
captions
-
文生图的基石CLIP模型的发展综述

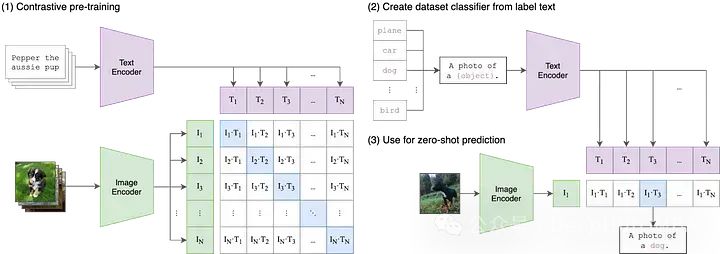


clip stands for contrastive language-image pre-training, which is a pre-training method or model based on contrastive text-image pairs. it is a multim…
-
微软赢麻了!数十亿文本-图像对训练,多模态Florence开启免费体验,登上Azure




2021年11月,微软发布了一个多模态视觉基础模型Florence(佛罗伦萨),横扫超过40个基准任务,轻松适用于如分类、目标检测、VQA、看图说话、视频检索和动作识别等多个任务。 时隔一年半,Florence正式开启商用阶段! Florence能干什么? 最近,微软全球人工智能首席技术官黄学东官宣…
-
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手




最近几年,「视频会议」在工作中的占比逐渐增加,厂商也开发了各种诸如实时字幕等技术以方便会议中不同语言的人之间交流。 但还有一个痛点,要是对话中提到了一些对方很陌生的名词,并且很难用语言描述出来,比如食物「寿喜烧」,或是说「上周去了某个公园度假」,很难用语言给对方描述出的美景;甚至是指出「东京位于日本…
-
在自定义数据集上实现OpenAI CLIP
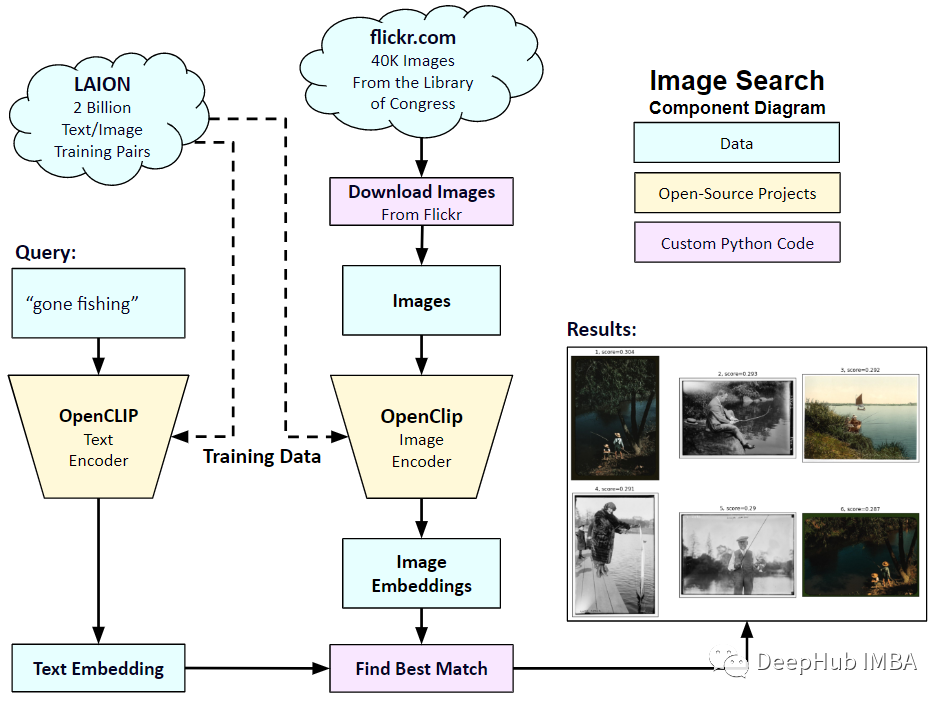

在2021年1月,openai宣布了两个新模型:dall-e和clip。这两个模型都是多模态模型,以某种方式连接文本和图像。clip的全称是对比语言-图像预训练(contrastive language-image pre-training),它是一种基于对比文本-图像对的预训练方法。为什么要介绍c…
-
清华大学新方法成功定位精确视频片段!SOTA被超越且已开源



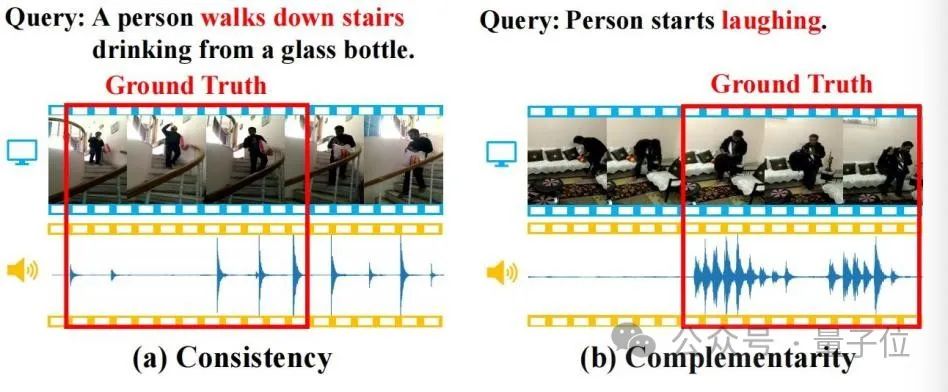
只需一句话描述,就能在一大段视频中定位到对应片段! 比如描述“一个人一边下楼梯一边喝水”,通过视频画面和脚步声的匹配,新方法一下子就能揪出对应起止时间戳: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 就连“大笑”这种语义难理解型的,也能准…
-
NeurIPS 2024 | 消除多对多问题,清华提出大规模细粒度视频片段标注新范式VERIFIED



☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢…
-
个人实现的反向文心(无需训练的AI看图说话,你不心动?)



本文介绍ZeroCap的中文Paddle迁移实现,这是一个零样本图像描述模型。项目用Ernie-VIL替换原论文的CLIP,GPT采用中文版,涉及GPTChineseTokenizer、GPTLMHeadModel等模型。代码包含安装库、模型初始化、定义相关函数及生成文本等内容,还展示了效果示例,适…
