
controlnet
-
利用PAI-DSW和SD WebUI实现AI扩图功能的方法



关于实现VB与matlab混合编程的方法 WORD版 本文档主要讲述的是关于实现VB与matlab混合编程的方法;介绍了vb与matlab混合编程的方法,二者结合可以充分利用vb的方便快捷和matlab软件工具箱的强大功能。 matlab是mathworks公司开发的科学计算环境,具有强大的计算绘图…
-
生成不了光线极强的图片?微信视觉团队有效解决扩散模型奇点问题


扩散模型在图像生成方面的色彩表现中发挥了作用,推动了生成式模型的新纪元。如Stable Diffusion、DALLE、Imagen、SORA等大模型如雨后春笋般涌现,进一步丰富了生成式AI的应用背景。然而,当前的扩散模型在理论上并非完美,鲜有研究关注到采样样本时段端点处未定义的奇点问题。此外,奇点…
-
用AI把自己画进动漫里,3天揽获150万+播放量,职业动画师:有被吓到



只需随手录制一段视频,AI就能把你完美放进动漫中! ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 无论是线条、色彩还是光影呈现,都与美漫中的写实风格如出一辙,动画也是细腻流畅,帧数显然不低: 制作这样一部包含120个VFX(视觉效果)镜头的…
-
新标题:TextDiffuser:无惧图像中的文字,提供更高质量的文本渲染


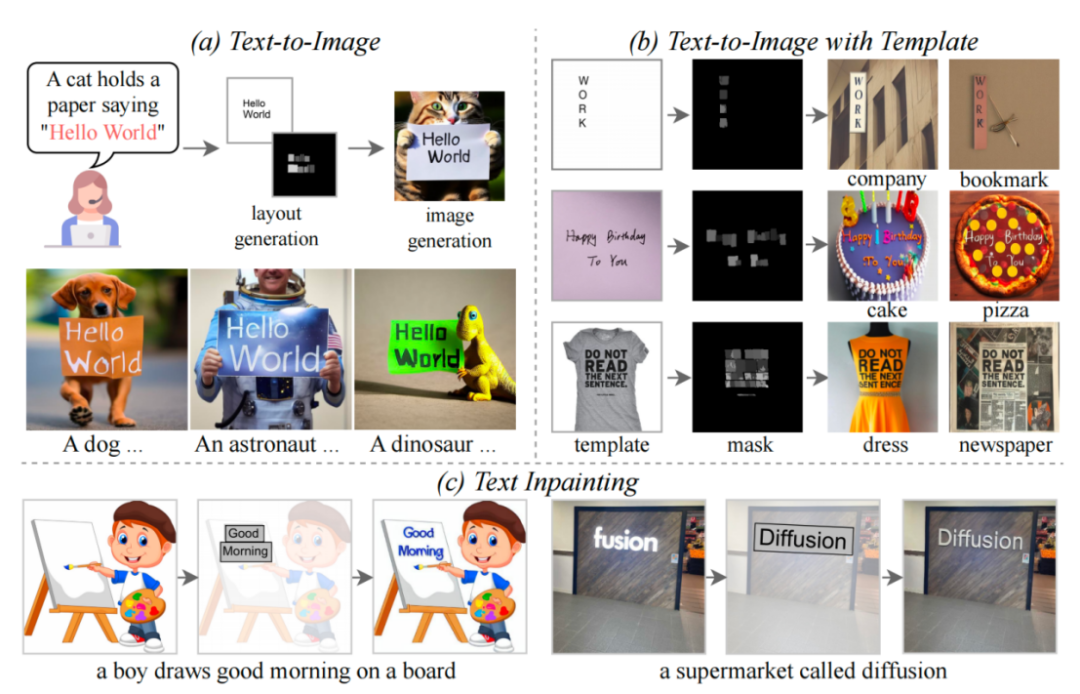
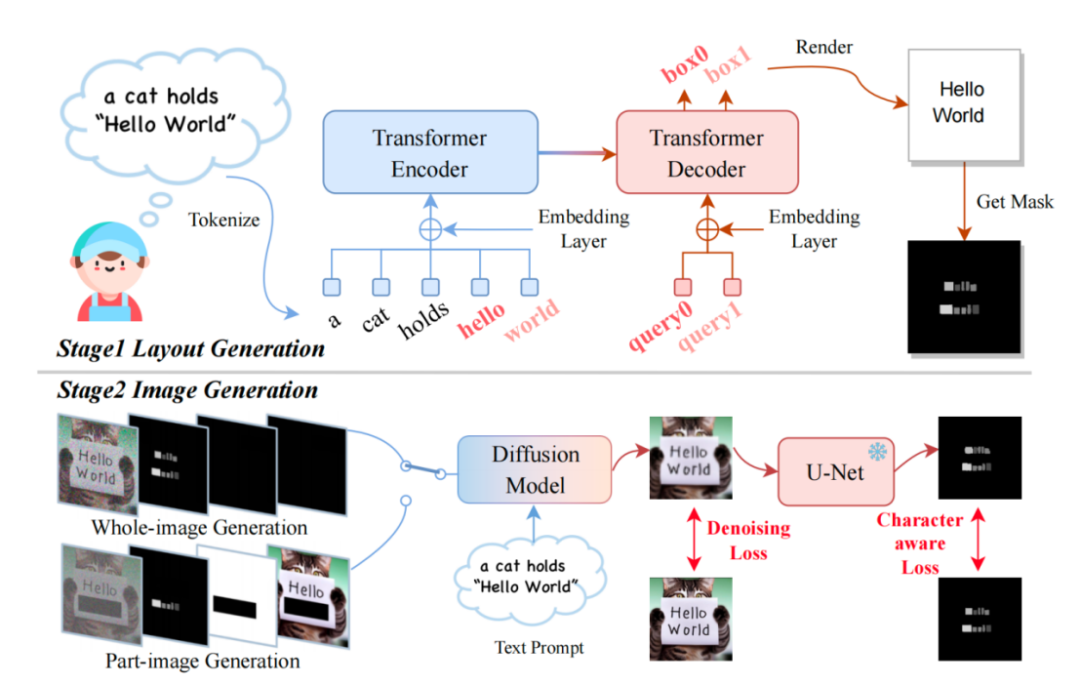
在过去几年中,Text-to-Image 领域取得了巨大的进展,特别是在人工智能生成内容(AIGC)的时代。随着DALL-E模型的兴起,学术界涌现出越来越多的Text-to-Image模型,比如Imagen、Stable Diffusion、ControlNet等模型。然而,尽管Text-to-Im…
-
可控图像生成最新综述!北邮开源20页249篇文献,包揽Text-to-Image Diffusion领域各种「条件」

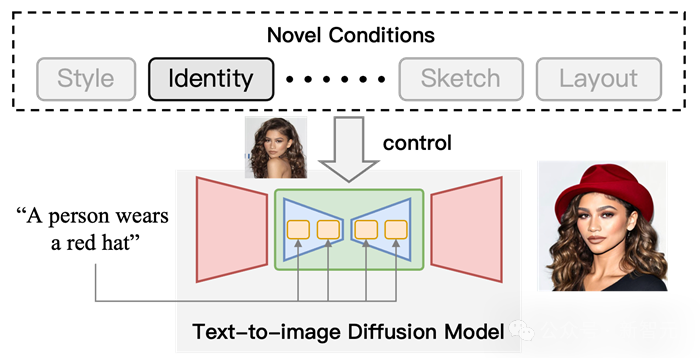
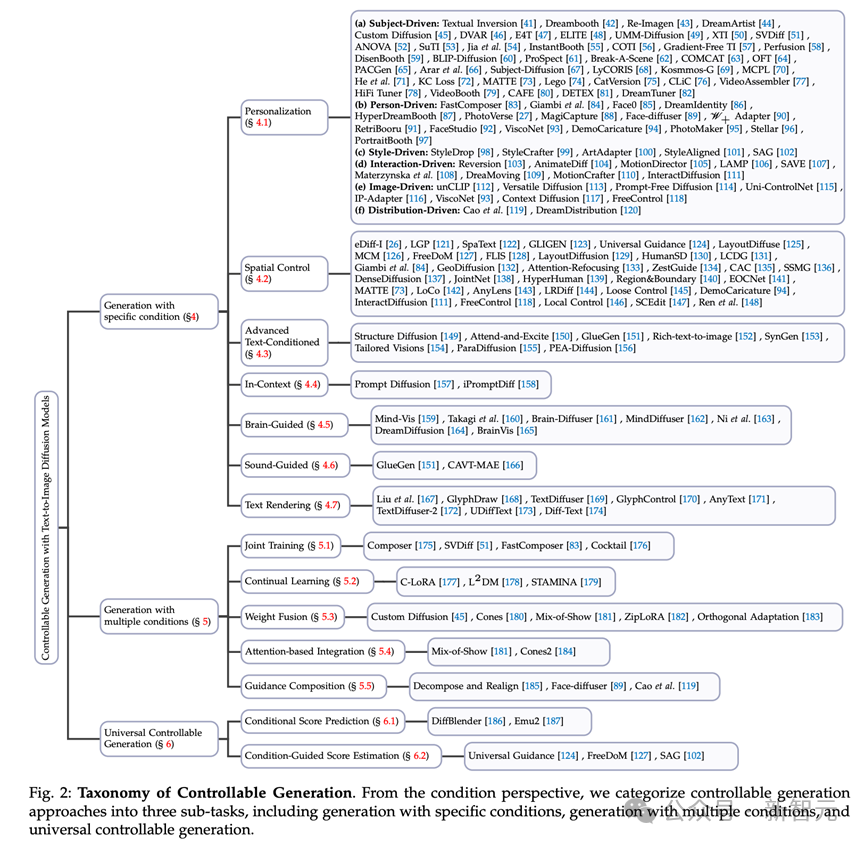

在视觉生成领域迅速发展的进程中,扩散模型已经完全改变了这一领域的发展态势,其引入的文本引导生成功能标志着能力方面的深刻变革。 然而,仅依赖文本来调节这些模型并不能完全满足不同应用和场景的多样化和复杂需求。 鉴于这种不足,许多研究旨在控制预训练文本到图像(T2I)模型以支持新条件。 北京邮电大学的研究…
-
AI出图更快、更美、更懂你心意,高美感文生图模型修炼了哪些技术秘籍?


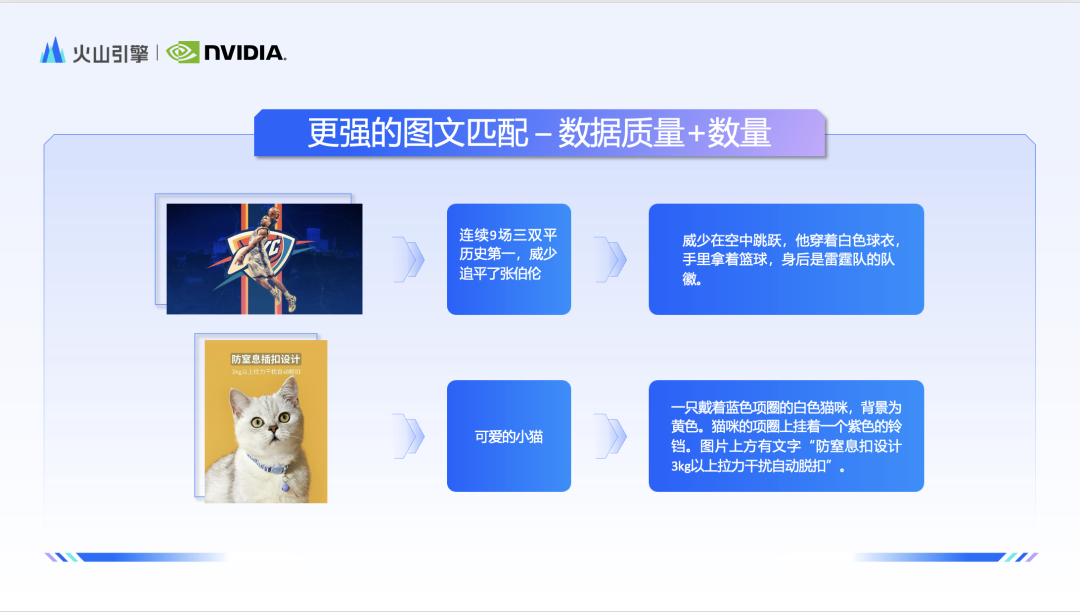
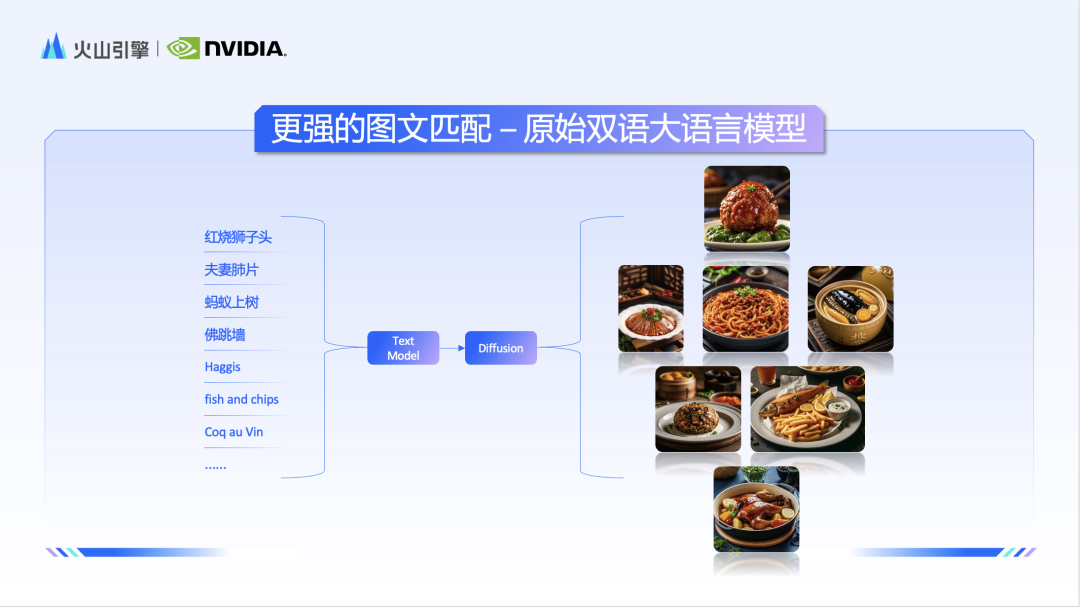
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 随着大模型的落地按下加速键,文生图无疑是最火热的应用方向之一。 自从 Stable Diffusion 诞生以来,海内外的文生图大模型层出不穷,一时有「神仙打架」之感。短短几个月,「最强 AI …
-
Midjourney V6手指画不好?超实用修手技巧和提示词模板
midjourney v6的手指问题可通过多种方法改善。1. 优化提示词,如明确手部描述、使用姿势引导、负面提示词及调整权重;2. 进行后期修复,利用photoshop、gimp等工具精细修改;3. 结合风格化参数,如–style raw和–stylize控制细节保留;4. …
-
StableDiffusion 画动漫角色?模型加载与风格融合技巧




要使用stable diffusion画出高质量的动漫角色,1. 首先选择适合的模型,如anything v3、pastel mix、counterfeit-v2.5,并参考civitai上的评分与评论;2. 融合多个模型以创造独特风格;3. 编写详细prompt并加入风格关键词,如“anime s…
-
阿里再次创新:通过一句话和人脸即可实现《擦玻璃》舞蹈,服装背景自由切换!




阿里巴巴又一篇名为“舞蹈整活儿”的论文在AnimateAnyone之后引起了轰动 现在,只要上传一张脸部照片并简单描述一句话,就可以在任何地方跳舞啦! 例如下面这段《擦玻璃》的舞蹈视频: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 图片 …
-
只需一张图片、一句动作指令,Animate124轻松生成3D视频


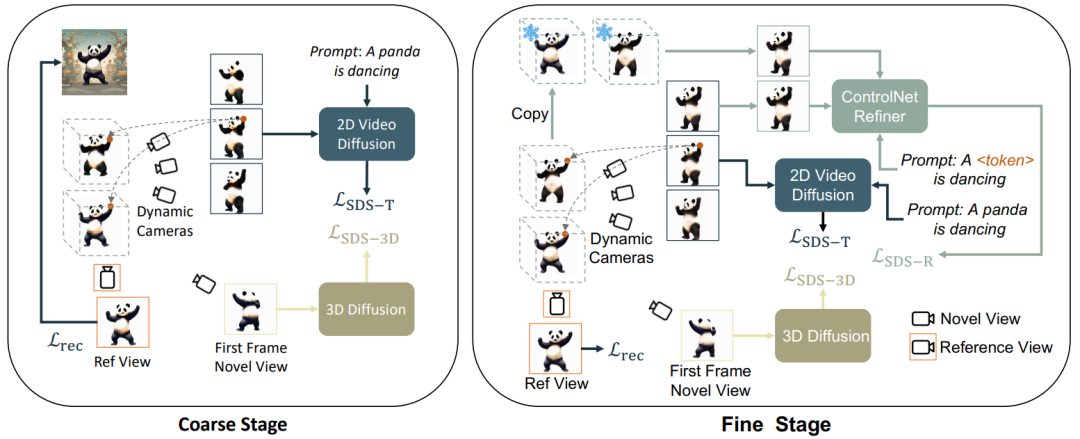

Animate124,轻松将单张图片变成 3D 视频。 近一年来,DreamFusion 引领了一个新潮流,即 3D 静态物体与场景的生成,这在生成技术领域引发了广泛关注。回顾过去一年,我们见证了 3D 静态生成技术在质量和控制性方面的显著进步。技术发展从基于文本的生成起步,逐渐融入单视角图像,进而…

