
在 Windows 7 中启用休眠模式需要:确保您的计算机有足够内存(至少 1GB RAM)和一个休眠支持的硬盘驱动器或固态驱动器。单击“开始”按钮,搜索“电源选项”,并选择“选择电源按钮的功能”。选中“系统设置”窗口中“关机设置”部分的“休眠”复选框,然后单击“保存更改”。

如何在 Win7 中启用休眠模式
休眠模式是一种省电功能,它可以将计算机的状态保存到文件,然后关闭计算机。当计算机从休眠模式唤醒时,它将恢复到休眠时的状态。
要启用 Win7 中的休眠模式,请按照以下步骤操作:
步骤 1:检查系统要求
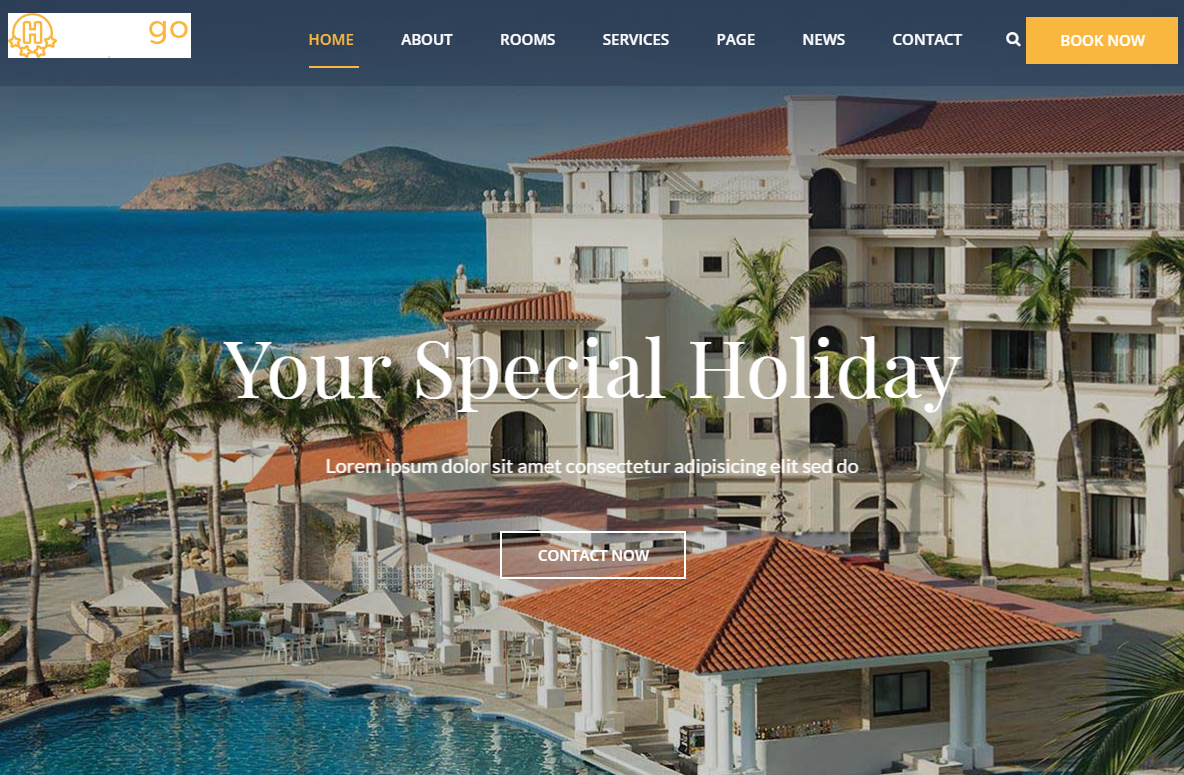 2019宽屏大气响应式高端休闲旅游度假酒店HTML5网站模板
2019宽屏大气响应式高端休闲旅游度假酒店HTML5网站模板
宽屏大气响应式高端休闲旅游度假酒店HTML5网站模板下载。一套基于bootstrap前端响应式框架开发的大气html5响应式旅游度假酒店预订平台网站模板,下载文件包含13张html网页模板,基本上包含了酒店预订平台官网所需要用到的页面模板,详见在线演示。使用最新HTML5+CSS3技术,采用响应式布局设计,自适应手机移动端,用户体验友好。
 497 查看详情
497 查看详情  确保您的计算机有足够的内存 (RAM)。建议至少有 1GB 的 RAM。确保您的计算机具有休眠支持的硬盘驱动器或固态驱动器。
确保您的计算机有足够的内存 (RAM)。建议至少有 1GB 的 RAM。确保您的计算机具有休眠支持的硬盘驱动器或固态驱动器。
步骤 2:启用休眠模式
单击“开始”按钮。在搜索框中,键入“电源选项”并单击“Enter”键。在“电源选项”窗口中,单击左侧菜单中的“选择电源按钮的功能”。在“系统设置”窗口中,找到“关机设置”部分。选中“休眠”复选框。单击“保存更改”按钮。
步骤 3:使用休眠模式
启用休眠模式后,您可以使用以下方法之一将其置于休眠状态:
单击“开始”按钮,然后单击“关机”按钮。选择“休眠”选项。按下键盘上的 Windows 徽标键 + X 组合键。选择“关机或注销” > “休眠”。单击系统托盘中电池图标。选择“休眠”。
以上就是win7休眠模式在哪的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/908785.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















