
智源研究院最新大模型评测结果显示,%ignore_a_1%大模型表现亮眼!在涵盖百余个国内外模型的综合评测中,豆包通用模型pro在主观评测中夺得大语言模型桂冠;多模态领域,豆包视觉理解模型、文生图模型和视频生成模型(梦p2.0 pro)均位列前二,展现了强大的多模态能力。
此次评测由FlagEval大模型评测平台联合十余家高校和机构共同完成。大语言模型主观评测侧重中文能力,多模态评测则考察图文理解、视觉知识、文字识别等能力。FlagEval大模型角斗场则通过用户投票反映模型用户体验。
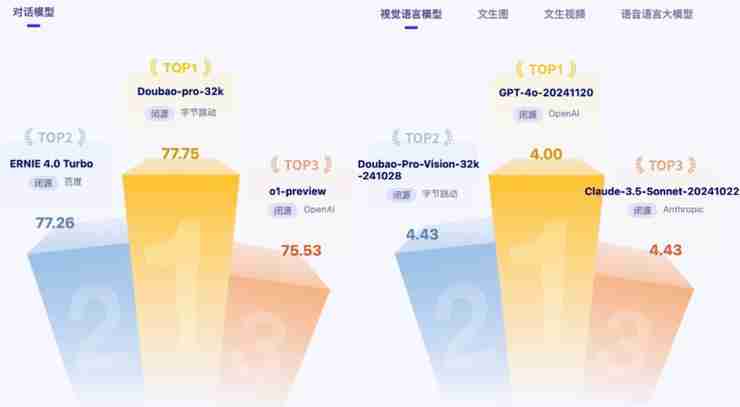
豆包通用模型Pro在主观评测中,知识运用和推理能力均获最高分,其他方面也表现优异,最终排名第一。在用户投票的角斗场榜单中,排名第二,仅次于OpenAI的o1-mini。
多模态评测中,豆包视觉理解模型紧随GPT-4o之后获得第二名,在中文通用知识和文字识别方面优势明显。文生图和文生视频测试中,国产模型表现突出,豆包和混元在文生图中名列前茅,梦P2.0 Pro等国产模型在文生视频中表现出色。
 腾讯混元文生视频
腾讯混元文生视频
腾讯发布的AI视频生成大模型技术
 266 查看详情
266 查看详情 
立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;
豆包视觉理解模型已向企业客户开放,火山引擎表示,豆包大模型通过技术创新降低了使用成本,致力于推动AI技术普惠。
以上就是智源评测出炉:豆包大语言模型排名第一,多模态能力获得三项第二的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/841906.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























