spo
-
谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练

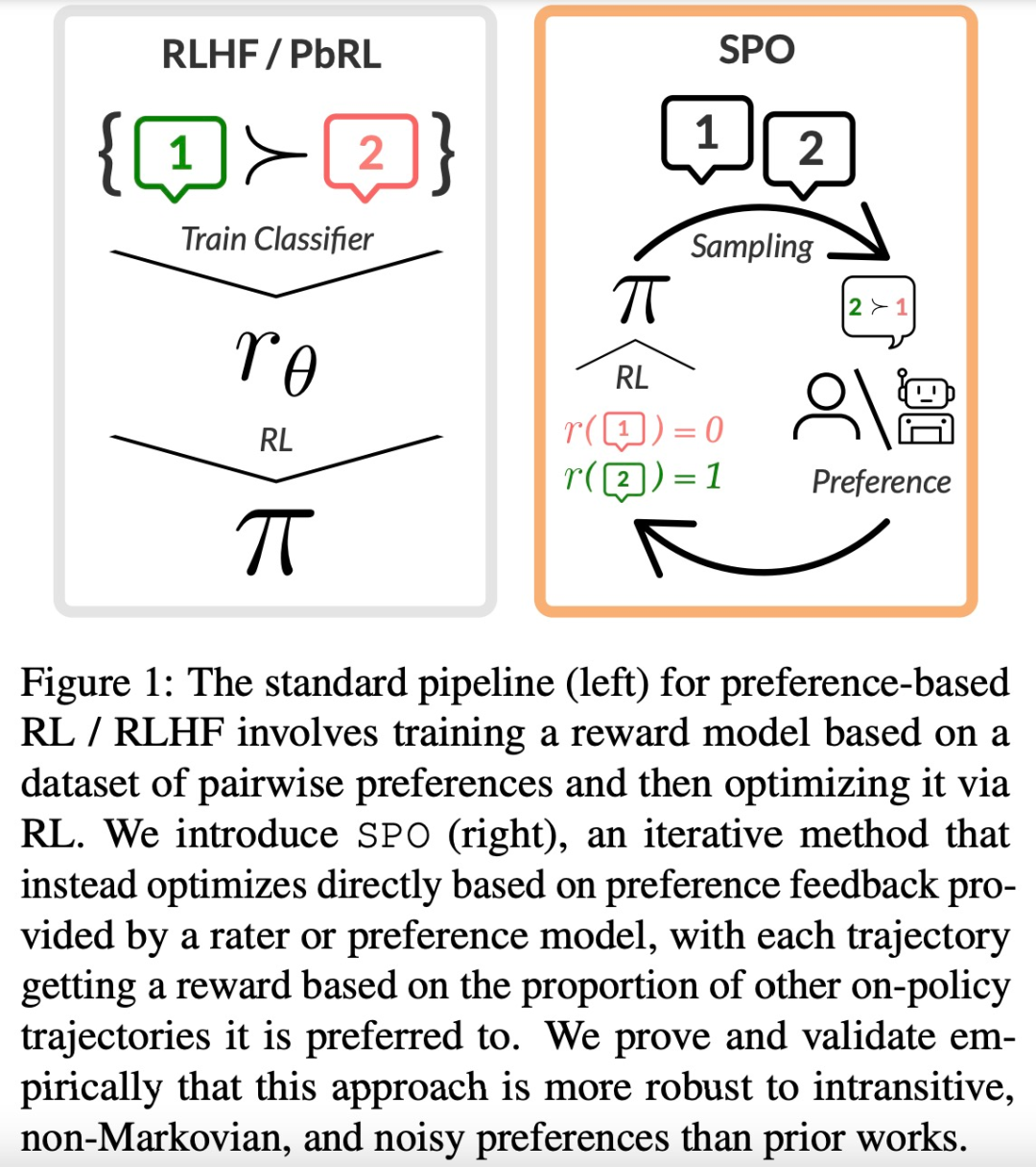


效果更稳定,实现更简单。 大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。然后通过某种强化学习算法优化这个奖励函数。然而,奖励模型的关键要素可能会产生一…

效果更稳定,实现更简单。 大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。然后通过某种强化学习算法优化这个奖励函数。然而,奖励模型的关键要素可能会产生一…
