
由aggro crab与landfall联合推出的全新攀爬冒险力作《peak》自登陆steam平台以来人气飙升,首月销量迅速突破500万份大关。开发团队持续投入更新优化,此前曾引入“同类相食”机制引发热议,而今日正式上线的2.0版本更是带来了重磅内容升级。

2.0版本宣传视频:
本次更新最引人注目的亮点是全新生物群落——“平顶山”的加入。从下周起,“平顶山”将轮替取代原有的“雪山”地图,成为每局游戏中随机出现的新场景,实现双地图交替机制。这片神秘区域为玩家准备了10枚全新可收集徽章,部分徽章更可解锁限定外观饰品,增添探索乐趣。

“平顶山”以烈日炙烤下的沙地地貌为特色,环境严酷且充满挑战。为帮助玩家在此生存,更新加入了多项新道具:气球、侦察炮、遮阳伞、防晒霜、芦荟以及炸药,大幅提升策略多样性。此外,“熔炉”区域中还藏有一项神秘惊喜等待玩家亲自揭开。同时,新增的“昆虫恐惧模式”将贴心地屏蔽蜘蛛与爬虫类生物,照顾到敏感玩家的体验需求。

与此同时,《Peak》现已开启首次周间促销活动,原价33元,现折扣价仅需20.46元,性价比极高,正是入手的最佳时机。

完整更新日志如下:
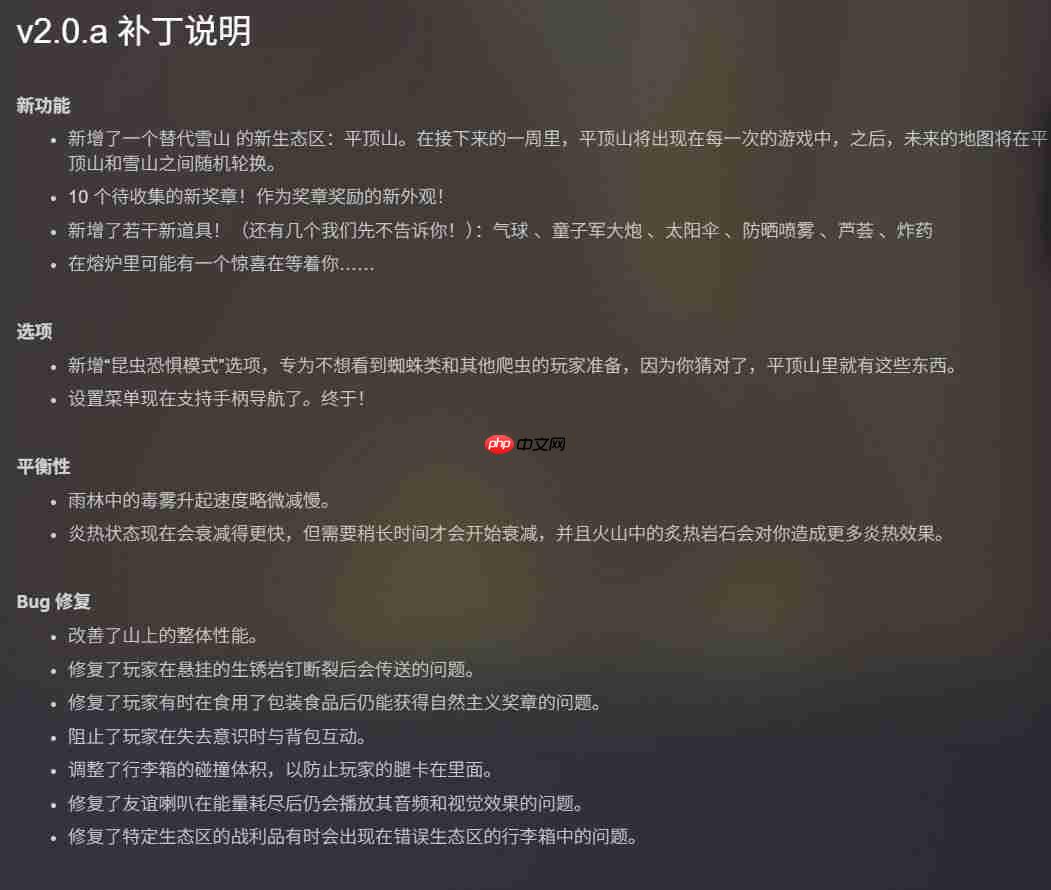
以上就是《PEAK》发布2.0版本重大更新 并同步开启周间促销的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/67668.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




















