本文阐述ResNet模型及其变体(B、C、D版本)的理论,包括残差单元、恒等映射、瓶颈模块等基础知识与架构,还介绍了模型演变。并以iChallenge-PM数据集为例,在眼疾识别中应用ResNet,通过训练、验证不同版本模型,评估其在病理性近视识别上的效果,各版本准确率达96.75%以上。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

ResNet在眼疾识别的应用
本文参考paddle课程文档,从理论角度阐述ResNet模型及其变体版本,并且在实践层次附上眼疾识别上的应用案例。
参考文献:
He T , Zhang Z , Zhang H , et al. Bag of Tricks for Image Classification with Convolutional Neural Networks[J]. 2018.
He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[J]. IEEE, 2016.
https://blog.csdn.net/sinat_17456165/article/details/106045728
https://aistudio.baidu.com/aistudio/education/preview/1533758
https://zhuanlan.zhihu.com/p/31852747/
https://www.cnblogs.com/xiaoboge/p/10539884.html
ResNet算法综述
ResNet背景
2015 年,ResNet横空出世,一举斩获 CVPR 2016 最佳论文奖,而且在Imagenet比赛的三个任务以及 COCO 比赛的检测和分割任务上都获得了第一名。
从经验来说,网络深度增加后,网络可以进行更加复杂的特征提取,因此可以取得更好的结果。但事实上并非如此,如以下图1所示,人们实验发现随着网络深度的增加,模型精度并不总是提升,并且这个问题显然不是由过拟合(overfitting)造成的,因为网络加深后不仅测试误差变高了,它的训练误差竟然也变高了。作者何凯明提出,这可能是因为更深的网络会伴随梯度消失/爆炸问题,从而阻碍网络的收敛。作者将这种加深网络深度但网络性能却下降的现象称为退化问题(degradation problem)。
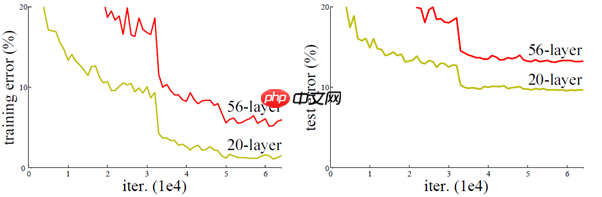
图1 20层与56层网络在CIFAR-10上的误差
何恺明举了一个例子:考虑一个训练好的网络结构,如果加深层数的时候,不是单纯的堆叠更多的层,而是堆上去一层使得堆叠后的输出和堆叠前的输出相同,也就是恒等映射/单位映射(identity mapping),然后再继续训练。这种情况下,按理说训练得到的结果不应该更差,因为在训练开始之前已经将加层之前的水平作为初始了,然而实验结果结果表明在网络层数达到一定的深度之后,结果会变差,这就是退化问题。这里至少说明传统的多层网络结构的非线性表达很难去表示恒等映射(identity mapping),或者说你不得不承认目前的训练方法或许有点问题,才使得深层网络很难去找到一个好的参数去表示恒等映射(identity mapping)。
这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。
ResNet基础知识
1.残差单元
对于一个堆积层结构(几层堆积而成)当输入为x时其学习到的特征记为H(x),现在我们希望其可以学习到残差F(x) = H(x) – x,这样其实原始的学习特征是H(x)。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为F(x) = 0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能,残差单元结构如下图2所示。容易通过数学证明,通过这样的残差结构,梯度的衰减得到了进一步抑制,并且加法的计算让训练的稳定性和容易性也得到了提高。所以可训练的网络的层数也大大增加了。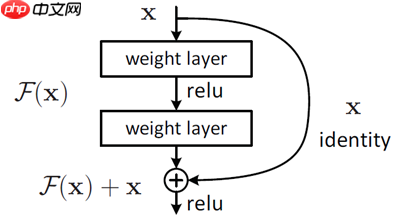
图2 残差学习结构图
代码的结构示意如下所示:
In [1]
def forword(x): # 路径1:表示短接步骤 identity_x=x # 路径2:表示残差部分,weight_layer和relu分别表示常见的卷积操作和relu函数处理 Fx=weight_layer(x) Fx=relu(Fx) Fx=weight_layer(x) # 对两条路径进行加和,然后实现非线性化输出 output=Fx+identity_x output=relu(output) return output
2.恒等映射/单位映射(identity mapping)
我们知道残差单元通过 identity mapping 的引入在输入和输出之间建立了一条直接的关联通道(如上图2 identity x),从而使得强大的有参层集中学习输入和输出之间的残差。一般我们用F(X, Wi)来表示残差映射,那么输出即为:Y = F(X, Wi) + X 。当输入和输出通道数相同时,我们自然可以如此直接使用X进行相加。而当它们之间的通道数目不同时,我们就需要考虑建立一种有效的 identity mapping 函数从而可以使得处理后的输入X与输出Y的通道数目相同即Y = F(X, Wi) + Ws*X。
当X与Y通道数目不同时,作者尝试了两种 identity mapping 的方式。一种即简单地将X相对Y缺失的通道直接补零从而使其能够相对齐的方式,另一种则是通过使用1×1的conv来表示Ws映射从而使得最终输入与输出的通道达到一致的方式。
代码的结构表示如下所示:
In [2]
def forword(x): # 路径1:表示关联通道,其映射方式为identity(x),在路径2的输入和输出形状相同时短接,返回值为x,在形状不同时,对x进行映射来达到一致 identity_x=identity_x(x) # 路径2:表示残差映射,用F(x)来表示 Fx=F(x) # 对两条路径进行加和,然后进行非线性化输出 output=Fx+identity_x output=relu(output) return output
3.瓶颈模块(BottleNeck)
如下图3所示,左图是一个很原始的常规模块,实际使用的时候,残差模块和Inception模块一样希望能够降低计算消耗。所以何凯明又进一步提出了“瓶颈(BottleNeck)”模块改进我们的 F(x) 的计算。通过使用1×1 conv来巧妙地缩减或扩张feature map维度从而使得我们的3×3 conv的filters数目不受外界即上一层输入的影响,自然它的输出也不会影响到下一层module,起到在保持精度的同时大幅降低了模型的计算量。

图3 Basicblock和BottleNeck (以上左图为Basicblock结构,右图为Bottleneck结构)
小知识:1×1卷积作用:
对通道数进行升维和降维(跨通道信息整合),实现了多个特征图的线性组合,同时保持了原有的特征图大小;
相比于其他尺寸的卷积核,可以极大地降低运算复杂度;
如果使用两个3×3卷积堆叠,只有一个relu,但使用1×1卷积就会有两个relu,引入了更多的非线性映射;
我们来计算一下1*1卷积的计算量优势:首先看上图右边的bottleneck结构,对于256维的输入特征,参数数目:
1∗1∗56∗64+3∗3∗64∗64+1∗1∗64∗256=696321∗1∗56∗64+3∗3∗64∗64+1∗1∗64∗256=69632
如果同样的输入输出维度但不使用1×1卷积,而使用两个3×3卷积的话,参数数目:
(3∗3∗256∗256)∗2=1179648(3∗3∗256∗256)∗2=1179648
简单计算可知,使用了1×1卷积的bottleneck将计算量简化为原有的5.9%。
两种结构的代码结构如下所示:
In [3]
# Rasicblock结构中Fxdef forword(x): x=conv3x3(x) x=relu(x) x=conv3x3(x) return x# BottleNeck结构中的Fxdef forword(x): x=conv1x1(x) x=relu(x) x=conv3x3(x) x=relu(x) x=conv1x1(x) return x
ResNet架构
ResNet整体网络图
如下图4所示,ResNet网络借鉴了VGG-19网络,基础卷积模块使用3×3卷积,在其基础上通过短路机制引入残差单元,并且通过引入1×1卷积的方式,提高算法的计算效率,确保了ResNet网络的高效性。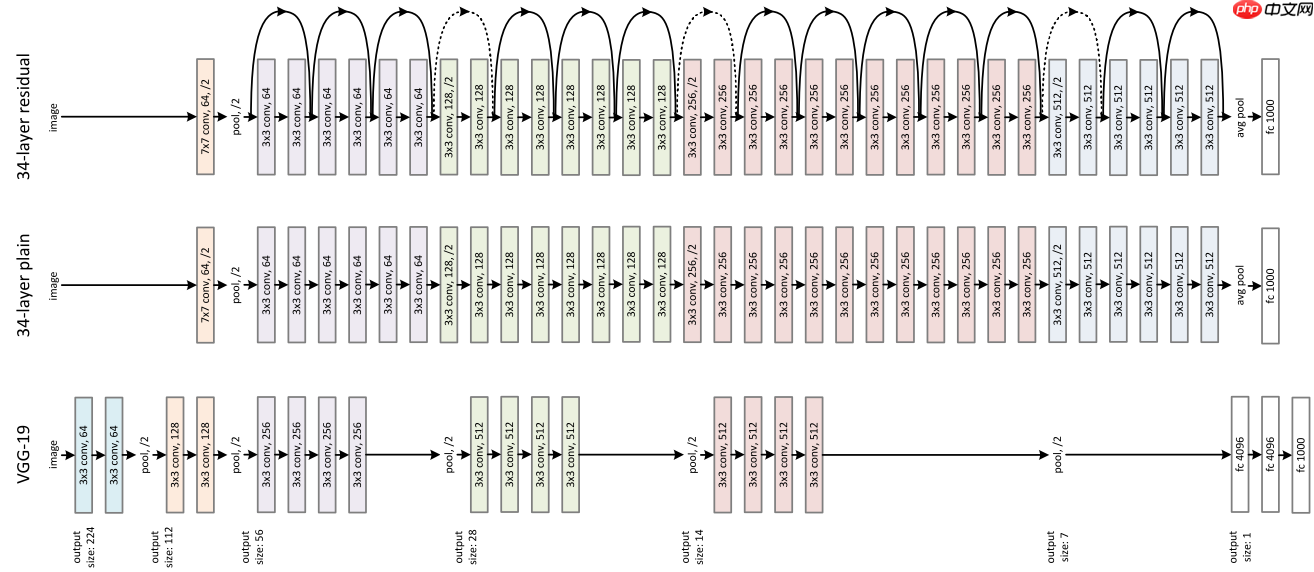 图4 ResNet-34、34-layer-plain-net、VGG的对比
图4 ResNet-34、34-layer-plain-net、VGG的对比
不同层数的ResNet网络结构
在ResNet网络中,直接使用了stride=2的卷积进行下采样,并且采用global average pool层替换了全连接层。
ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。
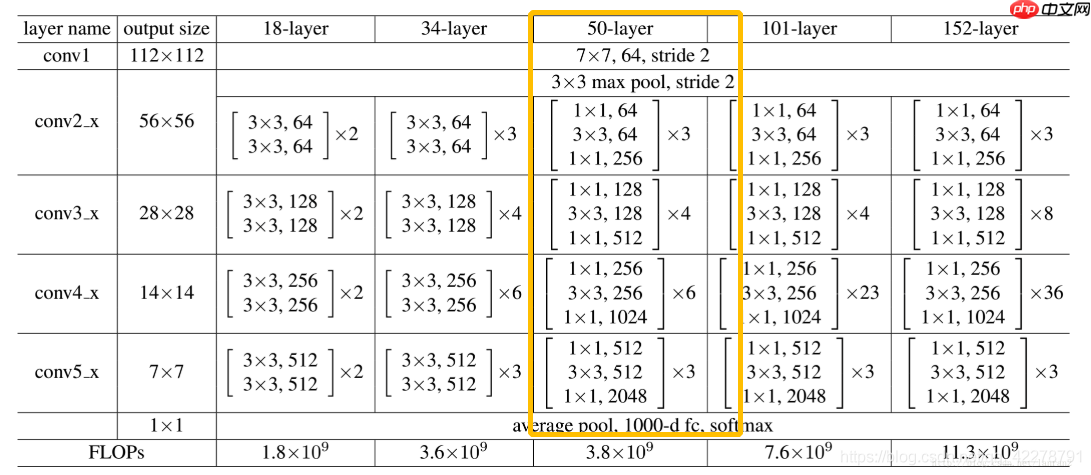
图5 model_structure
仔细观察这张细节图,我们不难发现一些规律和特点:
全图大致分为5个模块,其中2-5模块是残差单元构成的模块受VGG的启发,卷积层主要是3×3卷积同一模块内图片的尺寸大小不变,不同模块之间相差大小减半,深度变为4倍第2个模块网络输出和输出图像尺寸相同,因此不需要下采样第3-5模块的下采样仅操作一次,因此仅需要在每个模块的第一个block进行stride=2的下采样网络以平均池化层和softmax的全连接层结束,实际上工程上一般用自适应全局平均池化 (Adaptive Global Average Pooling);
ResNet算法构建
我们回顾一下最初的ResNet网络架构。如下图6所示。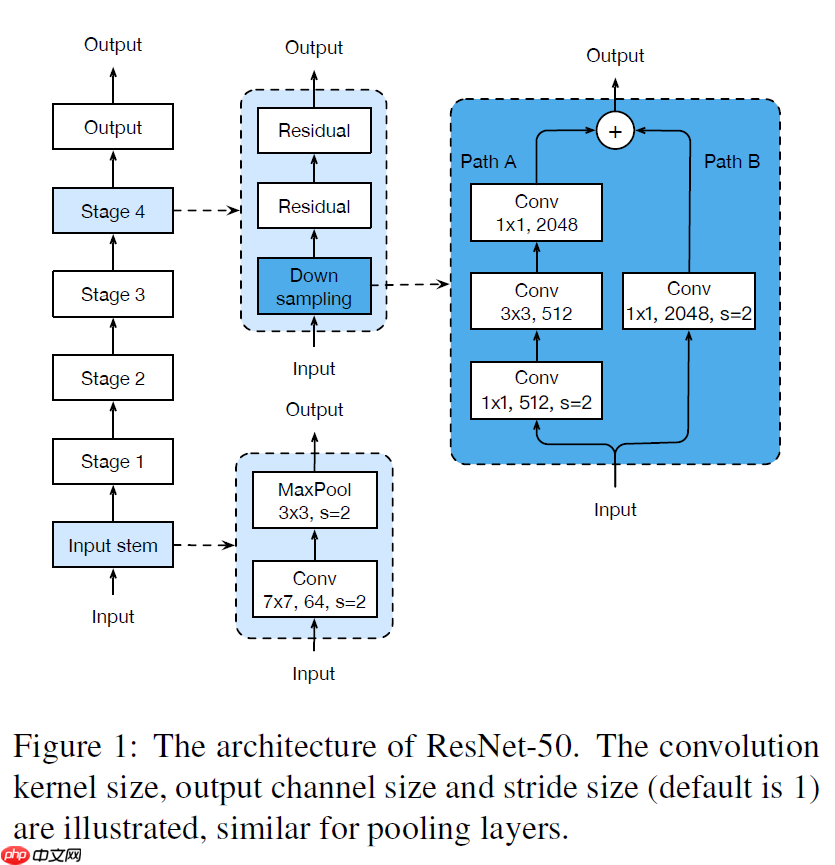
图6 the architecture of ResNet-50
一个传统的ResNet-50网络由一个input stem和四个后续stage和output组成的。其中的input stem会对初始数据依次进行一个步长为2,数量为64,大小为7×7的卷积操作,紧接着是一个步长为2,大小为3×3的MaxPool操作。而在stage2-4阶段则会有一个下采样阶段,这个下采样阶段则会有两条路径pathA和pathB,pathA依次通过1×1、3×3、1×1的卷积操作,pathB直接通过一个1×1的卷积操作,两者都实现将特征图的深度变为原来的4倍,下采样的output就是对pathA和pathB的结果进行加和。
基于以上的分析讨论,我们基于paddle框架对ResNet网络进行搭建。为了便于以下的分析讨论,我们将此版本称为O版本,通过API:version来控制搭建过程中,依赖的环境如下所示:
In [4]
import paddleimport paddle.nn as nnimport numpy as npprint(paddle.__version__)
2.1.2
BN卷积块
在分析讨论中,我们简单可以发现,ResNet的网络层数较深并且大量使用卷积操作,为此我们定义一个卷积模块,方便后续的调用使用及其对模块的调整修改。同时,我们在卷积操作之后采用批归一化BN的方式,以便提高模型的数值稳定性,加快模型的收敛速度,提高模型的鲁棒性。
其中参数含义如下:
num_channels:卷积层的输入通道数
num_filters:卷积层的输出通道数
filter_size:卷积核的大小
stride:卷积层的步幅,默认为1
groups:分组卷积的组数,默认groups=1不使用分组卷积
act:激活函数,默认为relu
具体代码如下所示:
注意:为保证每个模块内部卷积前后的图像尺寸不变 ,将卷积BN块的padding设计为(kernel_size-1)//2,这就保证了stride=1图像尺寸不变,stride=2图像尺寸减半。
In [5]
# 定义卷积BN块class ConvBNLayer(nn.Layer): def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act='relu'): super(ConvBNLayer,self).__init__() self._conv=nn.Conv2D( in_channels=num_channels, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=(filter_size-1)//2,# 确保下采样和尺寸不变 groups=groups, bias_attr=False, ) self._batch_norm=nn.BatchNorm2D(num_filters) self.act=act def forward(self,inputs): x=self._conv(inputs) x=self._batch_norm(x) if self.act=='leaky': x=nn.functional.leaky_relu(x=x,negative_slope=0.1) elif self.act=='relu': x=nn.functional.relu(x=x) return x
残差块
在通过以上分析之后,我们显然可以发现,在图6中,stage1-4阶段的down sampling和residual部分,块的基本架构是相同的,但是pathA和pathB仍旧存在以下的不同点:
pathA:down sampling中存在stride=2的下采样操作,residual中的stride=1是恒定的pathB:down sampling中下采样时,对应短接也要对数据进行1×1 conv变形操作,而residual中对数据直接进行短接
通过观察我们还可以发现以下规律:
stage1-4中依次由一个down sampling和若干个residual块组成stage1中的down sampling的stride=1,而在stage2-4中为2
我们利用参数self.shortcut=True来进行选择是否采用短接的方式。
为了便于后续不同版本的描述和理解,我们预留建立pathA_dict和pathB_dict的空字典,用于后面选择不同修改版本。pathA_default和pathB_default用来预设最初版本的设计,通过以下代码:
self.pathA=pathA_dict.get(version,pathA_default)
self.pathB=pathB_dict.get(version,pathB_default)
我们就可以很便捷的调整pathA和pathB的版本。
具体代码如下所示:
In [6]
# 定义残差块# 每个残差块会对输入图片做三次卷积,然后跟输入图片进行短接# 如果残差块中第三次卷积输出特征图的形状和输入不一致,则对输入图片做1x1卷积,将其输出形状调整为一致class BottleneckBlock(nn.Layer): def __init__(self, num_channels, num_filters, stride=1, shortcut=True, version='O' ): super(BottleneckBlock,self).__init__() pathA_dict={} pathB_dict={} pathA_default=nn.Sequential( ConvBNLayer(num_channels=num_channels,num_filters=num_filters,filter_size=1,stride=stride,), ConvBNLayer(num_channels=num_filters,num_filters=num_filters,filter_size=3,), ConvBNLayer(num_channels=num_filters,num_filters=num_filters*4,filter_size=1,act='None'), ) pathB_default=nn.Sequential( ConvBNLayer(num_channels=num_channels,num_filters=num_filters*4,filter_size=1,stride=stride,act='None'), ) self.shortcut=shortcut self.pathA=pathA_dict.get(version,pathA_default) self.pathB=pathB_dict.get(version,pathB_default) self._num_channels_out=num_filters*4 def forward(self,inputs): pathA=self.pathA(inputs) if self.shortcut: pathB=inputs else: pathB=self.pathB(inputs) output=paddle.add(x=pathA,y=pathB) output=nn.functional.relu(output) return output
ResNet网络
在我们完成组建底层组件之后 ,我们开始构建我们的顶层ResNet网络的搭建。我们的网络层数可选项为[50,101,152],它们在stage1-4模块分别有[3,4,6,3]、[3,4,23,3]、[3,8,36,3]个残差块,网络的输入图片格式为[N,3,224,224]。
input stem:
为了后续不同版本的描述和理解,我们预留空字典input_stem_dict,用以选择后续不同的版本的input_stem,通过设置input_stem_default来设定预设值,并且通过以下函数来进行input_stem的选择:
self.input_stem=input_stem_dict.get(version,input_stem_default)
stage1-4:
通过构建列表self.bottleneck_block_list,我们循环添加stage1-4当中的残差块部分。 其中的每个stage的深度我们通过网络层数layers来进行选择,对应stage的残差块的输出stage通道数我们通过num_filters=[64,128,256,512]来进行设定,并且在每一个stage的第一个残差块,我们将shortcut设置为False,完成变形操作,其余残差块设置为True,直接进行短接。
注意:stage1的所有残差块的stride=1,stage2-4模块仅有第一个残差块的stride=2实现下采样,因此我们通过stride=2 if i==0 and block!=0 else 1来stride的选择,其中block和i分别表示stage和每个stage中的残差块序号。
相关bottleneck的版本也通过version进行控制选择。
output:
最后输出部分,我们对stage4的输出结果进行一次全局池化之后展平,在对其进行全连接进行输出。如下所示:
x=self.pool2d_avg(x)
x=paddle.reshape(x,[x.shape[0],-1])
x=self.out(x)
其中self.out表示全连接
具体代码如下所示:
In [7]
# 定义ResNet模型class ResNet(nn.Layer): def __init__(self,layers=50,class_dim=10,version='O'): """ layers,网络层数,可以可选项:50,101,152 class_dim,分类标签的类别数 """ super(ResNet,self).__init__() self.version=version self.layers=layers self.max_accuracy=0.0 supported_layers=[50,101,152] assert layers in supported_layers, "supported layers are {} but input layer is {}".format(supported_layers,layers) # ResNet50包含的stage1-4模块分别包括3,4,6,3个残差块 if layers==50: depth=[3,4,6,3] # ResNet101包含的stage1-4模块分别包括3,4,23,3个残差块 if layers==101: depth=[3,4,23,3] # ResNet152包含的stage1-4分别包括3,8,36,3个残差块 if layers==152: depth=[3,8,36,3] # stage1-4所使用残差块的输出通道数 num_filters=[64,128,256,512] # input stem模块,默认版本:64个7x7的卷积加上一个3x3最大化池化层,步长均为2 input_stem_dict={} input_stem_default=nn.Sequential( ConvBNLayer(num_channels=3,num_filters=64,filter_size=7,stride=2,), nn.MaxPool2D(kernel_size=3,stride=2,padding=1,), ) self.input_stem=input_stem_dict.get(version,input_stem_default) # stage1-4模块,使用各个残差块进行卷积操作 self.bottleneck_block_list=[] num_channels=64 for block in range(len(depth)): shortcut=False for i in range(depth[block]): bottleneck_block=self.add_sublayer( 'bb_%d_%d'%(block,i), BottleneckBlock( num_channels=num_channels, num_filters=num_filters[block], stride=2 if i==0 and block!=0 else 1, shortcut=shortcut, version=version)) num_channels=bottleneck_block._num_channels_out self.bottleneck_block_list.append(bottleneck_block) shortcut=True # 在stage4的输出特征图上使用全局池化 self.pool2d_avg=nn.AdaptiveAvgPool2D(output_size=1) # stdv用来作为全连接层随机初始化参数的方差 import math stdv=1.0/math.sqrt(2048*1.0) # 创建全连接层,输出大小为类别数目,经过残差网络的卷积核全局池化后, # 卷积特征的维度是[B,2048,1,1],故最后一层全连接层的输入维度是2048 self.out=nn.Linear(in_features=2048,out_features=class_dim, weight_attr=paddle.ParamAttr( initializer=paddle.nn.initializer.Uniform(-stdv,stdv))) def forward(self,inputs): x=self.input_stem(inputs) for bottleneck_block in self.bottleneck_block_list: x=bottleneck_block(x) x=self.pool2d_avg(x) x=paddle.reshape(x,[x.shape[0],-1]) x=self.out(x) return x
ResNet网络的演变
我们这次所要介绍的ResNet演变主要有三个版本,我们分别成为ResNet-B,ResNet-C,ResNet-D,他们分别也是对input stem和down sampling进行的一些修改,如下图7所示。
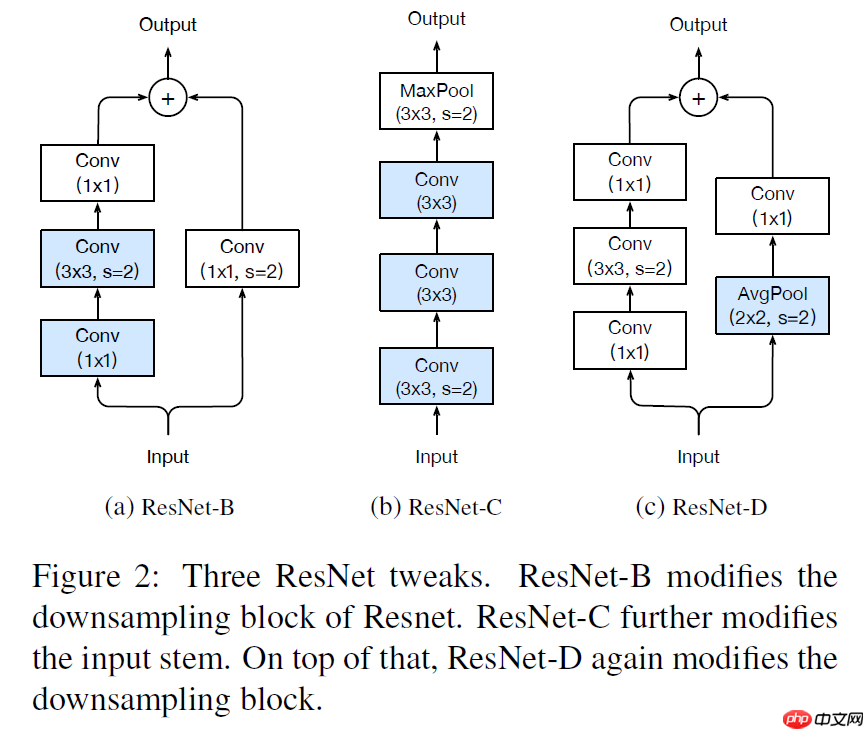
图7 ResNet-B、C、D
ResNet-B
这个版本的调整是对down sampling模块中pathA的调整,如上图7(a)所示,它最早出现在ResNet的torch实现当中,后来受到了大家广泛的认可和使用。
我们容易观察到在最初版的down sampling当中pathA在第一个1×1的卷积上的stride为2,通过以下图8的例子,我们可以很简单发现,这在进行特征映射时,将会忽略掉部分的特征信息,而当我们将stride=2这一步移至3×3卷积时,将不会有这个问题。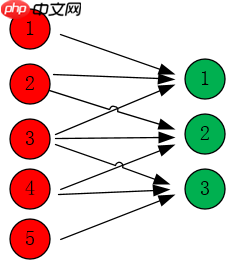
图8 特征映射图
显然,当卷积的kernel size为3时,输出神经元1、2、3分别包含了输入神经元123、234、345的信息,如果进而设置stride为2,那么输出神经元仅仅为1和3,已经包含了输入的5个神经元的信息,也即当前卷积层没有丢失特征信息。当卷积的kernel_size为1时,我们总会失去了2和4的信息,这就是我们进行此次调整的根本原因。
因此我们在类BottleneckBlock中加入pathA的调整版本pathA_tweak,并且通过代码pathA_dict[‘B’]=pathA_tweak在字典pathA_dict添加版本对应修改,通过参数version和self.pathA=pathA_dict.get(version,pathA_default)来实现对pathA版本的选择。
具体调整添加的代码如下所示:
In [8]
# pathA_tweak=nn.Sequential(# ConvBNLayer(num_channels=num_channels,num_filters=num_filters,filter_size=1,),# ConvBNLayer(num_channels=num_filters,num_filters=num_filters,filter_size=3,stride=stride,),# ConvBNLayer(num_channels=num_filters,num_filters=num_filters*4,filter_size=1,),# )# pathA_dict['B']=pathA_tweak
ResNet-C
这个版本的调整是对input stem模块的调整,如上图7(b)所示。我们观察到,卷积的操作的计算量是宽度和高度的二次函数,计算7×7卷积的计算量是计算3×3卷积的5.4倍,因此我们将7×7的卷积变化为三个依次的3×3卷积操作,其中下采样只在第一个进行,通过这个方法来减少计算量。
因此我们在类ResNet中添加input stem的调整版本input_stem_tweak,并且通过代码input_stem_dict[‘C’]=input_stem_tweak在字典input_stem_dict中添加版本对应修改,通过参数version和self.input_stem=input_stem_dict.get(version,input_stem_default来实现对input stem的选择。
具体调整添加的代码如下:
In [9]
# input_stem_tweak=nn.Sequential(# ConvBNLayer(num_channels=3,num_filters=64,filter_size=3,stride=2,)# ConvBNLayer(num_channels=64,num_filters=64,filter_size=3,)# ConvBNLayer(num_channels=64,num_filters=64,filter_size=3,)# nn.MaxPool2D(kernel_size=3,stride=2,padding=1,)# )# input_stem_dict['C']=input_stem_tweak
ResNet-D
受到了ResNet-B的启发,我们同样的观察到在down sampling中的pathB同样也存在着相同的问题,所以我们对pathB也进行了调整,使之效果更加优越,如上图7(c)所示。通过实验,我们发现在1×1的卷积前面加上AvgPool的效果更加好,因此我们做出了这个版本的调整。
我们在类BottleneckBlock中加入pathB的调整版本pathB_tweak,并且通过代码pathB_dict[‘D’]=pathB_tweak在字典pathB_dict添加版本对应修改,通过参数version和self.pathB=pathB_dict.get(version,pathB_default)来实现对pathB版本的选择。
于此同时,我们注意到D版本保留了B版本中的pathA调整,因此我们也要通过代码pathA_dict[‘D’]=pathA_tweak在字典pathA_dict添加版本对应修改。通过参数version和self.pathA=pathA_dict.get(version,pathA_default)来实现对pathA版本的选择。
调整添加的代码如下所示:
In [10]
# pathB_tweak=nn.Sequential(# nn.AvgPool2D(kernel_size=stride,stride=stride),# ConvBNLayer(num_channels=num_channels,num_filters=num_filters*4,filter_size=1),# )# pathB_dict['D']=pathB_tweak# pathA_dict['D']=pathA_tweak
将BCD版本的调整整合到一起,得到下列的模型设计,其中BN块没有发生改变。其中参数version的默认为’R’,但是可选版本有’B’,’C’,’D’三种,代码中分别都可以通过参数version来进行选择
In [11]
# 定义残差块# 每个残差块会对输入图片做三次卷积,然后跟输入图片进行短接# 如果残差块中第三次卷积输出特征图的形状和输入不一致,则对输入图片做1x1卷积,将其输出形状调整为一致class BottleneckBlock(nn.Layer): def __init__(self, num_channels, num_filters, stride=1, shortcut=True, version='O' ): super(BottleneckBlock,self).__init__() pathA_dict={} pathB_dict={} # default版本 pathA_default=nn.Sequential( ConvBNLayer(num_channels=num_channels,num_filters=num_filters,filter_size=1,stride=stride,), ConvBNLayer(num_channels=num_filters,num_filters=num_filters,filter_size=3,), ConvBNLayer(num_channels=num_filters,num_filters=num_filters*4,filter_size=1,act='None'), ) pathB_default=nn.Sequential( ConvBNLayer(num_channels=num_channels,num_filters=num_filters*4,filter_size=1,stride=stride,act='None'), ) # B版本修改 pathA_tweak=nn.Sequential( ConvBNLayer(num_channels=num_channels,num_filters=num_filters,filter_size=1,), ConvBNLayer(num_channels=num_filters,num_filters=num_filters,filter_size=3,stride=stride,), ConvBNLayer(num_channels=num_filters,num_filters=num_filters*4,filter_size=1,), ) pathA_dict['B']=pathA_tweak # D 版本修改 pathB_tweak=nn.Sequential( nn.AvgPool2D(kernel_size=stride,stride=stride), ConvBNLayer(num_channels=num_channels,num_filters=num_filters*4,filter_size=1), ) pathB_dict['D']=pathB_tweak pathA_dict['D']=pathA_tweak self.shortcut=shortcut self.pathA=pathA_dict.get(version,pathA_default) self.pathB=pathB_dict.get(version,pathB_default) self._num_channels_out=num_filters*4 def forward(self,inputs): pathA=self.pathA(inputs) if self.shortcut: pathB=inputs else: pathB=self.pathB(inputs) output=paddle.add(x=pathA,y=pathB) output=nn.functional.relu(output) return output
In [12]
# 定义ResNet模型class ResNet(nn.Layer): def __init__(self,layers=50,class_dim=10,version='O'): """ layers,网络层数,可以可选项:50,101,152 class_dim,分类标签的类别数 """ super(ResNet,self).__init__() self.version=version self.layers=layers self.max_accuracy=0.0 supported_layers=[50,101,152] assert layers in supported_layers, "supported layers are {} but input layer is {}".format(supported_layers,layers) # ResNet50包含的stage1-4模块分别包括3,4,6,3个残差块 if layers==50: depth=[3,4,6,3] # ResNet101包含的stage1-4模块分别包括3,4,23,3个残差块 if layers==101: depth=[3,4,23,3] # ResNet152包含的stage1-4分别包括3,8,36,3个残差块 if layers==152: depth=[3,8,36,3] # stage1-4所使用残差块的输出通道数 num_filters=[64,128,256,512] # input stem模块,default版本:64个7x7的卷积加上一个3x3最大化池化层,步长均为2 input_stem_dict={} input_stem_default=nn.Sequential( ConvBNLayer(num_channels=3,num_filters=64,filter_size=7,stride=2,), nn.MaxPool2D(kernel_size=3,stride=2,padding=1,), ) # C版本修改 input_stem_tweak=nn.Sequential( ConvBNLayer(num_channels=3,num_filters=64,filter_size=3,stride=2,), ConvBNLayer(num_channels=64,num_filters=64,filter_size=3,), ConvBNLayer(num_channels=64,num_filters=64,filter_size=3,), nn.MaxPool2D(kernel_size=3,stride=2,padding=1,), ) input_stem_dict['C']=input_stem_tweak self.input_stem=input_stem_dict.get(version,input_stem_default) # stage1-4模块,使用各个残差块进行卷积操作 self.bottleneck_block_list=[] num_channels=64 for block in range(len(depth)): shortcut=False for i in range(depth[block]): bottleneck_block=self.add_sublayer( 'bb_%d_%d'%(block,i), BottleneckBlock( num_channels=num_channels, num_filters=num_filters[block], stride=2 if i==0 and block!=0 else 1, shortcut=shortcut, version=version)) num_channels=bottleneck_block._num_channels_out self.bottleneck_block_list.append(bottleneck_block) shortcut=True # 在stage4的输出特征图上使用全局池化 self.pool2d_avg=nn.AdaptiveAvgPool2D(output_size=1) # stdv用来作为全连接层随机初始化参数的方差 import math stdv=1.0/math.sqrt(2048*1.0) # 创建全连接层,输出大小为类别数目,经过残差网络的卷积核全局池化后, # 卷积特征的维度是[B,2048,1,1],故最后一层全连接层的输入维度是2048 self.out=nn.Linear(in_features=2048,out_features=class_dim, weight_attr=paddle.ParamAttr( initializer=paddle.nn.initializer.Uniform(-stdv,stdv))) def forward(self,inputs): x=self.input_stem(inputs) for bottleneck_block in self.bottleneck_block_list: x=bottleneck_block(x) x=self.pool2d_avg(x) x=paddle.reshape(x,[x.shape[0],-1]) x=self.out(x) return x
眼疾识别案例的实现
数据集介绍
如今近视已经成为困扰人们健康的一项全球性负担,在近视人群中,有超过35%的人患有重度近视。近视会拉长眼睛的光轴,也可能引起视网膜或者络网膜的病变。随着近视度数的不断加深,高度近视有可能引发病理性病变,这将会导致以下几种症状:视网膜或者络网膜发生退化、视盘区域萎缩、漆裂样纹损害、Fuchs斑等。因此,及早发现近视患者眼睛的病变并采取治疗,显得非常重要。
iChallenge-PM是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。
其中训练集名称第一个字符表示类别,如下图9 所示。
图9 train data
H:高度近视HighMyopia
N:正常视力Normal
P:病理性近视Pathologic Myopia
P是病理性近似,正样本,类别为1;H和N不是病理性近似,负样本,类别为0。
验证集的类别信息储存在PALM-Validation-GT的PM_Label_and_Fovea_Location.xlsx文件中,如下图9 所示。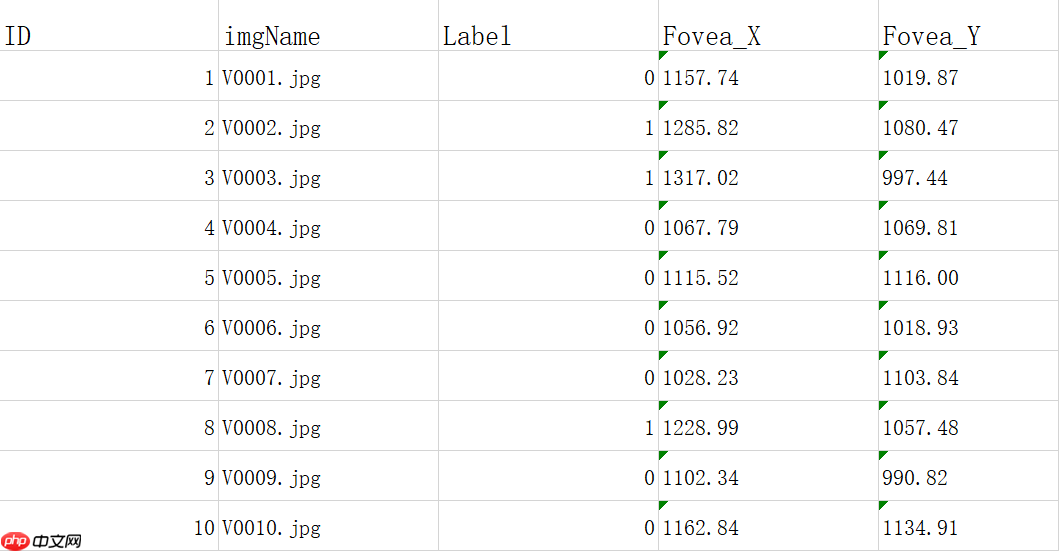
图10 validation
其中imgName列表示图片的名称,Label列表示图片对应的标签。
本案例所依赖的环境:
In [14]
import paddleimport paddle.nn as nnimport osimport cv2import numpy as npimport openpyxl
数据的导入和预处理
数据集在aistudio平台上可直接载入数据集,并且通过以下代码指令,我们进行解压到指定位置。
数据集data19469存放在data文件夹中
通过os.path.isdir()函数判断是否存在存放训练集的文件夹train_data和是否对载入的数据集data19469进行了解压,如果没有我们通过函数os.mkdir(“train_data”)创建train_data文件夹,并且对数据集进行解压,其中训练集图片解压到train_data文件夹中,以便使用。代码如下所示:
In [15]
if not os.path.isdir("train_data"): os.mkdir("train_data")else: print('Train_data exist')if not os.path.isdir('PALM-Training400'): !unzip -oq /home/aistudio/data/data19469/training.zip !unzip -oq /home/aistudio/data/data19469/validation.zip !unzip -oq /home/aistudio/data/data19469/valid_gt.zip !unzip -oq /home/aistudio/PALM-Training400/PALM-Training400.zip -d /home/aistudio/train_data/else: print('The data has been decompressed')
In [16]
# 查看训练集! dir /home/aistudio/train_data/PALM-Training400/.
H0001.jpg N0033.jpg N0091.jpg N0149.jpg P0046.jpg P0104.jpg P0162.jpgH0002.jpg N0034.jpg N0092.jpg N0150.jpg P0047.jpg P0105.jpg P0163.jpgH0003.jpg N0035.jpg N0093.jpg N0151.jpg P0048.jpg P0106.jpg P0164.jpgH0004.jpg N0036.jpg N0094.jpg N0152.jpg P0049.jpg P0107.jpg P0165.jpgH0005.jpg N0037.jpg N0095.jpg N0153.jpg P0050.jpg P0108.jpg P0166.jpgH0006.jpg N0038.jpg N0096.jpg N0154.jpg P0051.jpg P0109.jpg P0167.jpgH0007.jpg N0039.jpg N0097.jpg N0155.jpg P0052.jpg P0110.jpg P0168.jpgH0008.jpg N0040.jpg N0098.jpg N0156.jpg P0053.jpg P0111.jpg P0169.jpgH0009.jpg N0041.jpg N0099.jpg N0157.jpg P0054.jpg P0112.jpg P0170.jpgH0010.jpg N0042.jpg N0100.jpg N0158.jpg P0055.jpg P0113.jpg P0171.jpgH0011.jpg N0043.jpg N0101.jpg N0159.jpg P0056.jpg P0114.jpg P0172.jpgH0012.jpg N0044.jpg N0102.jpg N0160.jpg P0057.jpg P0115.jpg P0173.jpgH0013.jpg N0045.jpg N0103.jpg N0161.jpg P0058.jpg P0116.jpg P0174.jpgH0014.jpg N0046.jpg N0104.jpg P0001.jpg P0059.jpg P0117.jpg P0175.jpgH0015.jpg N0047.jpg N0105.jpg P0002.jpg P0060.jpg P0118.jpg P0176.jpgH0016.jpg N0048.jpg N0106.jpg P0003.jpg P0061.jpg P0119.jpg P0177.jpgH0017.jpg N0049.jpg N0107.jpg P0004.jpg P0062.jpg P0120.jpg P0178.jpgH0018.jpg N0050.jpg N0108.jpg P0005.jpg P0063.jpg P0121.jpg P0179.jpgH0019.jpg N0051.jpg N0109.jpg P0006.jpg P0064.jpg P0122.jpg P0180.jpgH0020.jpg N0052.jpg N0110.jpg P0007.jpg P0065.jpg P0123.jpg P0181.jpgH0021.jpg N0053.jpg N0111.jpg P0008.jpg P0066.jpg P0124.jpg P0182.jpgH0022.jpg N0054.jpg N0112.jpg P0009.jpg P0067.jpg P0125.jpg P0183.jpgH0023.jpg N0055.jpg N0113.jpg P0010.jpg P0068.jpg P0126.jpg P0184.jpgH0024.jpg N0056.jpg N0114.jpg P0011.jpg P0069.jpg P0127.jpg P0185.jpgH0025.jpg N0057.jpg N0115.jpg P0012.jpg P0070.jpg P0128.jpg P0186.jpgH0026.jpg N0058.jpg N0116.jpg P0013.jpg P0071.jpg P0129.jpg P0187.jpgN0001.jpg N0059.jpg N0117.jpg P0014.jpg P0072.jpg P0130.jpg P0188.jpgN0002.jpg N0060.jpg N0118.jpg P0015.jpg P0073.jpg P0131.jpg P0189.jpgN0003.jpg N0061.jpg N0119.jpg P0016.jpg P0074.jpg P0132.jpg P0190.jpgN0004.jpg N0062.jpg N0120.jpg P0017.jpg P0075.jpg P0133.jpg P0191.jpgN0005.jpg N0063.jpg N0121.jpg P0018.jpg P0076.jpg P0134.jpg P0192.jpgN0006.jpg N0064.jpg N0122.jpg P0019.jpg P0077.jpg P0135.jpg P0193.jpgN0007.jpg N0065.jpg N0123.jpg P0020.jpg P0078.jpg P0136.jpg P0194.jpgN0008.jpg N0066.jpg N0124.jpg P0021.jpg P0079.jpg P0137.jpg P0195.jpgN0009.jpg N0067.jpg N0125.jpg P0022.jpg P0080.jpg P0138.jpg P0196.jpgN0010.jpg N0068.jpg N0126.jpg P0023.jpg P0081.jpg P0139.jpg P0197.jpgN0011.jpg N0069.jpg N0127.jpg P0024.jpg P0082.jpg P0140.jpg P0198.jpgN0012.jpg N0070.jpg N0128.jpg P0025.jpg P0083.jpg P0141.jpg P0199.jpgN0013.jpg N0071.jpg N0129.jpg P0026.jpg P0084.jpg P0142.jpg P0200.jpgN0014.jpg N0072.jpg N0130.jpg P0027.jpg P0085.jpg P0143.jpg P0201.jpgN0015.jpg N0073.jpg N0131.jpg P0028.jpg P0086.jpg P0144.jpg P0202.jpgN0016.jpg N0074.jpg N0132.jpg P0029.jpg P0087.jpg P0145.jpg P0203.jpgN0017.jpg N0075.jpg N0133.jpg P0030.jpg P0088.jpg P0146.jpg P0204.jpgN0018.jpg N0076.jpg N0134.jpg P0031.jpg P0089.jpg P0147.jpg P0205.jpgN0019.jpg N0077.jpg N0135.jpg P0032.jpg P0090.jpg P0148.jpg P0206.jpgN0020.jpg N0078.jpg N0136.jpg P0033.jpg P0091.jpg P0149.jpg P0207.jpgN0021.jpg N0079.jpg N0137.jpg P0034.jpg P0092.jpg P0150.jpg P0208.jpgN0022.jpg N0080.jpg N0138.jpg P0035.jpg P0093.jpg P0151.jpg P0209.jpgN0023.jpg N0081.jpg N0139.jpg P0036.jpg P0094.jpg P0152.jpg P0210.jpgN0024.jpg N0082.jpg N0140.jpg P0037.jpg P0095.jpg P0153.jpg P0211.jpgN0025.jpg N0083.jpg N0141.jpg P0038.jpg P0096.jpg P0154.jpg P0212.jpgN0026.jpg N0084.jpg N0142.jpg P0039.jpg P0097.jpg P0155.jpg P0213.jpgN0027.jpg N0085.jpg N0143.jpg P0040.jpg P0098.jpg P0156.jpgN0028.jpg N0086.jpg N0144.jpg P0041.jpg P0099.jpg P0157.jpgN0029.jpg N0087.jpg N0145.jpg P0042.jpg P0100.jpg P0158.jpgN0030.jpg N0088.jpg N0146.jpg P0043.jpg P0101.jpg P0159.jpgN0031.jpg N0089.jpg N0147.jpg P0044.jpg P0102.jpg P0160.jpgN0032.jpg N0090.jpg N0148.jpg P0045.jpg P0103.jpg P0161.jpg
图片数据的导入基于cv2完成,同时加载的图片基于以下原因需要进行相应的预处理操作。
ResNet网络的理想输入图片尺寸为224×224,因此我们需要基于cv2.resize对每张图片进行放缩。cv2导入图像数据的格式为[H,W,C],因此需要基于np.transpose对结构进行重组为[C,H,W]。为了加快模型收敛的速率,使用数据标准化将数值范围放缩到-1.0到1.0之间
小知识:标准化作用 :
统一数据量纲平衡各特征的贡献加快了梯度下降求最优解的速度
具体代码如下所示:
In [17]
def transform_img(img): # 将图片尺寸缩放到 224x224 img=cv2.resize(img,(224,224)) # 读入的图像数据格式是[H,W,C] # 使用转置操作将其变成[C,H,W] img=np.transpose(img,(2,0,1)) img.astype('float32') img=img/255.0 img=img*2.0-1.0 return img
数据的批量读取
通过自定义的data_loader和valid_loader导入训练集和验证集,并且在data_loader中打乱训练集。两者都预设batch_size选项设定每一个预设batch的大小。验证准确率和损失值由所有的batch的平均所得到。
参数解释:
datadir:图片数据存在的文件夹路径
annotiondir:验证集标签文件路径
batch_size:每个批次的图片数据的数量
output:
每个batch的图片数据,数据类型:float32,numpy保存,维度:[N,C,H,W]
注意:其中训练集再导入时每个epoch都会进行随机打乱,而验证集不会
具体代码如下所示:
In [18]
def data_loader(datadir,batch_size=10,mode='train'): filenames=os.listdir(datadir) def reader(): if mode =='train': np.random.shuffle(filenames) batch_imgs=[] batch_labels=[] for name in filenames: filepath=os.path.join(datadir,name) img=cv2.imread(filepath) img=transform_img(img) if name[0]=='H' or name[0]=='N': label=0 elif name[0]=='P': label=1 elif name[0]=='V': continue else: raise('Not excepted file name') batch_imgs.append(img) batch_labels.append(label) if len(batch_imgs)==batch_size: imgs_array=np.array(batch_imgs).astype('float32') labels_array=np.array(batch_labels).astype('float32').reshape(-1,1) yield imgs_array,labels_array batch_imgs=[] batch_labels=[] if len(batch_imgs)>0: imgs_array=np.array(batch_imgs).astype('float32') labels_array=np.array(batch_labels).astype('float32').reshape(-1,1) yield imgs_array,labels_array return reader def valid_data_loader(datadir,annotiondir): labeldir=annotiondir def reader(batch_size=50): images=[] labels=[] workbook=openpyxl.load_workbook(labeldir,data_only=True) worksheet=workbook.active for row in worksheet.iter_rows(min_row=2,max_row=worksheet.max_row): image=cv2.imread(datadir+'/'+row[1].value) image=transform_img(image) images.append(image) label=float(row[2].value) labels.append(label) if len(images)==batch_size: images_array=np.array(images).astype('float32') labels_array=np.array(labels).astype('float32').reshape(-1,1) yield images_array,labels_array images=[] labels=[] if len(images)>0: images_array=np.array(images).astype('float32') labels_array=np.array(labels).astype('float32').reshape(-1,1) yield images_array,labels_array return reader
模型训练与验证
模型保存策略函数
accuracy表示我们需要保存的最大准确率,model参数为我们要保存的模型。
save函数调用时将会用当前accuracy覆盖模型的最大正确率model.max_accuracy
本案例所采用的方式是判断此次模型的参数使得验证集的正确率是否有提升。
代码如下。如需要可以另设其他保存策略。
In [19]
# 构建模型保存函数def save(accuracy,model): print('model save success !') if model==None: return model.max_accuracy=accuracy # 覆盖当前的最大正确率 paddle.save(model.state_dict(),f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams') # 保存模型save(1.0,None)
model save success !
训练函数
训练过程中,通过判断条件save!=None and valid_accuracy>model.max_accuracy是否为True,来确定是否执行模型保存步骤。
input:
model:待训练的模型
datadir:存放文件的主路径
annotiondir:存放标签数据的xlsx文件的路径
optimizer:优化模型参数所使用的优化器
batch_size:每个批次选取图片数量大小
EPOCH_NUM:训练的代数
use_gpu:是否使用GPU进行训练
save:模型保存的策略
相关代码参考如下。
In [20]
def train_pm(model, datadir, annotiondir, optimizer, batch_size=10, EPOCH_NUM=20, use_gpu=False, save=None): # 使用0号GPU训练 paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu') print('********start training********') # 定义训练数据读取器train_loader和验证数据读取器valid_loader train_loader=data_loader(datadir=datadir+'/train_data/PALM-Training400',batch_size=batch_size,mode='train') valid_loader=valid_data_loader(datadir+'/PALM-Validation400',annotiondir) # 初始化模型对应参数的验证正确率 model.max_accuracy,_=valid_pm(model,valid_loader,batch_size=50) print('Initial max accuracy :',model.max_accuracy) for epoch in range(EPOCH_NUM): model.train() for batch_id,data in enumerate(train_loader()): x_data,y_data=data img=paddle.to_tensor(x_data) label=paddle.to_tensor(y_data).astype('int64') # 使用模型进行前向计算,得到预测值 out=model(img) # 计算相应的损失值,并且得到对应的平均损失 loss=nn.functional.cross_entropy(out,label,reduction='none') avg_loss=paddle.mean(loss) if batch_id%10==0: #每10个batch输出1次训练结果 print("epoch:{}===batch_id:{}===loss:{:.4f}".format( epoch,batch_id,float(avg_loss.numpy()))) # 反向传播,更新权重,消除梯度 optimizer.clear_grad() loss.backward() optimizer.step() # 每个epoch进行一次训练集的验证,获取模型在验证集上的正确率和损失值 valid_accuracy,valid_loss=valid_pm(model,valid_loader,batch_size=50) print('[validation]:======accuracy:{:.5f}/loss:{:.5f}'.format(valid_accuracy,valid_loss)) # 如果模型准确率上升并且存在一个模型保存的策略,那么保存模型 if save!=None and valid_accuracy>model.max_accuracy: save(valid_accuracy,model) print('max accuracy :',model.max_accuracy) print() print('Final max accuracy :',model.max_accuracy)
验证函数
通过导入验证集数据,对我们的模型进行验证
input:
model:待验证的模型
valid_loader:验证数据的迭代生成器
batch_size:每一个批次验证数据的大小
相关代码参考如下。
注意:为保证避免显存问题,采用分批次验证,求平均值
In [21]
def valid_pm(model,valid_loader,batch_size=100): model.eval() print("*****valid data import success*****") batch_accuracy=[] batch_loss=[] for batch_id,data in enumerate(valid_loader(batch_size=batch_size)): # 加载数据,并且进行类型转换 x_data,y_data=data img=paddle.to_tensor(x_data) label=paddle.to_tensor(y_data).astype('int64') # 前向计算,计算预测值 out=model(img) predict=paddle.argmax(out,1) # 计算损失值和准确率,并且加入到相应列表中 loss=nn.functional.cross_entropy(out,label,reduction='none') avg_loss=paddle.mean(loss) accuracy=sum(predict.numpy().reshape(-1,1)==label.numpy())/float(label.shape[0]) batch_loss.append(float(avg_loss.numpy())) batch_accuracy.append(accuracy) # 将所有批次的损失值和准确率平均,得到最终损失值和准确率 avg_loss=np.mean(batch_loss) avg_accuracy=np.mean(batch_accuracy) return avg_accuracy,avg_loss
超参数及训练部分
超参数含义:
model_version:选择使用的ResNet版本,可选O、B、C、D,默认O;
use_gpu:是否使用gpu进行训练;
lr:学习率;
momentum:动量系数;
load_model:是否载入预训练模型;
save_model:是否保存训练模型; EPOCH_NUM:选择模型训练的代数
在训练之前,通过判断代码os.path.exists(f’./model/resnet{model.layers}_v{model.version}_PALM.pdparams’) and load_model预训练模型是否存在和是否载入预训练模型来确定是否加载模型参数model_params。
相关代码如下。
In [22]
# 超参数的设置use_gpu=Truelr=0.0001momentum=0.9load_model=Truesave_model=FalseEPOCH_NUM=20
In [23]
# 版本参数的设置model_version='O'filedir=os.getcwd() #获取文件当前的主路径model=ResNet(layers=50,class_dim=2,version=model_version)if os.path.exists(f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams') and load_model: model_params=paddle.load(f'./model/resnet{model.layers}_v{model_version}_PALM.pdparams') model.set_state_dict(model_params) # 加载预训练模型参数annotion_path=filedir+'/PALM-Validation-GT/PM_Label_and_Fovea_Location.xlsx' # 获取验证集标签数据地址optimizer=paddle.optimizer.Momentum(learning_rate=lr,momentum=momentum,parameters=model.parameters())# 选择优化器print('文件主路径:',filedir)print('训练模型版本:',model_version)print('是否采用预训练模型:',load_model)print('是否采用GPU:',use_gpu)if save_model: # 判断是否需要保存模型参数 save=saveelse: save=Nonetrain_pm(model,filedir,annotion_path,optimizer,EPOCH_NUM=EPOCH_NUM,use_gpu=use_gpu,save=save)
W1209 10:58:29.025938 138 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1W1209 10:58:29.031812 138 device_context.cc:422] device: 0, cuDNN Version: 7.6.
文件主路径: /home/aistudio训练模型版本: O是否采用预训练模型: True是否采用GPU: True********start training*************valid data import success*****Initial max accuracy : 0.7925
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:641: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
epoch:0===batch_id:0===loss:0.1874epoch:0===batch_id:10===loss:0.2566epoch:0===batch_id:20===loss:0.7382epoch:0===batch_id:30===loss:0.3455*****valid data import success*****[validation]:======accuracy:0.93000/loss:0.21557epoch:1===batch_id:0===loss:0.0430epoch:1===batch_id:10===loss:0.2609epoch:1===batch_id:20===loss:0.3745epoch:1===batch_id:30===loss:0.1537*****valid data import success*****[validation]:======accuracy:0.92750/loss:0.21657epoch:2===batch_id:0===loss:0.5271
—————————————————————————KeyboardInterrupt Traceback (most recent call last)/tmp/ipykernel_138/1753482911.py in 19 else: 20 save=None —> 21train_pm(model,filedir,annotion_path,optimizer,EPOCH_NUM=EPOCH_NUM,use_gpu=use_gpu,save=save) /tmp/ipykernel_138/819606217.py in train_pm(model, datadir, annotiondir, optimizer, batch_size, EPOCH_NUM, use_gpu, save)20 for epoch in range(EPOCH_NUM): 21 model.train() —> 22 for batch_id,data in enumerate(train_loader()): 23 x_data,y_data=data 24 img=paddle.to_tensor(x_data) /tmp/ipykernel_138/3504637695.py in reader() 8 for name infilenames: 9 filepath=os.path.join(datadir,name) —> 10 img=cv2.imread(filepath) 11 img=transform_img(img) 12 if name[0]==’H’ or name[0]==’N’: KeyboardInterrupt: In [ ]
# 版本参数的设置model_version='B'filedir=os.getcwd() #获取文件当前的主路径model=ResNet(layers=50,class_dim=2,version=model_version)if os.path.exists(f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams') and load_model: model_params=paddle.load(f'./model/resnet{model.layers}_v{model_version}_PALM.pdparams') model.set_state_dict(model_params) # 加载预训练模型参数annotion_path=filedir+'/PALM-Validation-GT/PM_Label_and_Fovea_Location.xlsx' # 获取验证集标签数据地址optimizer=paddle.optimizer.Momentum(learning_rate=lr,momentum=momentum,parameters=model.parameters())# 选择优化器print('文件主路径:',filedir)print('训练模型版本:',model_version)print('是否采用预训练模型:',load_model)print('是否采用GPU:',use_gpu)if save_model: # 判断是否需要保存模型参数 save=saveelse: save=Nonetrain_pm(model,filedir,annotion_path,optimizer,EPOCH_NUM=EPOCH_NUM,use_gpu=use_gpu,save=save)
In [ ]
# 版本参数的设置model_version='C'filedir=os.getcwd() #获取文件当前的主路径model=ResNet(layers=50,class_dim=2,version=model_version)if os.path.exists(f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams') and load_model: model_params=paddle.load(f'./model/resnet{model.layers}_v{model_version}_PALM.pdparams') model.set_state_dict(model_params) # 加载预训练模型参数annotion_path=filedir+'/PALM-Validation-GT/PM_Label_and_Fovea_Location.xlsx' # 获取验证集标签数据地址optimizer=paddle.optimizer.Momentum(learning_rate=lr,momentum=momentum,parameters=model.parameters())# 选择优化器print('文件主路径:',filedir)print('训练模型版本:',model_version)print('是否采用预训练模型:',load_model)print('是否采用GPU:',use_gpu)if save_model: # 判断是否需要保存模型参数 save=saveelse: save=Nonetrain_pm(model,filedir,annotion_path,optimizer,EPOCH_NUM=EPOCH_NUM,use_gpu=use_gpu,save=save)
In [ ]
# 版本参数的设置model_version='D'filedir=os.getcwd() #获取文件当前的主路径model=ResNet(layers=50,class_dim=2,version=model_version)if os.path.exists(f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams') and load_model: model_params=paddle.load(f'./model/resnet{model.layers}_v{model_version}_PALM.pdparams') model.set_state_dict(model_params) # 加载预训练模型参数annotion_path=filedir+'/PALM-Validation-GT/PM_Label_and_Fovea_Location.xlsx' # 获取验证集标签数据地址optimizer=paddle.optimizer.Momentum(learning_rate=lr,momentum=momentum,parameters=model.parameters())# 选择优化器print('文件主路径:',filedir)print('训练模型版本:',model_version)print('是否采用预训练模型:',load_model)print('是否采用GPU:',use_gpu)if save_model: # 判断是否需要保存模型参数 save=saveelse: save=Nonetrain_pm(model,filedir,annotion_path,optimizer,EPOCH_NUM=EPOCH_NUM,use_gpu=use_gpu,save=save)
模型评估
通过以下代码获取我们的验证数据的读取器valid_loader。
In [26]
annotion_path='./PALM-Validation-GT/PM_Label_and_Fovea_Location.xlsx'valid_loader=valid_data_loader('./PALM-Validation400',annotion_path)
通过参数model_version和model_layers选择载入模型的版本。
通过paddle.load和model.set_state_dict完成对模型参数的载入和配置
ResNet-O导入和验证
In [27]
# 模型版本选择model_version='O'model_layers=50# 模型的载入、模型参数的载入和配置model=ResNet(layers=model_layers,class_dim=2,version=model_version)model_params=paddle.load(f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams')model.set_state_dict(model_params)# 模型的验证过程valid_accuracy,valid_loss=valid_pm(model,valid_loader,batch_size=50)print('[validation]:===model:ResNet{}-{}===accuracy:{:.5f}/loss:{:.5f}'.format(model.layers,model.version,valid_accuracy,valid_loss))
*****valid data import success*****[validation]:===model:ResNet50-O===accuracy:0.97500/loss:0.11007
ResNet-B导入和验证
In [28]
# 模型版本选择model_version='B'model_layers=50# 模型的载入、模型参数的载入和配置model=ResNet(layers=model_layers,class_dim=2,version=model_version)model_params=paddle.load(f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams')model.set_state_dict(model_params)# 模型的验证过程valid_accuracy,valid_loss=valid_pm(model,valid_loader,batch_size=50)print('[validation]:===model:ResNet{}-{}===accuracy:{:.5f}/loss:{:.5f}'.format(model.layers,model.version,valid_accuracy,valid_loss))
*****valid data import success*****[validation]:===model:ResNet50-B===accuracy:0.97500/loss:0.12033
ResNet-C导入和验证
In [29]
# 模型版本选择model_version='C'model_layers=50# 模型的载入、模型参数的载入和配置model=ResNet(layers=model_layers,class_dim=2,version=model_version)model_params=paddle.load(f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams')model.set_state_dict(model_params)# 模型的验证过程valid_accuracy,valid_loss=valid_pm(model,valid_loader,batch_size=50)print('[validation]:===model:ResNet{}-{}===accuracy:{:.5f}/loss:{:.5f}'.format(model.layers,model.version,valid_accuracy,valid_loss))
*****valid data import success*****[validation]:===model:ResNet50-C===accuracy:0.97750/loss:0.11054
ResNet-D的导入和验证
In [30]
# 模型版本选择model_version='D'model_layers=50# 模型的载入、模型参数的载入和配置model=ResNet(layers=model_layers,class_dim=2,version=model_version)model_params=paddle.load(f'./model/resnet{model.layers}_v{model.version}_PALM.pdparams')model.set_state_dict(model_params)# 模型的验证过程valid_accuracy,valid_loss=valid_pm(model,valid_loader,batch_size=50)print('[validation]:===model:ResNet{}-{}===accuracy:{:.5f}/loss:{:.5f}'.format(model.layers,model.version,valid_accuracy,valid_loss))
*****valid data import success*****[validation]:===model:ResNet50-D===accuracy:0.96750/loss:0.10753
以上就是ResNet及BCD版本详解且在眼疾识别中应用实例的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/68298.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫