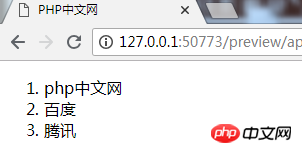
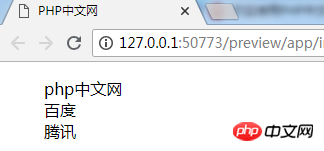
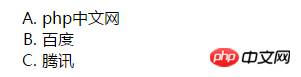效果更稳定,实现更简单。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜



 小艺
小艺
华为公司推出的AI智能助手
 549 查看详情
549 查看详情 

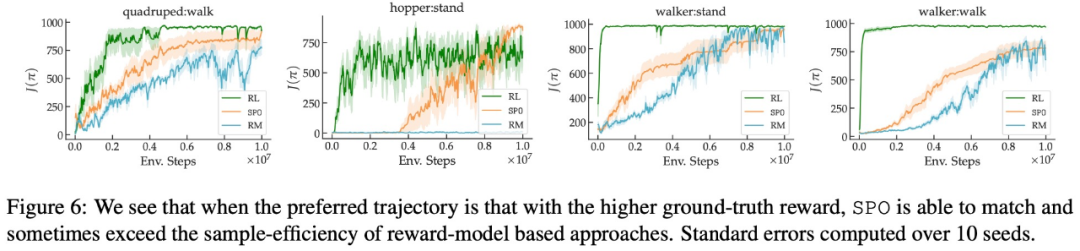
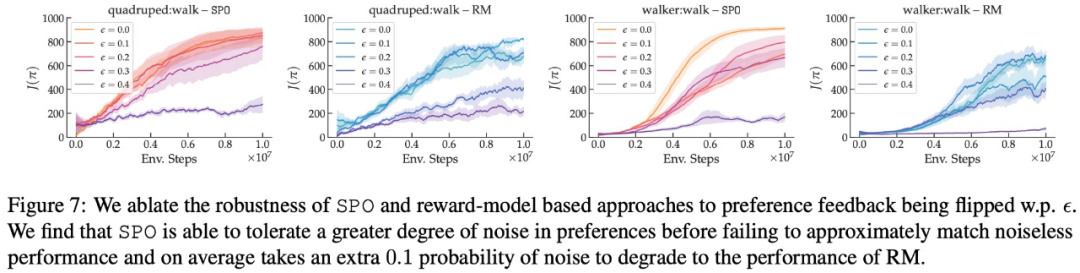
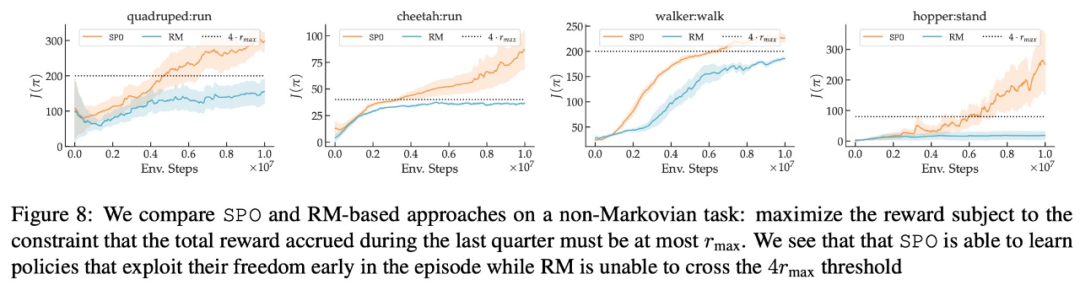
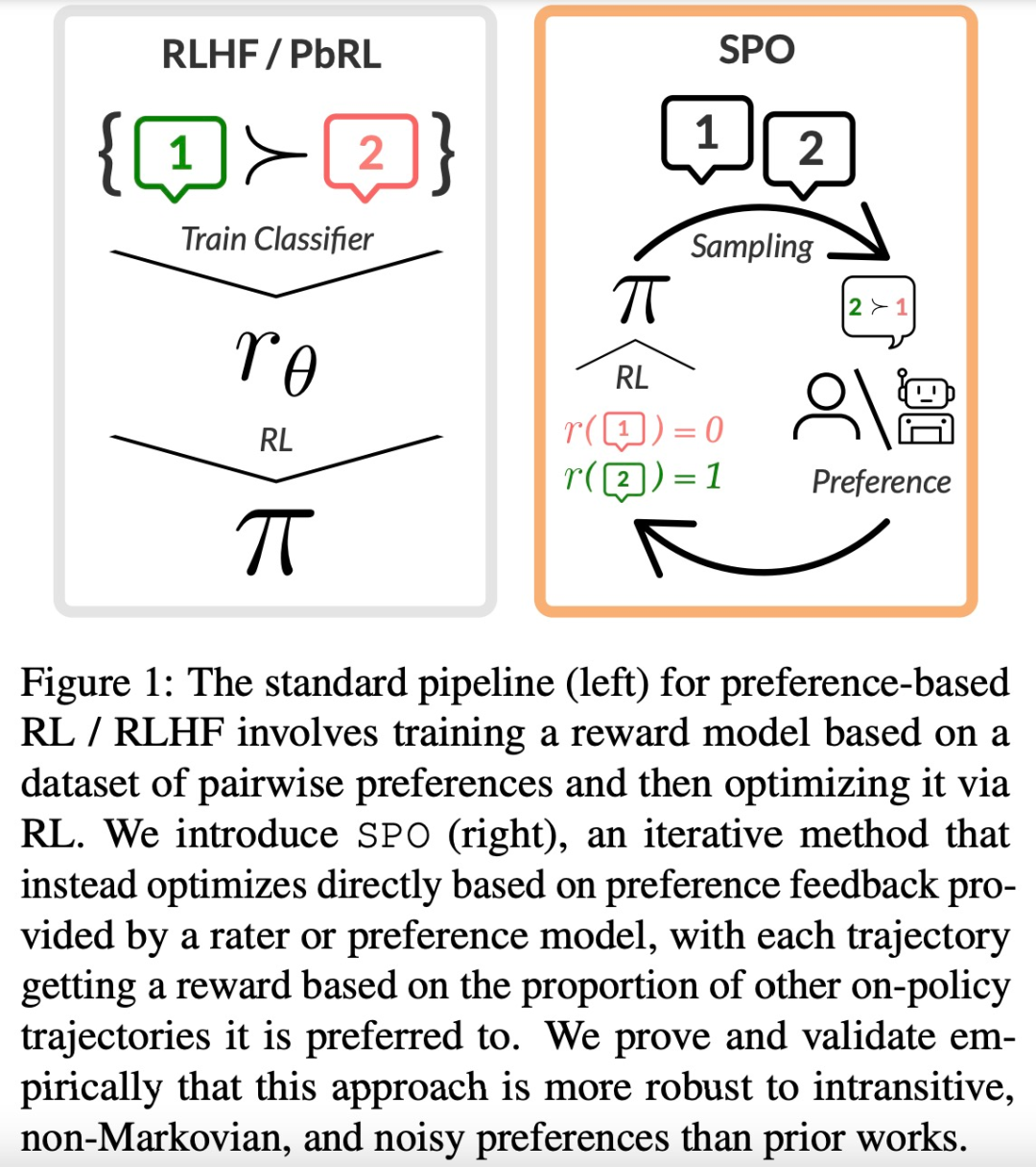
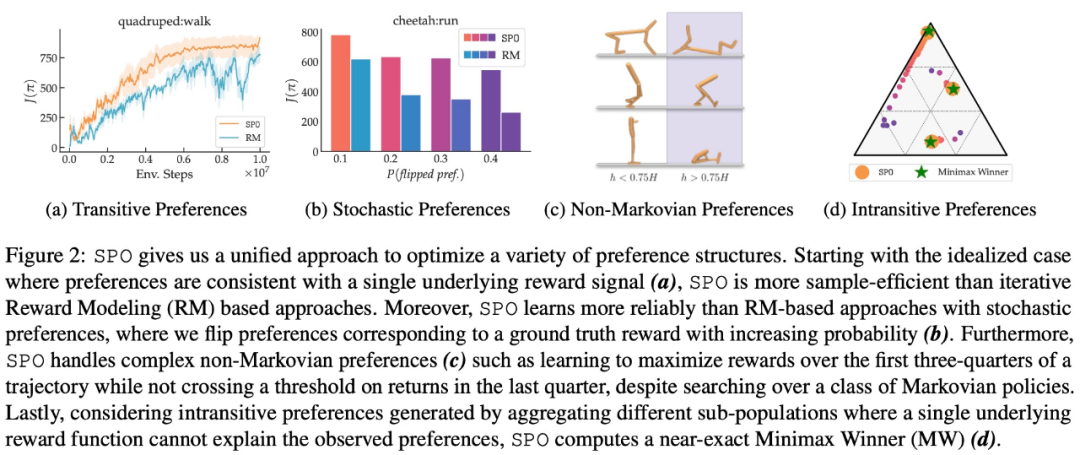
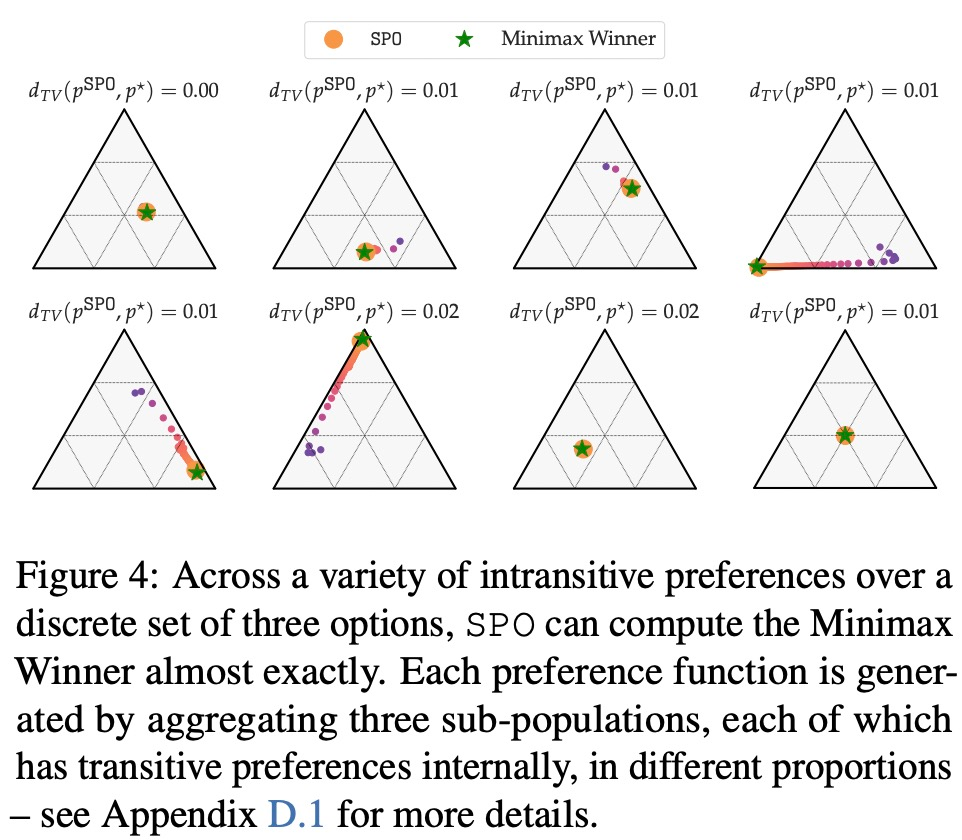
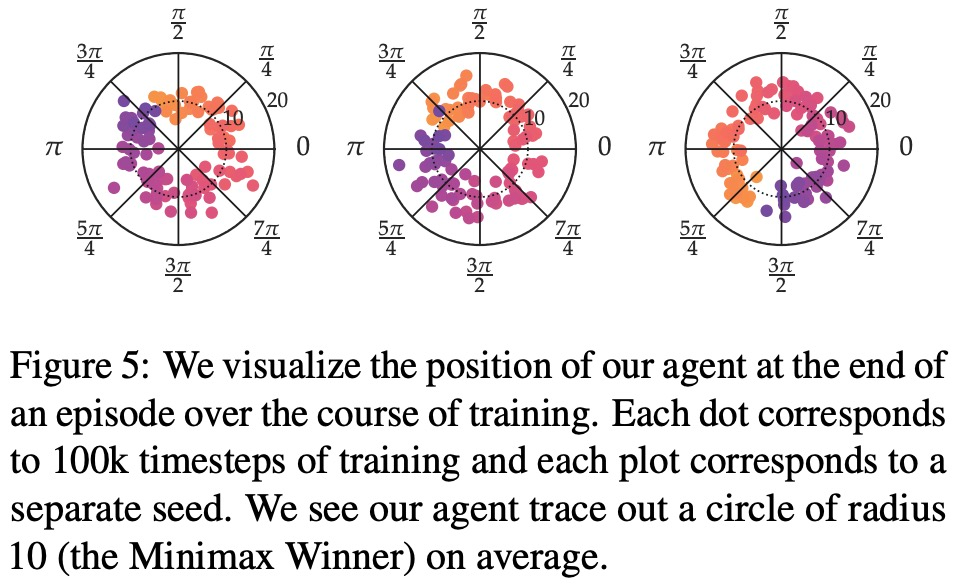
以上就是谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/799102.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫