
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

作者 | 康奈尔大学杜沅岂
编辑 | ScienceAI
随着 AI for Science 受到越来越多的关注,人们更加关心 AI 如何解决一系列科学问题并且可以被成功借鉴到其他相近的领域。
AI 与小分子药物发现是其中一个非常有代表性和很早被探索的领域。分子发现是一个非常困难的组合优化问题(由于分子结构的离散性)并且搜索空间非常庞大与崎岖,同时验证搜索到的分子属性又十分困难,通常需要昂贵的实验,至少是至少是模拟计算、量子化学的方法来提供反馈。
随着机器学习的高速发展和得益于早期的探索(包括构建了简单可用的优化目标与效果衡量方法),大量的算法被研发,包括组合优化,搜索,采样算法(遗传算法、蒙特卡洛树搜索、强化学习、生成流模型/GFlowNet,马尔可夫链蒙特卡洛等),与连续优化算法,贝叶斯优化,基于梯度的优化等。同时现有较为完备的算法衡量基准,比较客观公平的比较方式,也为开发机器学习算法开拓了广阔的空间。
近日,康奈尔大学、剑桥大学和洛桑联邦理工学院(EPFL)的研究人员在《Nature Machine Intelligence》发表了题为《Machine learning-aided generative molecular design》的综述文章。

 新CG儿
新CG儿
数字视觉分享平台 | AE模板_视频素材
 412 查看详情
412 查看详情 
论文链接:https://www.nature.com/articles/s42256-024-00843-5
该综述回顾了机器学习在生成式分子设计中的应用。药物发现和开发需要优化分子以满足特定的理化性质和生物活性。然而,由于搜索空间巨大和优化函数不连续,传统方法既昂贵又容易失败。机器学习通过结合分子生成和筛选步骤,进而加速早期药物发现过程。
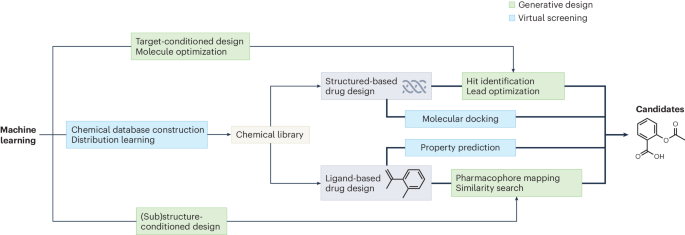
图示:生成式 ML 辅助分子设计流程。
生成性分子设计任务
生成性分子设计可以分为两大范式:分布学习和目标导向生成,其中目标导向生成可以进一步分为条件生成和分子优化。每种方法的适用性取决于具体任务和所涉及的数据。
分布学习 (distribution learning)
分布学习旨在通过对给定数据集分子的概率分布建模来描述数据的分布,从而从学习到的分布中采样新分子 。
条件生成 (conditional generation)
属性条件生成 (property-conditioned generation):生成具有特定属性的结构,可以为一个文字的描述,或者一个具体属性的数值 。分子子结构条件生成(molecular (sub)structure-conditioned generation):生成具有特定结构约束的分子,例如设计部分结构、支架跳跃、连接子设计、重新设计整个结构(先导优化)或整个分子的条件生成(构象生成)。目标条件生成 (target-conditioned generation):旨在生成对特定疾病相关生物分子靶点具有高结合亲和力的分子。与属性条件生成不同,目标条件生成利用对靶点结构的显式访问,通过整合直接的靶点-配体相互作用来提高配体分子与靶点的亲和力 。表型条件生成 (phenotype-conditioned generation):涉及从基于细胞的显微镜或其他生物检测读数(如转录组数据)中学习表型指纹,以提供条件信号,指导生成朝向理想的生物学结果的分子。
分子优化 (molecule optimization)
分子优化在药物发现中起着关键作用,通过细化药物候选者的属性来提高其安全性、有效性和药代动力学特性。涉及对候选分子结构进行小的修改,以优化药物性质,如溶解度、生物利用度和靶点亲和力,从而提高治疗潜力并增加临床终点的成功率 。

图示:生成任务、生成策略和分子表征的图示。
分子生成流程
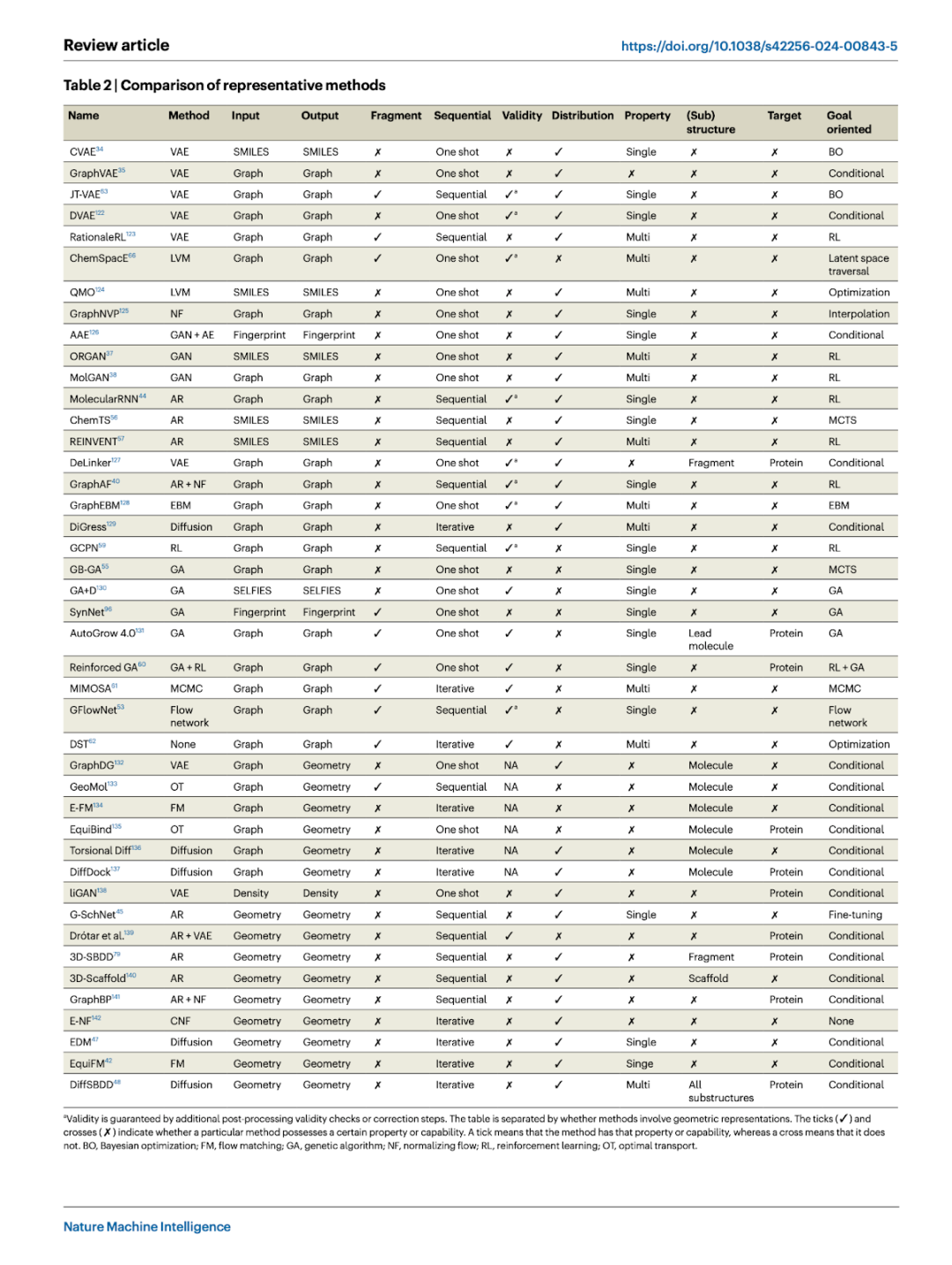
分子生成是一个复杂的流程包括许多不同的组合单元,我们在下图中列出了代表性的工作,并且介绍每一个部分的代表性单元。
分子表示
在开发分子生成的神经架构时,首先要确定分子结构的机器可读输入和输出表示。输入表示有助于将适当的归纳偏差注入模型,而输出表示则确定了分子的优化搜索空间。表示类型决定了生成方法的适用性,例如,离散搜索算法只能应用于图和字符串等组合表示。
虽然已经研究了各种输入表示,但对表示类型和编码它们的神经架构的权衡还不明确。分子之间的表示转换并不一定是双射的,例如,密度图和指纹无法唯一识别分子,需要进一步的技术来解决这一非平凡的映射问题。常见的分子表示包括字符串、二维拓扑图和三维几何图 。
基于字符串的分子结构:通常编码为字符串,如简化的分子输入线条输入系统(SMILES)或自引用嵌入字符串(SELFIES)。SMILES 用语法规则表示分子,但字符串可能无效;SELFIES 通过修改这些规则确定了分子的有效性。分子字符串通常通过递归网络和 Transformer 模型编码为序列数据 。基于拓扑和几何图的原子和键:通常在拓扑图中表示为节点和边。图神经网络(GNNs)常用于建模图结构分子数据,基于相邻节点更新节点和边特征。在三维信息可用且相关时,几何 GNNs 常用于捕捉三维空间中的应用相关对称性,如平移和旋转不变性或等变性 。
表示粒度是生成模型设计中的另一个考虑因素。通常,方法利用原子或分子片段作为生成期间的基本组成单元。基于片段的表示将分子结构细化为包含原子组的较大单元,携带层次信息,如官能团标识,从而与传统的基于片段或药效团药物设计方法对齐 。
生成方法
深度生成模型是一类估计数据概率分布并从学习分布中抽样的方法(也称为分布学习)。其中包括变分自编码器,生成对抗网络,正则化流 (normalizing flows),自回归模型,扩散模型。这些生成方法中的每一种都有其适用的情境和优缺点,具体的选择取决于所需任务和数据特征。
生成策略
生成策略指模型输出分子结构的方式,一般可以分为一次性生成、顺序生成或迭代改进 。
一次性生成:一次性生成在模型的单次前向传递中生成完整的分子结构。这种方法通常难以生成具有高精度的真实和合理的分子结构。此外,一次性生成通常不能满足显式约束,如价态约束,这对于确保生成结构的准确性和有效性至关重要。
顺序生成:顺序生成通过一系列步骤构建分子结构,通常按原子或片段进行。顺序生成中容易注入价态约束,从而提高生成分子的质量。然而,顺序生成的主要限制是需要在训练期间定义生成轨迹的顺序,并且推理速度较慢。
迭代改进:迭代改进通过预测一系列更新来调整预测,避开一次性生成方法中的难点。例如,AlphaFold2 中的循环结构模块成功地将骨架框架精细化,这种方法启发了相关的分子生成策略。扩散模型是一个常见技术,通过一系列降噪步骤生成新数据。目前,扩散模型已应用于多种分子生成问题,包括构象生成、基于结构的药物设计和连接子设计。
优化策略
组合优化:对于分子(如图或字符串)的组合编码,可以直接应用组合优化领域的技术 。
连续优化:分子可以在连续域中表示或编码,例如在欧几里得空间中的点云和几何图,或在连续潜在空间中编码离散数据的深度生成模型 。
生成性机器学习模型的评估
评估生成模型需要计算评价和实验验证。标准指标包括有效性、独特性、新颖性等。评估模型时应综合考虑多个指标,以全面评估生成性能。
实验验证
生成的分子必须通过湿法实验来进行明确的验证,这与现有研究主要关注计算贡献形成鲜明对比。虽然生成模型并非没有弱点,但预测与实验之间的脱节也归因于进行此类验证所需的专业知识、昂贵的费用、以及漫长的测试周期。


生成模型规律
大多数报告实验验证的研究使用 RNN 和/或 VAE,并以 SMILES 作为操作对象。我们总结了四个主要观察点:
SMILES 虽然捕捉到的 3D 信息有限,但作为一种高效的表示方式,适用于分布学习和小数据集的微调。许多实验验证的研究目标是激酶,这是 ChEMBL 等流行开源数据集中的常见靶点。绝大多数目标导向的方法使用强化学习(单独或作为组件)作为优化算法,包括基于配体和基于结构的药物设计。AlphaFold 预测的结构可以成功用于生成结构的药物设计。
未来方向
尽管机器学习算法为小分子药物发现带来了曙光,但是还有更多的挑战与机遇需要面对。
挑战
分布外生成:已知化学物质只占化学空间的一小部分。虽然深度生成模型可以提出训练分布之外的分子,但需要确保其合理性。不现实的问题表述:精确的问题表述对于开发适用于现实世界药物发现的模型至关重要。常常忽略的基本方面包括构象动态、水的作用和熵贡献,而诸如无限访问 oracle 调用的假设也常被错误地认为是理所当然的。这包含了样本效率问题,最近的研究在有限 oracle 预算下的高效目标导向生成方面取得了进展。低保真 oracle:在药物发现相关维度上有效评分设计仍然困难,成为工业环境中部署生成模型的瓶颈。例如,高通量结合亲和力预测在数据驱动和基于物理的工作流中通常不准确。虽然存在替代的高精度 oracle,但其计算需求限制了可扩展性。此外,高质量标注数据的不可获取性也成为开发具有高精度和可管理 AI oracle 的障碍。缺乏统一的评估协议:用于评估药物候选物质量的评估协议与我们定义何为良好药物的标准密切相关。ML 社区通常使用的易于计算的物理化学描述符存在疑问,肯定无法全面反映性能。在生成分子设计与虚拟筛选之间进行严格比较也较少见。缺乏大规模研究和基准测试:许多ML方法已经开发出来,但在许多关键任务中的不同模型类型上没有公平的基准测试结果。例如,仅使用了可用数据的一小部分进行训练,限制了对模型可扩展性的理解。最近的基准测试对标准化计算评估协议的重要贡献。缺乏可解释性:可解释性是分子生成模型中一个重要但未充分探索的领域。例如,洞察生成或优化过程如何构建分子可以产生化学规则,这对药物化学家具有解释性。这在小分子领域尤其重要,因为生成模型通常用于向药物化学家提交想法,合成障碍排除了测试所有生成设计的可能性。
机会
超越小分子设计的应用:这里讨论的方法可能在设计其他复杂结构材料(如多糖、蛋白质(特别是抗体)、核酸、晶体结构和聚合物)方面有更广泛的应用。大语言模型展示了通过文本指导的发现和决策作为代理来革新分子设计的潜力,这得益于大量可用的训练数据,包括科学文献。此外,针对分子结构进行定制或微调的模型为研究人员提供了利用自然语言处理中的成熟进展的额外机会。药物开发的后期阶段:分子设计/优化占据了药物发现的早期阶段。然而,由于有限的疗效、较差的 ADME/T(吸收、分布、新陈代谢、排泄和毒性)特性和安全问题导致的晚期失败是药物开发管道中的痛点。尽管有限,但将临床数据集成到设计管道中是提高下游成功率的一个有希望的方向。聚焦模型目的:药物发现管道是制药公司多年经验和艰难教训的结果。ML 研究人员应该不仅仅设计纯粹的从头设计模型(特别是在缺乏深度表征能力时),还应设计聚焦于在多年过程中的特定步骤上改进的模型,符合现实约束。自动化实验室:对高通量实验的需求不断增加,以为 ML 设计的分子提供反馈,将越来越多的注意力集中在自动化实验室上,以加快设计–制造–测试–分析循环。
作者: 杜沅岂,康奈尔大学计算机系二年级博士生,主要研究兴趣,几何深度学习,概率模型,采样,搜索,优化问题,可解释性,与在分子探索领域的应用,具体信息见:https://yuanqidu.github.io/。
以上就是AI小分子药物发现的「百科全书」,康奈尔、剑桥、EPFL等研究者综述登Nature子刊的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/793678.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















