

本文介绍如何在Linux系统上搭建Hadoop分布式文件系统(HDFS)来存储海量数据。HDFS通过将数据分散存储在集群中,实现高效的数据处理。 以下步骤详细阐述了在Linux环境下配置和使用HDFS的过程:
一、准备工作:安装Java环境
首先,确保你的系统已安装Java Development Kit (JDK)。 可以使用以下命令检查:
java -version若未安装,使用以下命令安装OpenJDK 8 (根据你的系统版本选择合适的JDK版本):
sudo apt-get update # 更新软件包列表sudo apt-get install openjdk-8-jdk # 安装OpenJDK 8二、Hadoop安装与配置
下载Hadoop: 从Apache官网下载Hadoop最新稳定版本,并解压到指定目录 (例如 /usr/local/hadoop)。
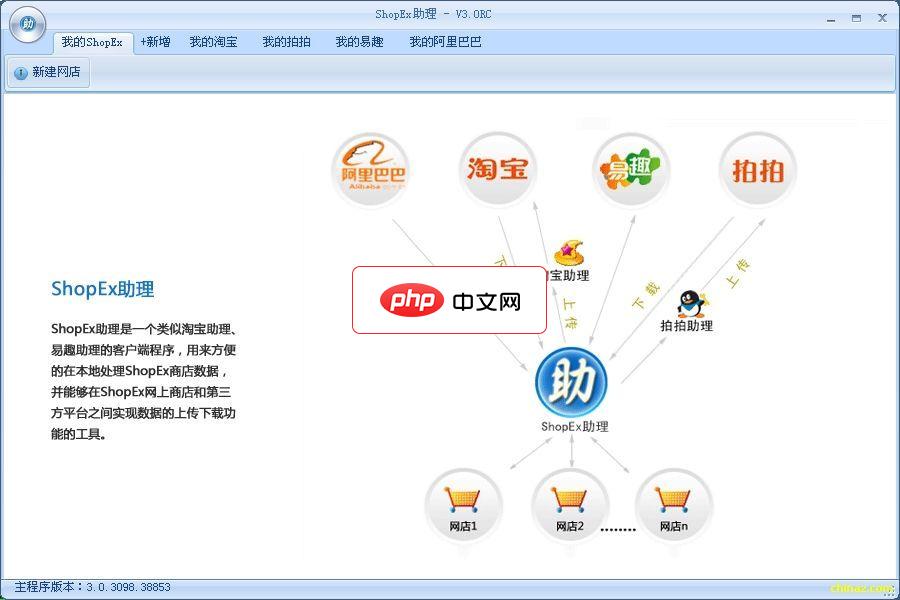 ShopEx助理
ShopEx助理
一个类似淘宝助理、ebay助理的客户端程序,用来方便的在本地处理商店数据,并能够在本地商店、网上商店和第三方平台之间实现数据上传下载功能的工具。功能说明如下:1.连接本地商店:您可以使用ShopEx助理连接一个本地安装的商店系统,这样就可以使用助理对本地商店的商品数据进行编辑等操作,并且数据也将存放在本地商店数据库中。默认是选择“本地未安装商店”,本地还未安
 0 查看详情
0 查看详情 
设置环境变量: 编辑 ~/.bashrc 文件,添加以下环境变量:
export HADOOP_HOME=/usr/local/hadoop # 将`/usr/local/hadoop`替换为你的Hadoop安装路径export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource ~/.bashrc # 使环境变量生效核心配置文件 (core-site.xml): 修改 $HADOOP_HOME/etc/hadoop/core-site.xml 文件,配置默认文件系统:
fs.defaultFS hdfs://localhost:9000 HDFS配置文件 (hdfs-site.xml): 修改 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 文件,设置数据副本数量 (这里设置为1,生产环境建议设置大于1):
dfs.replication 1 三、启动HDFS
格式化NameNode: 运行以下命令格式化NameNode,这将初始化HDFS文件系统:
hdfs namenode -format启动HDFS集群: 运行以下命令启动HDFS守护进程:
start-dfs.sh四、数据操作
HDFS将数据分割成块并存储在集群的不同节点上,并维护多个副本以保证数据可靠性。 使用 hdfs dfs 命令进行文件操作:
上传文件: hdfs dfs -put /local/path/file.txt /hdfs/path/ (将本地文件上传到HDFS)下载文件: hdfs dfs -get /hdfs/path/file.txt /local/path/ (将HDFS文件下载到本地)查看文件: hdfs dfs -ls /hdfs/path/ (列出HDFS目录下的文件)
通过以上步骤,你可以在Linux系统上成功搭建并使用HDFS进行数据存储和管理。 记住,生产环境中需要配置更多参数,例如数据块大小、副本数量等,以优化性能和可靠性。
以上就是HDFS在Linux系统中如何实现数据存储的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/840313.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



















