
controlnet
-
两步生成25帧高质量动画,计算为SVD的8% | 在线可玩




耗费的计算资源仅为传统stable video diffusion(svd)模型的2/25! AnimateLCM-SVD-xt发布,一改视频扩散模型进行重复去噪,既耗时又需大量计算的问题。 先来看一波生成的动画效果。 赛博朋克风轻松驾驭,男孩头戴耳机,站在霓虹闪烁的都市街道: ☞☞☞AI 智能聊天…
-
Up主已经开始鬼畜,腾讯开源「AniPortrait」让照片唱歌说话



aniportrait 模型是开源的,可以自由畅玩。 「小破站鬼畜区的新质生产力工具。」 近日,腾讯开源发布的一个新项目在推上获得了如此评价。这个项目是 AniPortrait,其可基于音频和一张参考图像生成高质量动画人像。 话不说多,我们先看看可能会被律师函警告的 demo: 动漫图像也能轻松开口…
-
生成越长越跑偏?浙大商汤新作StarGen让场景视频生成告别「短片魔咒」


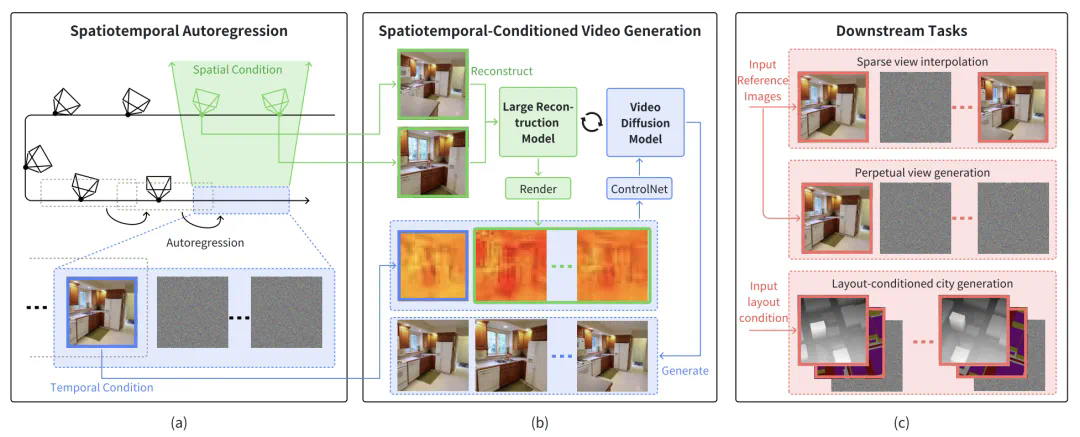
浙江大学和商汤科技的研究人员提出了一种名为stargen的新型时空自回归框架,用于实现可扩展且可控的场景生成。该框架巧妙地结合了空间和时间双重条件机制,将稀疏视图的3d几何信息与视频扩散模型有效融合,从而解决了复杂场景长距离生成中时空一致性难题,显著降低了误差累积。 ☞☞☞AI 智能聊天, 问答助手…
-
Stable Diffusion-XL开启公测,让你摆脱繁琐的长prompt!

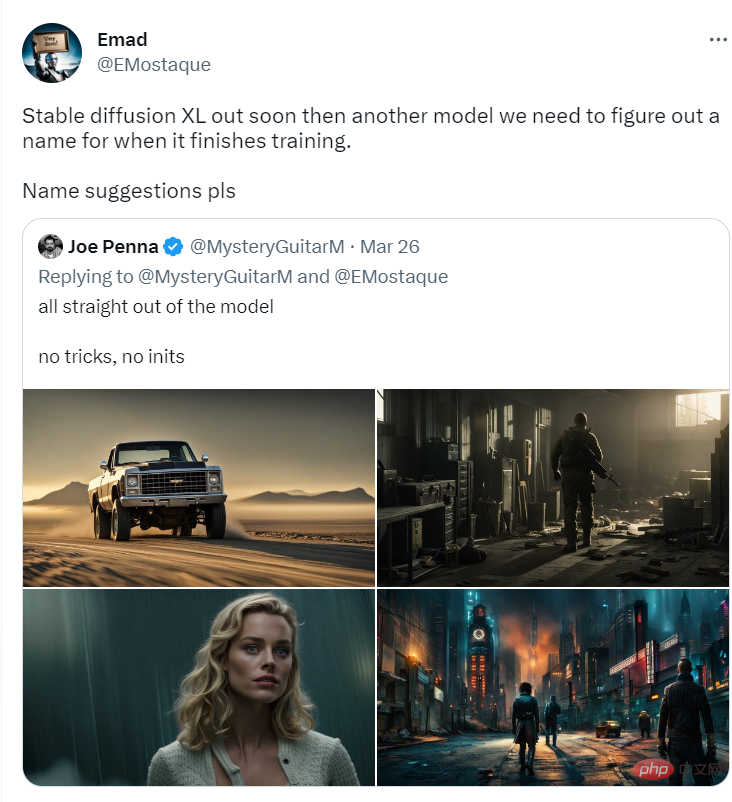

自从Midjourney发布v5之后,在生成图像的人物真实程度、手指细节等方面都有了显著改善,并且在prompt理解的准确性、审美多样性和语言理解方面也都取得了进步。 相比之下,Stable Diffusion虽然免费、开源,但每次都要写一大长串的prompt,想生成高质量的图像全靠多次抽卡。 最近…
-
使用AI画笔,我创造出缤纷多彩的图画!


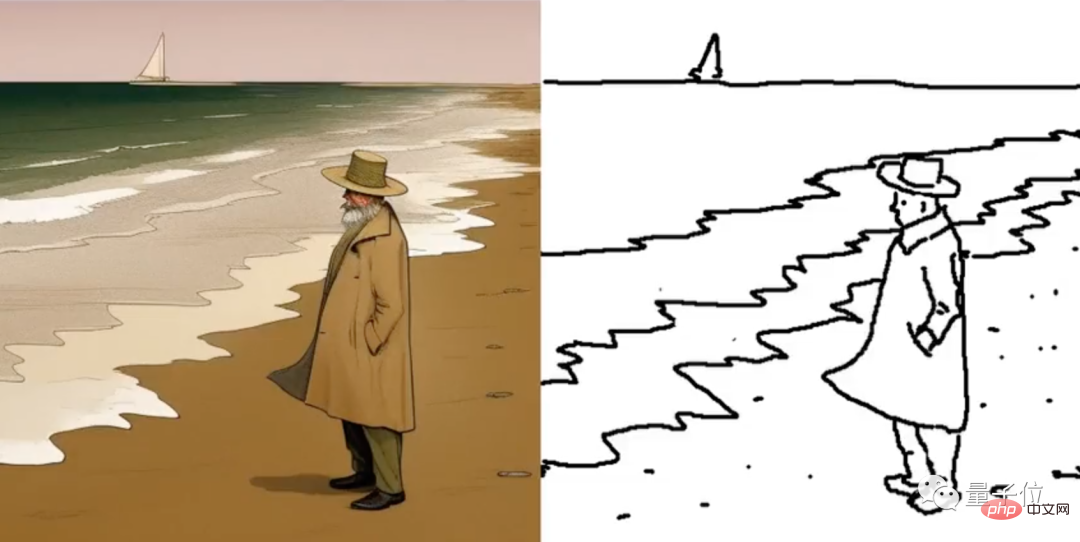

现在用ai画画,完整草图都不需要了。 每一笔落下,AI都会实时交上“新作业” ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 细节、颜色、画布空白,它都自动补全。 还能通过提示词来控制生成图像的内容和风格。 比如加一句“一个穿长外套的男人站在…
-
生成多语种文本与图片的全能工具AltDiffusion-m18



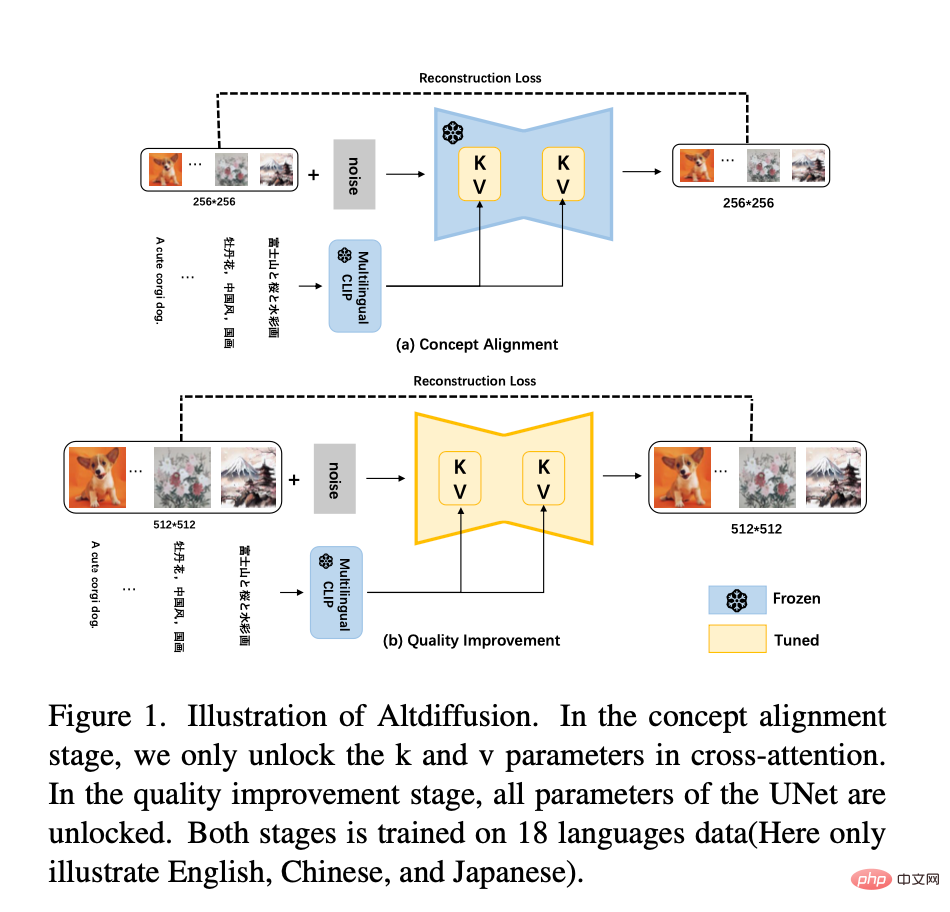
当前,非英文文图生成模型选择有限,用户往往要将 prompt 翻译成英语再输入模型。这样不仅会造成额外的操作负担,并且翻译过程中的语言文化误差,会影响生成图片的准确性。 智源研究院 FlagAI 团队首创高效训练方式,使用多语言预训练模型和 Stable Diffusion 结合,训练多语言文图生成…
-
时间、空间可控的视频生成走进现实,阿里大模型新作VideoComposer火了


在 AI 绘画领域,阿里提出的 Composer 和斯坦福提出的基于 Stable diffusion 的 ControlNet 引领了可控图像生成的理论发展。但是,业界在可控视频生成上的探索依旧处于相对空白的状态。 相比于图像生成,可控的视频更加复杂,因为除了视频内容的空间的可控性之外,还需要满足…
-
盘清AI的用途后,这位画师不再感到焦虑




请注意,以下内容仅代表个人对工作流程的总结和行业思考,可能并不详尽,也没有涉及太多技术细节。如果您有其他想法,欢迎交流 有部分科普性质文字,同专业同学可以只看第4和第5部分。 导读: 需要重新写的内容是:1. 不同AIGC软件的效果图 2. 原理阐述和软件选择 3. AIGC工业化到底是什么 4. …
-
高通孟樸:5G与AI协同发展,加速开启无线通信新机遇


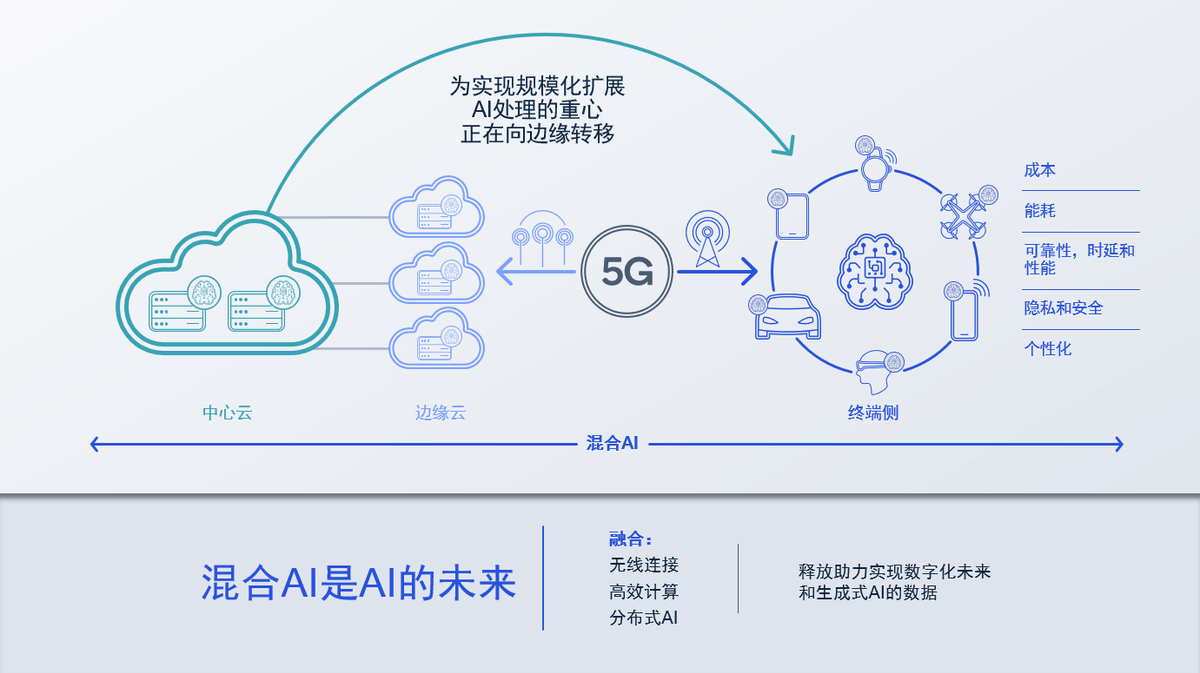

2023年9月14日,中国无线电大会正式开始。此次大会的重点是探讨前沿的无线电技术和产业发展动态,共同构建一个无线领域的交流平台,为实现高质量的发展共同努力。在开幕式暨主论坛上,高通公司中国区董事长孟樸发表了主题为“5g与ai赋能数字未来”的演讲 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索,…
-
手机上图像0.2秒即可呈现,谷歌构建最快的移动扩散模型MobileDiffusion


在手机等移动端侧运行 Stable Diffusion 等文生图生成式 AI 大模型已经成为业界追逐的热点之一,其中生成速度是主要的制约因素。 近日,来自谷歌的一篇论文「MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Dev…
