
阿里通义qwen团队近日发布了其最新的旗舰级多语言、多音色文本转语音模型——qwen3-tts-flash。该模型不仅支持多种语言和音色输出,还覆盖了包括普通话及闽南语、吴语、粤语、四川话、北京话、南京话、天津话、陕西话在内的9种汉语方言,展现出强大的语言适应能力。
在性能表现上,Qwen3-TTS-Flash已在seed-tts-eval与MiniMax多语测试集中展现出卓越的语音稳定性与音色相似度,达到当前最先进的SOTA水平。同时,官方已同步推出API接口、在线Demo以及多段音频样例,方便开发者和用户快速体验。
据团队介绍,Qwen3-TTS-Flash在语音质量和一致性方面经过全面评测,在多项关键指标上均优于现有主流模型。
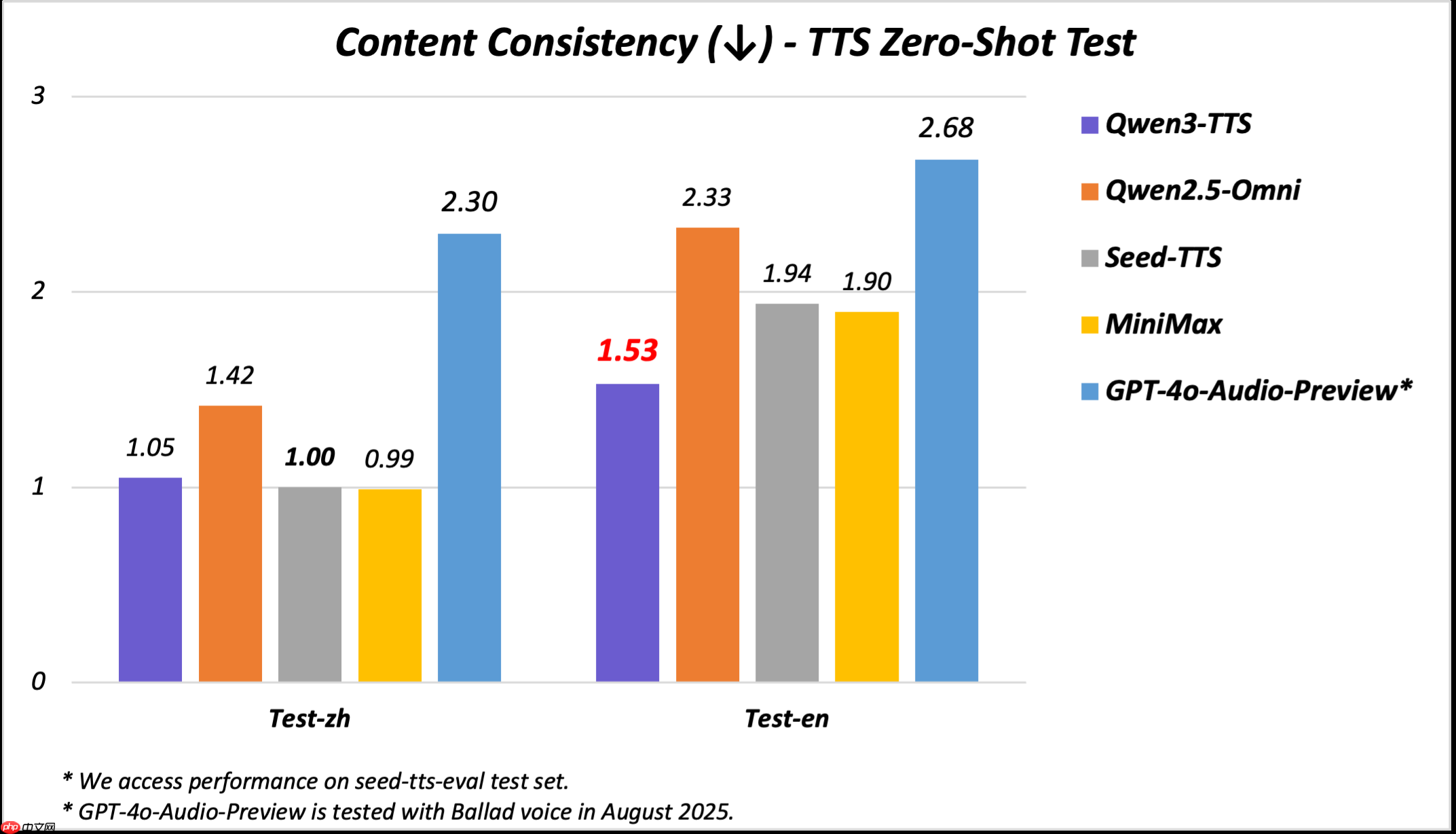
在seed-tts-eval测试集上的评估显示,Qwen3-TTS-Flash在中文和英文的语音稳定性方面均取得了最佳表现,明显优于SeedTTS、MiniMax以及GPT-4o-Audio-Preview等模型。
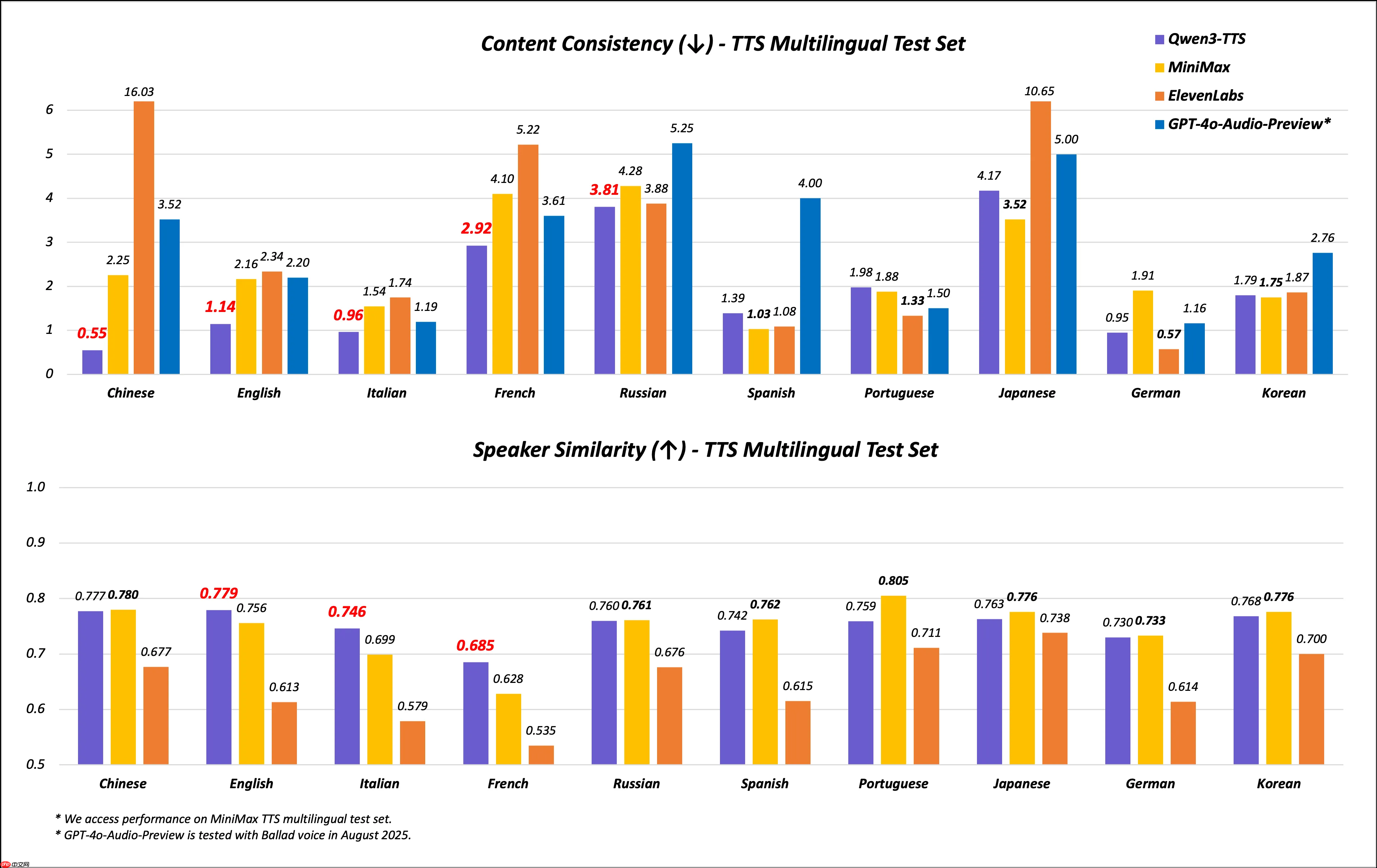
此外,在MiniMax多语言TTS测试集上,Qwen3-TTS-Flash在中文、英文、意大利语和法语的词错误率(WER)上均达到最低水平,显著优于MiniMax、ElevenLabs和GPT-4o-Audio-Preview。在说话人相似度方面,其在英文、意大利语和法语上的得分也全面领先,充分体现了其在多语言场景下的高质量合成能力。
作为一款统一架构的旗舰级语音合成模型,Qwen3-TTS-Flash支持17种不同音色,每种音色均可生成10种语言的语音内容。除中文方言外,模型还支持英式、美式及其他地区口音的英语,并涵盖法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语和韩语等多种国际语言。
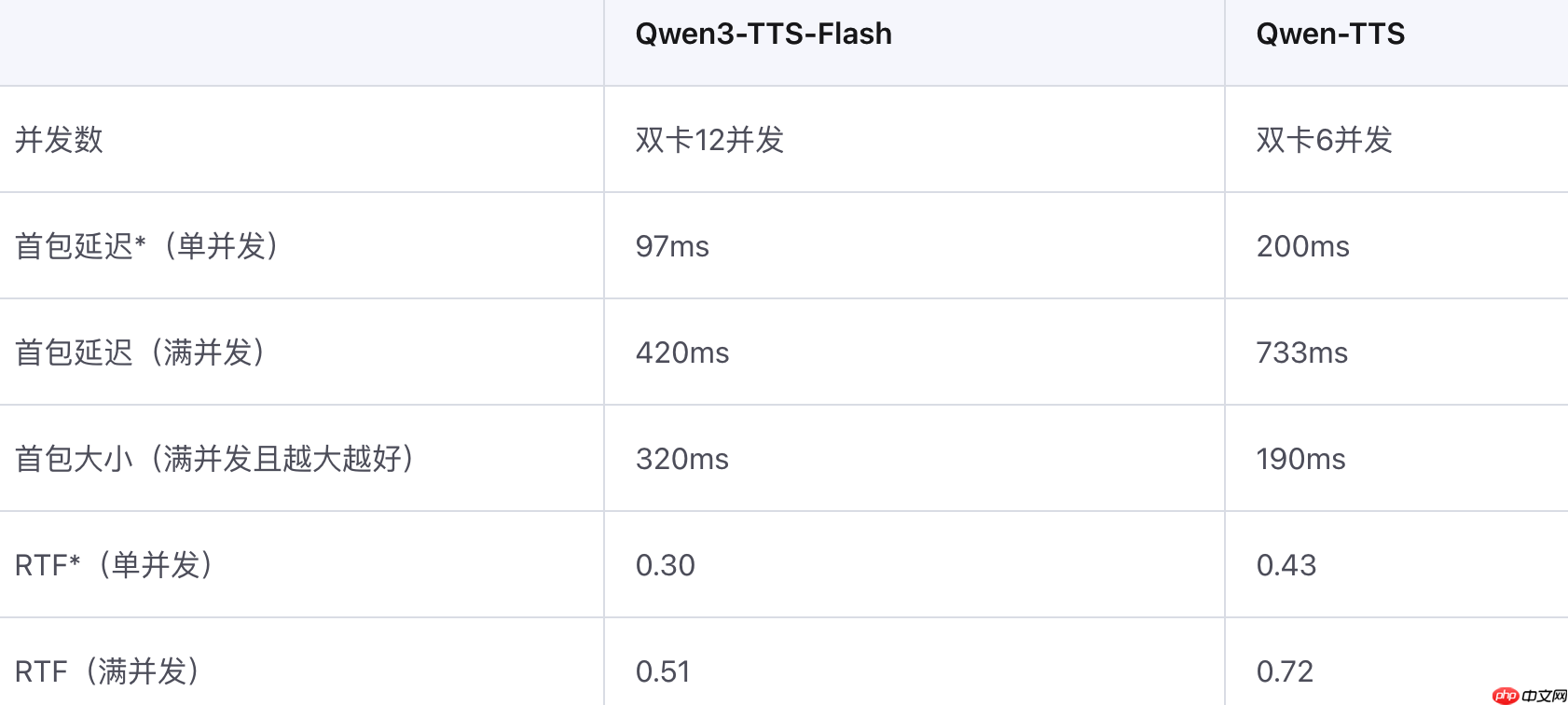
功能层面,Qwen3-TTS-Flash具备自动语气调节、强鲁棒性的文本预处理机制以及跨语种混合生成能力,能够应对复杂多变的实际应用场景。在推理效率方面,该模型表现出色:单并发情况下首包延迟低至97ms,满并发时为420ms,实时因子(RTF)最低可达0.30,兼顾了高质与高效。
以上就是阿里通义发布旗舰语音合成模型 Qwen3-TTS-Flash的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/91777.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 























