如今,多模态大模型(mllm)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(llm)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。
在 Meta 和纽约大学合作的一篇论文中,研究者探究了 LLM 是否也可以通过微调来生成具有同等效率和有效性的视觉信息?论文作者中包括了 AI 领域的几位知名学者,包括图灵奖得主 Yann LeCun、纽约大学计算机科学助理教授谢赛宁、FAIR 研究科学家刘壮(将于明年 9 月加盟普林斯顿大学,担任计算机科学系助理教授)。
 Imagine By Magic Studio
Imagine By Magic Studio
AI图片生成器,用文字制作图片
 79 查看详情
79 查看详情 
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

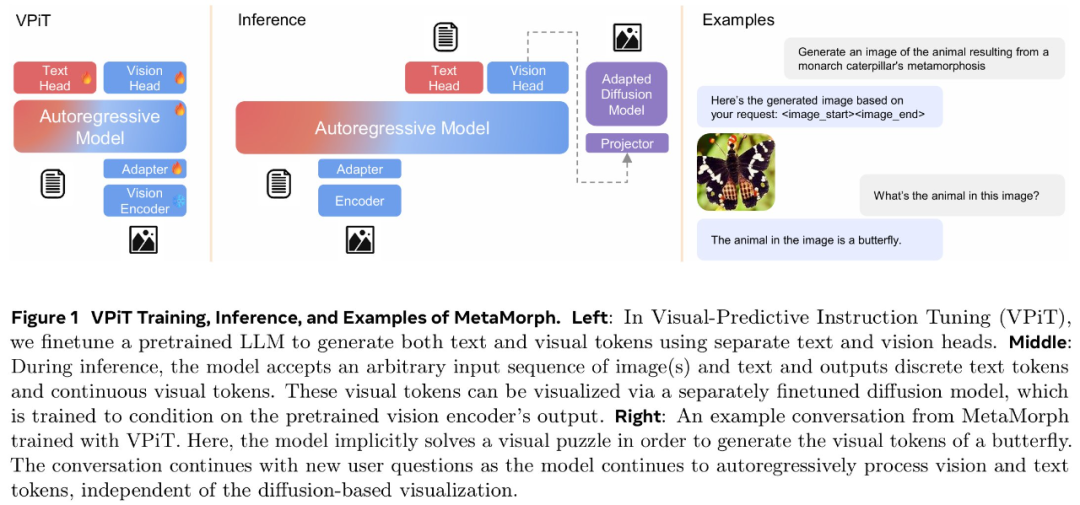
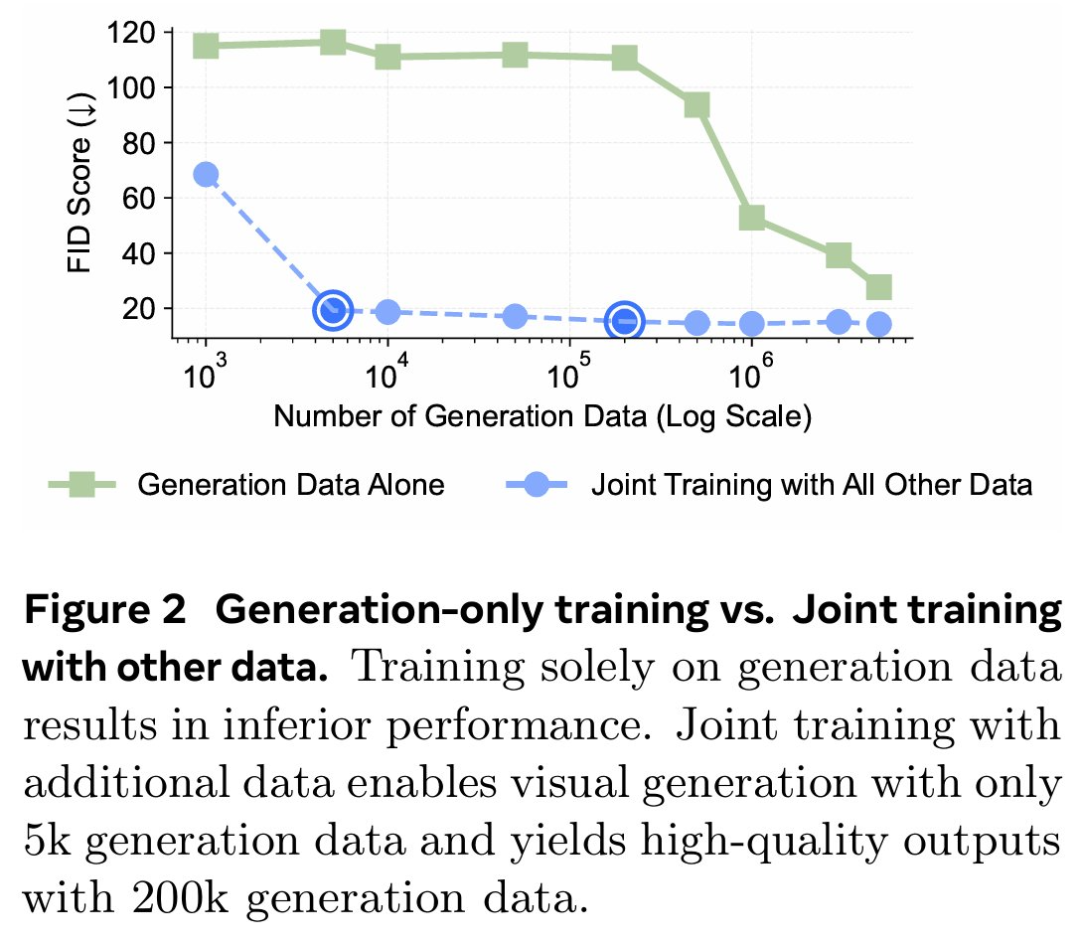
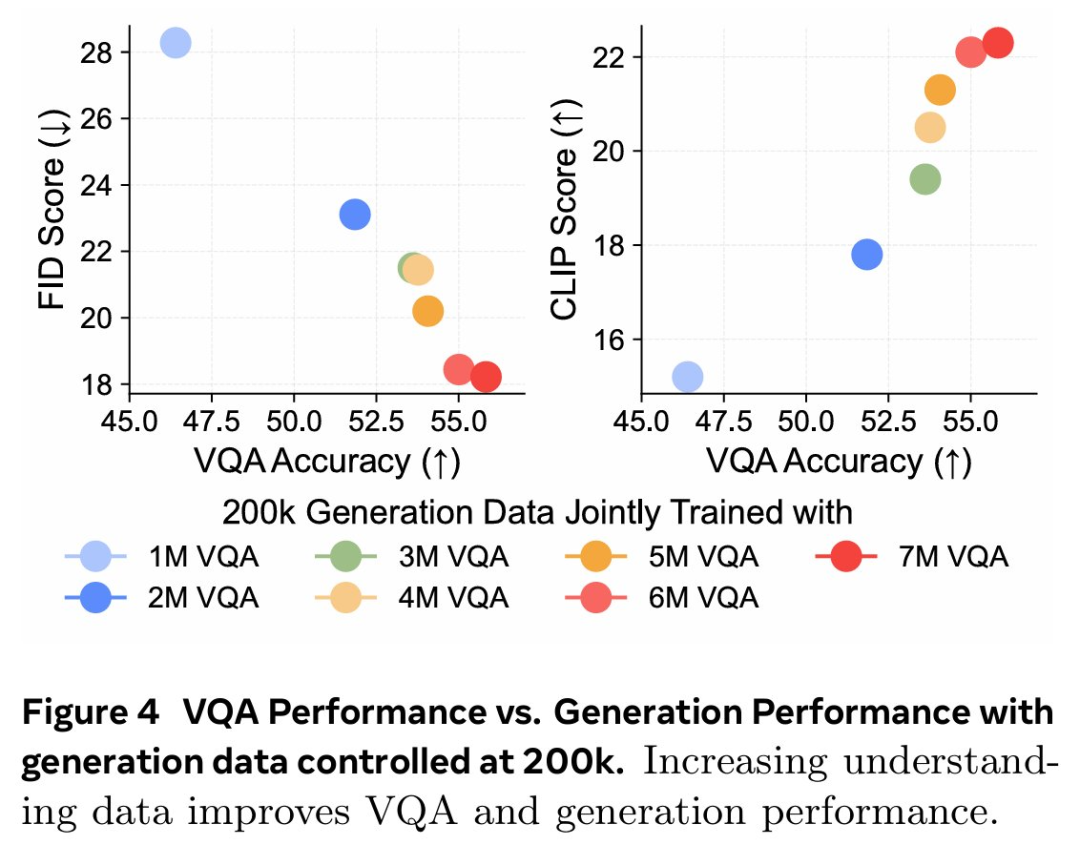
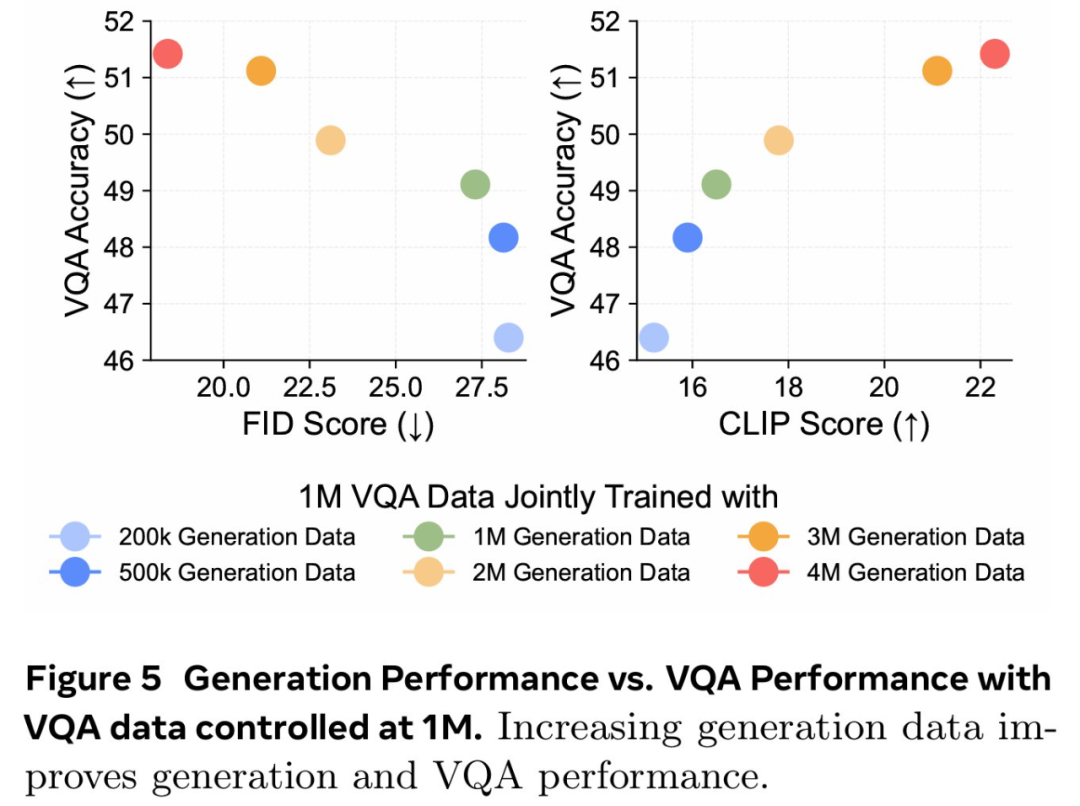
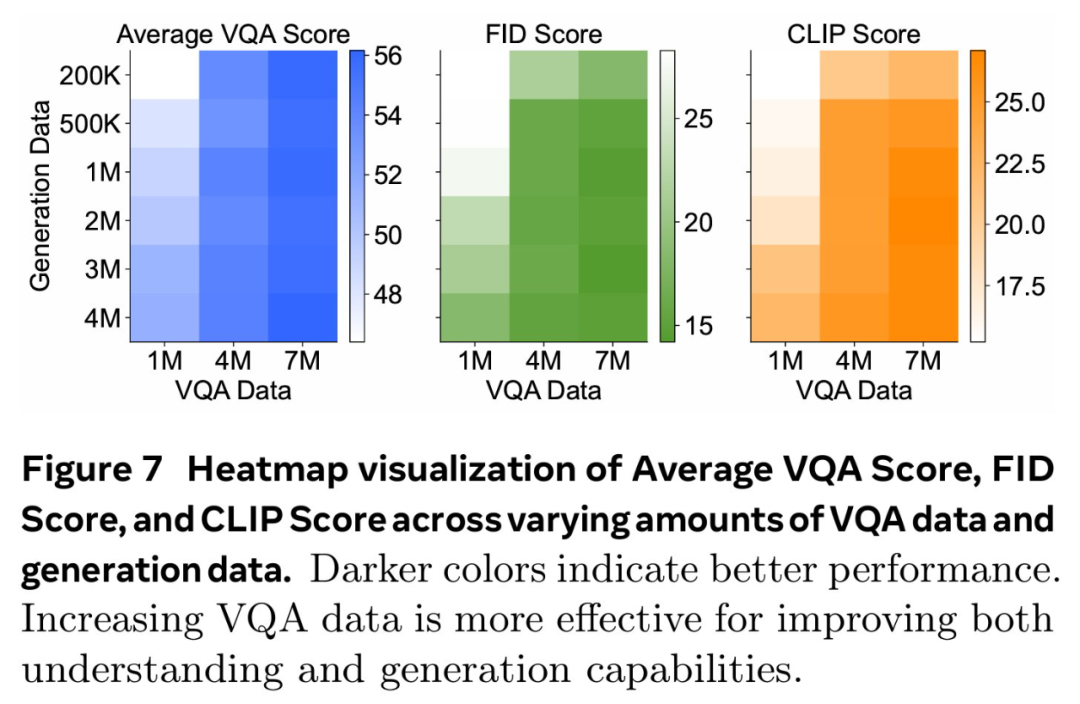
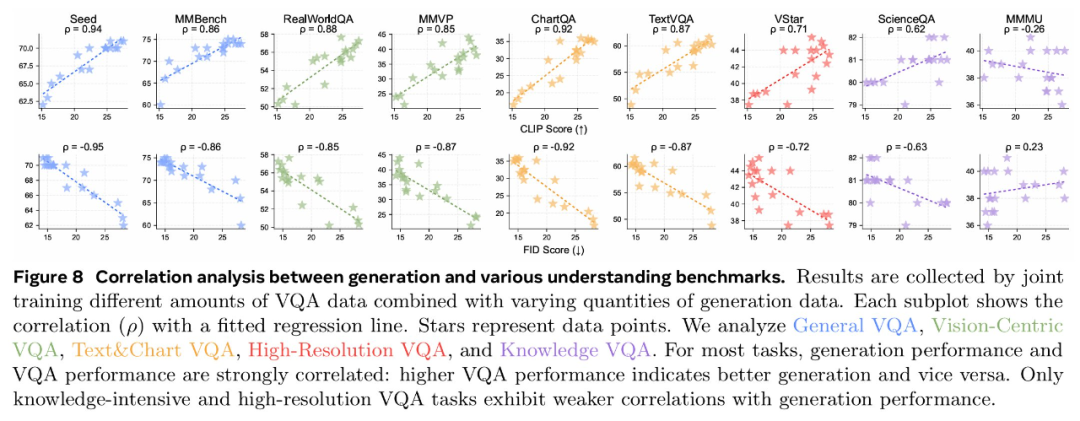
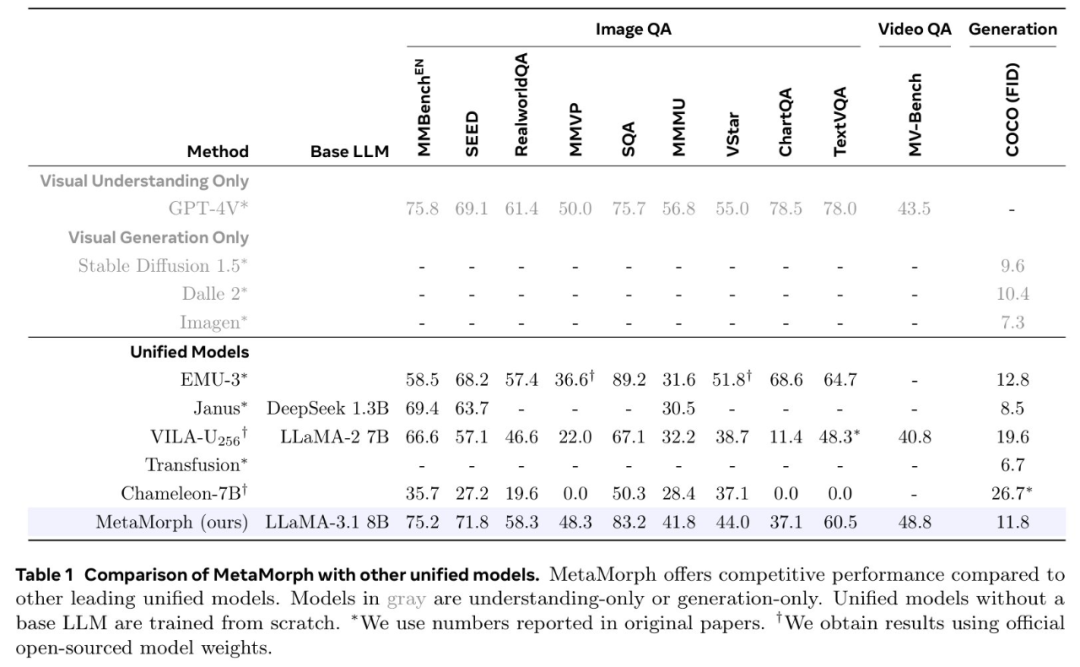
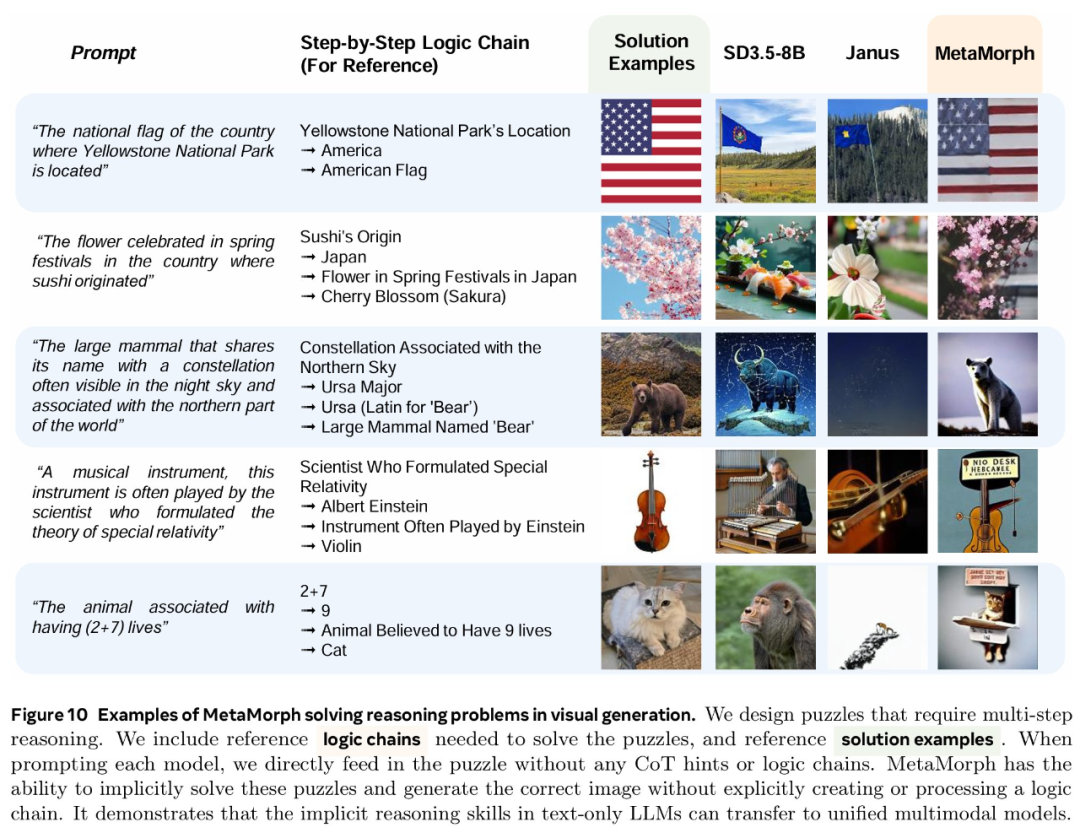
论文标题:MetaMorph: Multimodal Understanding and Generation via Instruction Tuning论文地址:https://arxiv.org/pdf/2412.14164v1项目地址:https://tsb0601.github.io/metamorph/作者之一 Peter Tong 表示:「这个项目确实改变了我对多模态模型和 LLM 的看法。我过去认为多模态(视觉)预测需要对模型进行重大更改和大量预训练,例如 Chameleon。但令人惊讶的是,事实恰恰相反!在大型自回归模型中,视觉理解和生成紧密相关,可以直接从 LLM 进行指令调整。」当前,人们试图建立「统一」的模型,能够同时进行多模态理解和生成,这就通常将视觉生成视为与视觉理解正交的功能。这些模型往往需要对原始 MLLM 架构进行大量更改,并进行大量多模态预训练和 / 或微调。设计此类方法具有挑战性,以往研究采用了不同的方法,包括将视觉输入 tokenizing 为离散的 token、融入扩散目标以及将视觉解耦为单独的理解和生成模式。例如,LWM、Show-o 和 Chameleon 等方法需要数十亿个图文对以进行广泛的预训练和微调。在本文中,研究者提出了视觉预测指令调整(Visual-Predictive Instruction Tuning,VPiT),它是视觉指令调整的简单扩展,建立在将连续视觉 token 作为输入传递给 LLM 的现有范式之上。VPiT 训练 LLM 以在微调阶段输出连续视觉 token 和离散文本 token。该模型以预训练的视觉编码器嵌入以及文本 token 作为输入,并输出文本 token 和连续视觉 token 的组合。为了可视化生成的视觉 token,研究者还微调了一个扩散模型,将嵌入映射回像素空间(参见下图 1 中的示例)。这个框架使得能够研究视觉理解、视觉生成和预训练 LLM 之间的协同作用,从而得出以下几个有趣的发现。首先,研究者表明,预测视觉 token 的能力源于对视觉输入的理解,并且只需要极少的额外训练。与视觉指令调整类似,VPiT 可以高效地将 LLM 转变为一个可以理解和生成多模态 token 的「统一」模型。当使用足够的视觉理解数据进行联合训练时,此过程只需要 200k 额外的视觉生成数据。研究者进一步确定,理解和生成视觉 token 的能力具有内在联系且不对称。具体来讲,增加理解数据可以提高视觉理解(更高的 VQA 分数)和生成性能(更低的 FID 分数)。相反,增加生成数据可以提高生成质量,也有助于增强视觉理解,但程度较小。重要的是,研究结果强调了每种能力的训练对模型整体视觉性能具有不对称的影响:在提高视觉理解和生成方面,以理解为中心的训练大大优于以生成为中心的训练。基于这些发现,研究者训练了一个名为 MetaMorph 的统一模型,使用 VPiT 预测多模态 token。他们利用各种数据源,从常见的视觉问答数据集到无文本注释的纯图像和视频数据。结果显示,MetaMorph 在视觉理解和视觉生成基准上都取得了有竞争力的表现。此外,研究者展示了这种统一的建模方法允许模型利用 LLM 的强大功能,比如 MetaMorph 可以在生成视觉 token 从预训练的 LLM 中提取知识。更令人惊讶的是,他们还观察到 MetaMorph 可以在生成视觉 token 之前隐式地执行推理步骤。比如当输入提示词「帝王斑蝶幼虫转变形态后的动物」,MetaMorph 成功生成了一张蝴蝶的图像(图 1 右)。本文的结果表明了以下两点见解,为混合模态模型的开发提供了启发。LLM 具有强大的预先存在的视觉功能,与广泛的预训练相比,这些功能可以使用少得多的样本来激活。VPiT 是一种简单的设计,它扩展了现有的指令调整方法,以额外生成视觉 token,而不仅仅是文本。研究者使用相同的架构和 next-token 预测范式来解锁视觉生成功能,而无需花哨的东西。他们采用预训练的 LLM 并对其进行微调以预测离散文本 token 和连续视觉 token。这些视觉 token 可以使用经过调整的扩散模型来可视化。模型架构。研究者采用预训练 LLM,并对其进行微调,以处理任意的文本和视觉 token 序列。他们保留原始的 LLM 头(head)用于文本预测,并将单独的视觉头附加到 LLM 以预测视觉 token,即视觉编码器在处理图像时生成的输出 token。视觉头是一个映射层,从 LLM 的维数映射到视觉编码器的维数。然后以提示词 token 作为上下文,对所有响应 token 进行自回归训练和预测。与传统的视觉指令调整不同,在 VPiT 中,视觉 token 也是 LLM 的输出,而不仅仅是输入。为了让 LLM 意识到视觉 token 的存在,研究者引入特殊 token( 〈image_start〉 和 〈image_end〉 )来指示视觉 token 序列的边界以及何时使用视觉头。损失函数。语言头输出词汇表的概率分布,并使用交叉熵损失进行训练以进行下一个 token 预测。视觉预测使用了「 LLM 预测的视觉 token 与视觉编码器的视觉 token 之间」的余弦相似性损失。与指令调整实践一致,该模型仅对响应 token 进行预测并产生损失。由于 VPiT 使模型能够预测其响应中的文本和视觉 token,因此它允许使用更广泛的训练数据。另一方面,传统的视觉指令调整主要依赖于问答对。本文的大部分数据集都是公开的,研究者将它们分为以下三个主要类别:视觉理解数据:包括以图像或视频作为输入并输出文本响应的数据。视觉生成数据:MetaCLIP 数据,根据图像描述预测视觉 token。研究者最多使用 500 万对,并将数据整理成问答格式。其他视觉数据:包括需要模型根据「交错输入的视觉 token 和文本 token」来预测视觉 token 的数据。由于使用 VPiT 训练的模型学习预测连续的视觉 token,因此需要将预测的 token 映射回像素空间。研究者利用了「扩散自编码器」的概念,其中扩散模型可以适应图像嵌入而不是文本嵌入的条件。具体地,他们使用 held-out 训练数据微调现有的扩散模型以适应视觉编码器的输出。在推理时,如果生成了标签 token 〈image_start〉,则模型开始输出视觉 token,直到 〈image_end〉。然后将生成的视觉 token 插入扩散模型以在像素空间中可视化预测。研究者使用了标准的潜在扩散模型训练流程。在 VPiT 框架下,研究者探究了有关视觉理解与生成影响与协同作用的问题:视觉生成可以通过轻量级调整来解锁吗?还是需要大量数据?视觉理解和生成是互惠互利还是相互对立?更多的视觉理解或生成数据对理解和生成质量的贡献有多大?在评估时,研究者使用了 9 个 ImageQA 基准来评估模型的不同方面,包括 MMBench、Seed、VStar、MMVP、MMMU、ChartQA、TextVQA、ScienceQA、RealWorldQA。研究者首先调研了教(teach)语言模型生成高质量视觉 token 所需的图文样本数量。为此,他们从生成数据(MetaCLIP 数据集)中随机抽取 {1k、5k、10k、50k、200k、1M、3M、5M} 个图文对。同时探索了两种设置:1 仅使用视觉生成数据对 LLM 进行微调,2)使用视觉理解和其他类型的数据来联合训练视觉生成。在下图 2 中,研究者发现仅对视觉生成进行训练的表现明显差于使用所有其他数据的联合训练。在超过 300 万个图文对的情况下,模型很难生成高质量的视觉图像(∼40 FID 分数),并且性能仍然不如使用 500 万个图文对进行联合训练的情况。这表明仅对视觉生成数据进行训练的样本效率明显较低。相比之下,与其他数据集联合训练可以显著提高生成性能。模型仅使用 5k 生成数据即可生成有效的视觉 token,性能在 200k 样本左右可以保持稳定。这表明视觉生成不是一种正交能力,而是一种受益于其他任务并在联合训练中更有效出现的能力。为了更好地理解每种类型的数据如何有助于视觉生成,研究者使用 200k 视觉生成数据进行了一项可控实验,使用前文展示的每种类型数据进行单独联合训练。他们还将单独训练与一起训练所有数据进行了比较。下图 3 中展示了结果。结果表明,虽然所有数据类型都增强了模型视觉生成能力,但改进程度各不相同。即使生成数据量保持在 200k 不变,ImageQA 和 VideoQA 等视觉理解数据也能显著提升模型视觉生成能力。这表明理解视觉内容的能力与生成视觉 token 之间存在很强的联系。此外,在训练中结合所有数据类型可以进一步提高性能,这表明不同数据类型带来的好处可以叠加。发现 1:当模型与视觉理解数据联合训练时,与仅在生成数据上进行训练相比,可以使用明显更少的生成数据来解锁生成视觉 token 的能力。更多的理解数据可以带来更好的理解和生成性能。基于上文发现,研究者进行了一项对照实验,以研究视觉理解能力与视觉生成能力之间的关系。他们使用一组固定的 200k 生成数据来进行模型消融,同时利用 Cambrian-7M 的 1M 到 7M 样本的 VQA 数据变化来开发不同级别的视觉理解。下图 4 中显示的结果表明,更强的 VQA 能力与更好的生成性能具有相关性。更多的生成数据同样可以带来更好的理解和生成性能。研究者探索了视觉生成能力的提高是否也与更高的 VQA 性能有关,为此他们使用固定的 1M VQA 样本作为理解基线进行了一项对照实验。然后改变生成数据的数量({200k、500k、1M、2M、3M、4M})以调整生成能力,同时与固定的 1M VQA 数据进行联合训练。下图 5 的结果显示,在 1M VQA 设置中,更强的生成能力与 VQA 性能的提升相关。这意味着增加生成数据量不仅可以增强生成能力,而且还会对 VQA 性能产生积极影响。这种协同作用可以扩展到不同的 LLM。研究者探究研究结果是否可以迁移到不同的 LLM 主干。通过使用 7M VQA 样本和 1M 生成数据的组合,他们在 LLaMA-3 8B、LLaMA-3.1 8B 和 LLaMA-3 70B 上训练 VPiT。下图 6 显示了不同 LLM 之间的扩展行为。发现 2:视觉理解和视觉生成相辅相成,增加任意一项任务的数据都会同时增强两者的性能。研究者调研了理解与生成数据是否同等重要,他们联合训练了不同规模的 VQA 数据(f1M、4M、7M)和生成数据(200k、500k、1M、2M、3M、4M)。下图 7 总结了这些发现,其中 x 轴表示 VQA 数据,y 轴表示生成数据。结果通过热图可视化,其中较深的颜色代表更好的性能。结果表明,增加 VQA 数据可以在所有三个指标中产生最显著的改进。当 VQA 数据较低(1M)时,随着 VQA 数据的扩大(从 1M 到 4M 再到 7M),生成数据的增加会带来显著的改进。不过,VQA 数据的影响更加明显,热图中急剧的颜色过渡证明了这一点。最终,对于 7M VQA 数据,生成数据的增加贡献很小。这些结果证明了理解数据在增强理解和生成性能方面具有关键作用。发现 3:虽然增加数据可以提升整体性能,但视觉理解数据的影响明显高于视觉生成数据的影响。鉴于 OCR、以视觉为中心的任务和基于知识的任务等理解任务的多样性,论文研究了哪些任务与生成能力的相关性最强。受 Cambrian-1 的启发,研究者将 VQA 任务分为五组:一般、文本和图表、高分辨率、知识和以视觉为中心的 VQA。研究者利用早先的实验结果,用不同数量的生成数据联合训练各种 VQA 数据规模,并在图 8 中绘制了每个基准的 VQA 性能与生成性能的对比图。他们还计算了 VQA 分数与 FID/CLIP 分数之间的皮尔逊相关性 (ρ)。图 8 显示,通用、视觉中心和文本与图表 VQA 任务与生成性能密切相关,每个任务的皮尔逊相关系数(p)都高于 0.85。高分辨率 VQA 表现出中等程度的相关性,p 约为 0.7。相比之下,知识 VQA 任务(如 MMMU)的相关性较弱,这表明生成能力与生成性能的相关性更为密切。这与模型的视觉能力有关,而与知识特定任务无关。发现 4:通用、视觉中心和文本理解的 VQA 任务与视觉生成有很强的相关性,而基于知识的 VQA 任务则没有。研究者将 MetaMorph 与其他统一模型进行了比较,并在表 1 中总结了结果。MetaMorph 利用 LLM 知识进行视觉生成MetaMorph 能有效利用预训练的 LLM 中蕴含的世界知识,图 9 左侧展示了一些例子。研究者去提示模型生成需要非难和专业化知识的概念,例子包括 Chhogori(世界第二高峰)、Oncilla(南美洲的一种小野猫)和 Chizarira(津巴布韦一个与世隔绝的荒野地区)。MetaMorph 成功地将特定领域的知识转化为准确的视觉 token,从而展示了从 LLM 中利用世界知识的能力。与此相反,最新的文本到图像(T2I)模型 StableDiffusion-3.5 8B,尽管生成了高质量的图像,却很难生成正确的概念。这个问题可能源于它所使用的文本嵌入模型 CLIP 和 T5,它们未能正确编码这些专业术语。图 9 右侧展示了 MetaMorph 如何比 CLIP 和 T5 等文本嵌入模型更有效地处理常见的语义难题。这些挑战包括否定和主观性,MetaMorph 使用了在 Multimon 中识别出的常见失败模式的提示来区分语义的细微差别,如「稍微」与「非常」、「少数」与「许多」、「没有」与「有」,这些都是现有文本到图像系统中常见的失败。图 10 中,研究者展示了模型根据谜题提示生成图像的例子,例如「国家公园位于」。在每道谜题中,都直接使用了「黄石公园所在国家的国家公园」这一提示语,而没有使用任何思维链(CoT)提示语「生成谜题图片」。MetaMorph 可以从需要多步推理的提示中生成正确的图像。例如,在回答「一种乐器,这种乐器通常由 theity 演奏」这一问题时,该模型需要隐式地完成三个推理科学家是谁提出了狭义相对论的步骤:识别出爱因斯坦是提出狭义相对论的科学家;识别出爱因斯坦的首选乐器是小提琴,并直接生成正确的视觉 token;然后完成推理过程。这一结果意味着,MetaMorph 在紧接着提示的生成过程中,隐式地明确分离了这些步骤。这些结果解决了谜题,并生成了正确的视觉 token,与《LLMs 物理学》的研究结果一致,作者认为 LLM 可以生成后续 token。在这里,研究者展示了在自回归之前预先计算推理图的能力,即使在解码视觉 token 时,这种能力也能转移到统一多模态模型设置中。以上就是统一视觉理解与生成,MetaMorph模型问世,LeCun、谢赛宁、刘壮等参与的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/781971.html






 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















