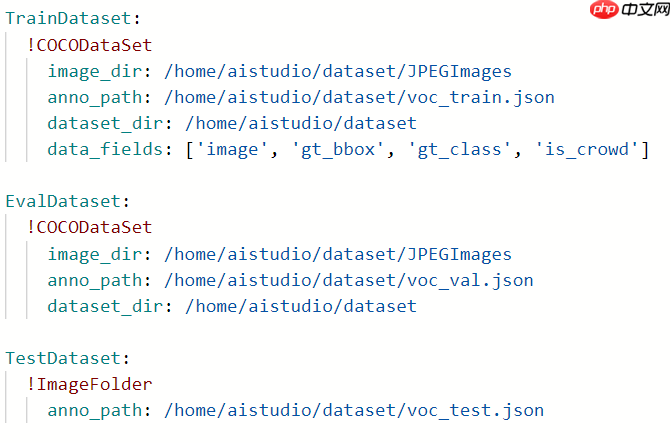
其余参数具体可参照PaddleDetection,这里不作过多介绍。
然后执行训练脚本即可。
In [ ]
%cd PaddleDetection/!python -u tools/train.py -c configs/ppyolo/ppyolo_tiny_650e_coco.yml -o pretrain_weights=https://paddledet.bj.bcebos.com/models/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams --eval
数据导出
训练完后我们将训练过程中保存的模型导出为inference格式模型,其原因在于:PaddlePaddle框架保存的权重文件分为两种:支持前向推理和反向梯度的训练模型 和 只支持前向推理的推理模型。二者的区别是推理模型针对推理速度和显存做了优化,裁剪了一些只在训练过程中才需要的tensor,降低显存占用,并进行了一些类似层融合,kernel选择的速度优化。而导出的inference格式模型包括__model__、__params__和model.yml三个文件,分别表示模型的网络结构、模型权重和模型的配置文件(包括数据预处理参数等)。
In [2]
# 导出模型,默认存储于output/ppyolo目录%cd PaddleDetection/!python tools/export_model.py -c configs/ppyolo/ppyolo_tiny_650e_coco.yml -o weights=/home/aistudio/model
/home/aistudio/PaddleDetection/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import imp/home/aistudio/PaddleDetection/ppdet/modeling/ops.py:529: DeprecationWarning: invalid escape sequence _ """/home/aistudio/PaddleDetection/ppdet/modeling/ops.py:1362: DeprecationWarning: invalid escape sequence l """[05/30 20:56:56] ppdet.utils.check ERROR: Config use_gpu cannot be set as true while you are using paddlepaddle cpu version ! Please try: 1. Install paddlepaddle-gpu to run model on GPU 2. Set use_gpu as false in config file to run model on CPU
同样的,PaddleDetection也提供了基于Python的预测脚本供开发者使用。 参数说明如下:
–model_dirYes上述导出的模型路径–image_fileOption需要预测的图片–image_dirOption要预测的图片文件夹路径–video_fileOption需要预测的视频–camera_idOption用来预测的摄像头ID,默认为-1(表示不使用摄像头预测,可设置为:0 – (摄像头数目-1) ),预测过程中在可视化界面按q退出输出预测结果到:output/output.mp4–use_gpuNo是否GPU,默认为False–run_modeNo使用GPU时,默认为fluid, 可选(fluid/trt_fp32/trt_fp16/trt_int8)–batch_sizeNo预测时的batch size,在指定image_dir时有效–thresholdNo预测得分的阈值,默认为0.5–output_dirNo可视化结果保存的根目录,默认为output/–run_benchmarkNo是否运行benchmark,同时需指定–image_file或–image_dir–enable_mkldnnNoCPU预测中是否开启MKLDNN加速–cpu_threadsNo设置cpu线程数,默认为1In [ ]
!python deploy/python/infer.py --model_dir=/path/to/models --image_file=/path/to/image --use_gpu=(False/True)
当然,在本项目中也提供了PaddleX 训练及导出方式,可供读者朋友尝试不同的飞桨套件。
In [ ]
# 环境变量配置,用于控制是否使用GPU# 说明文档:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html#gpuimport osos.environ['CUDA_VISIBLE_DEVICES'] = '0'from paddlex.det import transformsimport paddlex as pdx# 定义训练和验证时的transforms# API说明 https://paddlex.readthedocs.io/zh_CN/develop/apis/transforms/det_transforms.htmltrain_transforms = transforms.Compose([ transforms.MixupImage(mixup_epoch=250), transforms.RandomDistort(), transforms.RandomExpand(), transforms.RandomCrop(), transforms.Resize( target_size=608, interp='RANDOM'), transforms.RandomHorizontalFlip(), transforms.Normalize()])eval_transforms = transforms.Compose([ transforms.Resize( target_size=608, interp='CUBIC'), transforms.Normalize()])# 定义训练和验证所用的数据集# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/datasets.html#paddlex-datasets-vocdetectiontrain_dataset = pdx.datasets.VOCDetection( data_dir='dataset', file_list='dataset/train_list.txt', label_list='dataset/labels.txt', transforms=train_transforms, shuffle=True)eval_dataset = pdx.datasets.VOCDetection( data_dir='dataset', file_list='dataset/val_list.txt', label_list='dataset/labels.txt', transforms=eval_transforms)# 初始化模型,并进行训练# 可使用VisualDL查看训练指标,参考https://paddlex.readthedocs.io/zh_CN/develop/train/visualdl.htmlnum_classes = len(train_dataset.labels)# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#paddlex-det-ppyolomodel = pdx.det.PPYOLO(num_classes=num_classes)# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#train# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.htmlmodel.train( num_epochs=270, train_dataset=train_dataset, train_batch_size=8, eval_dataset=eval_dataset, learning_rate=0.000125, lr_decay_epochs=[210, 240], save_dir='output/ppyolo', save_interval_epochs=1, use_vdl=True)
In [ ]
!paddlex --export_inference --model_dir=output/ppyolo/best_model --save_dir=./inference_model
以上就是『PPYOLO tiny尝鲜』基于PaddleDetection的人脸疲劳检测的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/63222.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















