

Hadoop分布式文件系统(HDFS)本身并不是为实时数据处理设计的,它更适合于批量处理和存储大规模数据集。然而,可以通过结合其他工具和框架来实现实时数据处理。以下是几种常见的方法:
结合Apache Kafka:Kafka是一个分布式流处理平台,可以实现实时数据的高吞吐量和低延迟处理。可以将实时数据流发送到Kafka,然后使用Spark Streaming或Apache Flink等流处理框架来处理这些数据。
使用Apache Flink:Flink是另一种开源的流处理框架,可以实现高吞吐量和低延迟的实时数据处理。Flink可以与HDFS集成,实现快速响应的实时数据分析系统。
结合Spark Streaming:Spark Streaming是Spark的一个模块,用于处理实时数据流。通过Spark Streaming,可以监控HDFS上的目录,对新出现的文件进行实时处理。
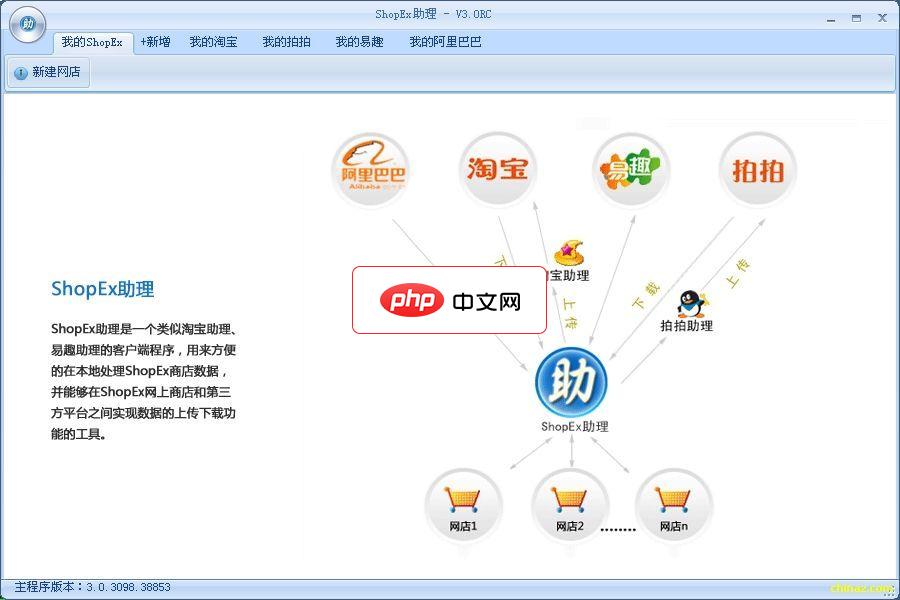 ShopEx助理
ShopEx助理
一个类似淘宝助理、ebay助理的客户端程序,用来方便的在本地处理商店数据,并能够在本地商店、网上商店和第三方平台之间实现数据上传下载功能的工具。功能说明如下:1.连接本地商店:您可以使用ShopEx助理连接一个本地安装的商店系统,这样就可以使用助理对本地商店的商品数据进行编辑等操作,并且数据也将存放在本地商店数据库中。默认是选择“本地未安装商店”,本地还未安
 0 查看详情
0 查看详情 
数据预处理和迭代优化:可以将实时计算框架与HDFS结合使用,实时计算框架用于对数据进行实时处理和分析,而HDFS用于存储大规模数据。实时计算框架可以从HDFS中读取数据,并将处理结果写回到HDFS中,从而实现实时反馈和迭代优化。
性能优化:为了提高HDFS的实时数据处理能力,可以通过优化配置参数、使用高速硬件、数据压缩等技术来提升性能。
虽然HDFS不是专门的实时数据处理系统,但通过与这些工具和框架的结合,可以在Linux环境下实现数据的实时处理和分析。具体的实现方案需要根据实际的业务需求和技术栈来选择和设计。
以上就是Linux HDFS如何实现实时数据处理的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/883820.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




















