
大型语言模型
-
微软首次推出27亿参数的Phi-2模型,性能超过许多大型语言模型
微软发布了一款名为Phi-2的人工智能模型,该模型表现出了不凡的能力,其性能可媲美甚至超越规模是其25倍的、更大、更成熟的模型。 最近微软在一篇博文中宣布Phi-2是一个拥有27亿参数的语言模型,相比其他基础模型,Phi-2表现出先进的性能,特别是在复杂的基准测试中,这些测试评估了推理、语言理解、数…
-
使用GaLore在本地GPU进行高效的LLM调优
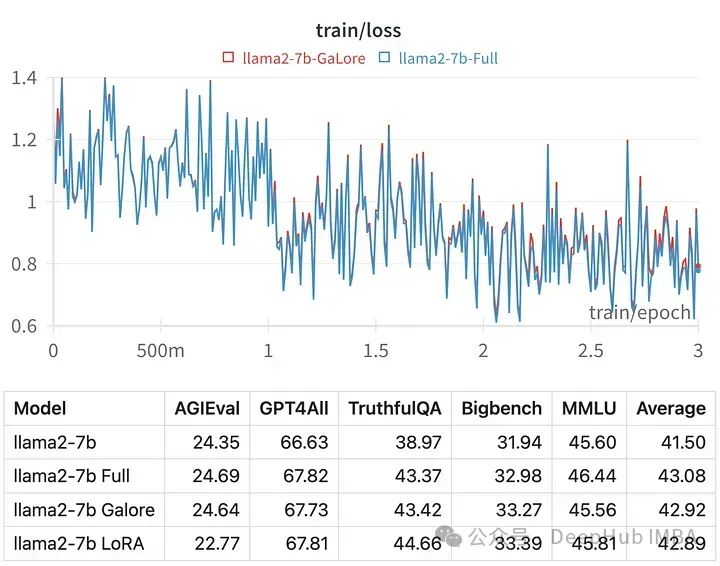



训练大型语言模型(llm)是一项计算密集型的任务,即使是那些“只有”70亿个参数的模型也是如此。这种级别的训练需要的资源超出了大多数个人爱好者的能力范围。为了弥补这一差距,出现了低秩适应(lora)等参数高效方法,使得在消费级gpu上可以对大量模型进行微调。 GaLore是一种创新方法,它采用优化参…
-
为什么大型语言模型都在使用 SwiGLU 作为激活函数?

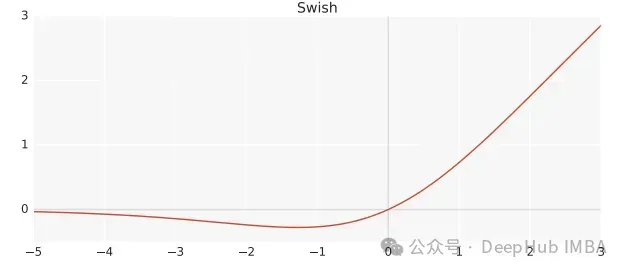
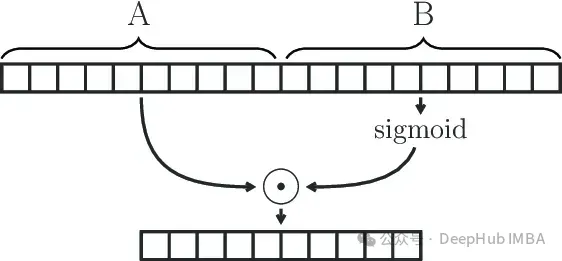
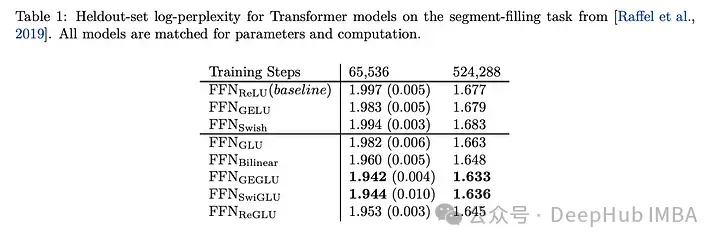
如果你一直在关注大型语言模型的架构,你可能会在最新的模型和研究论文中看到“SwiGLU”这个词。SwiGLU可以说是在大语言模型中最常用到的激活函数,我们本篇文章就来对它进行详细的介绍。SwiGLU其实是2020年谷歌提出的激活函数,它结合了SWISH和GLU两者的特点。SwiGLU的中文全称是“双…
-
不仅仅依赖庞大模型,构建生成式人工智能的要求更多
生成式人工智能(GenAI)的迅速崛起使得企业争相寻找新的创新方法来利用这项技术在商业应用中的力量。许多企业认为,大型语言模型(LLM)已经重塑了人工智能驱动的商业应用程序的构建方式,所需要的只是将数据输入到大型企业的LLM模型中,它就会完成工作。然而,事情并没有那么容易 ☞☞☞AI 智能聊天, 问…
-
对大规模机器学习中幻觉缓解技术的综合研究
大型语言模型(LLMs)是具有大量参数和数据的深度神经网络,能够在自然语言处理(NLP)领域实现多种任务,如文本理解和生成。近年来,随着计算能力和数据规模的提升,LLMs取得了令人瞩目的进展,如GPT-4、BART、T5等,展现了强大的泛化能力和创造力。 LLMs也存在严重的问题,在生成文本时容易产…
-
利用知识图谱增强RAG模型的能力和减轻大模型虚假印象
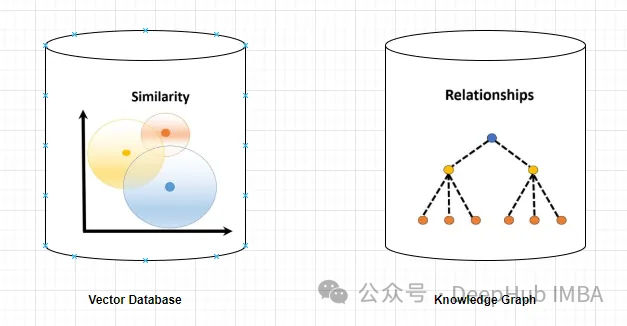

在使用大型语言模型(llm)时,幻觉是一个常见问题。尽管llm可以生成流畅连贯的文本,但其生成的信息往往不准确或不一致。为了防止llm产生幻觉,可以利用外部的知识来源,比如数据库或知识图谱,来提供事实信息。这样一来,llm可以依赖这些可靠的数据源,从而生成更准确和可靠的文本内容。 向量数据库和知识图…
-
使用SPIN技术进行自我博弈微调训练的LLM的优化
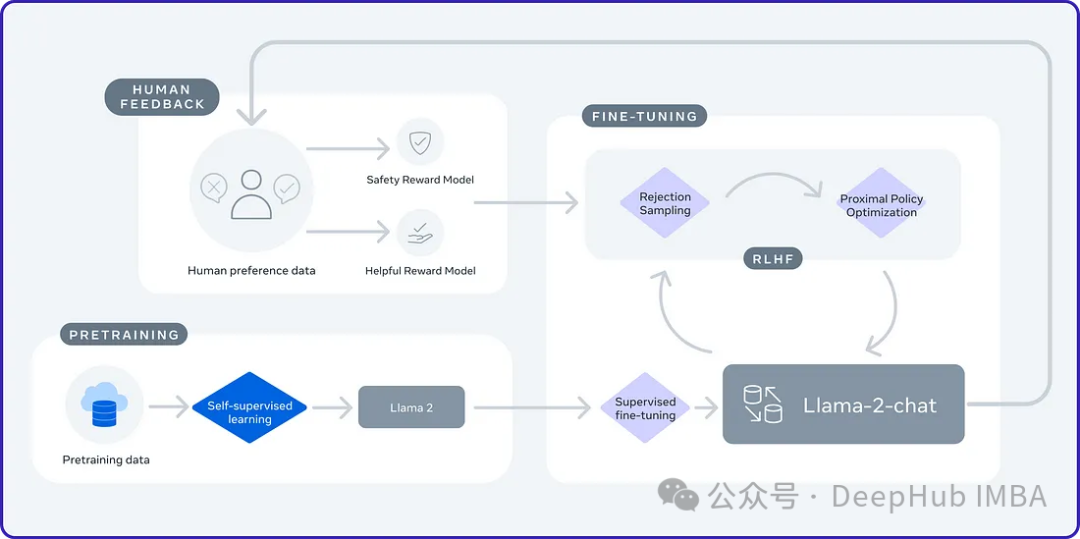
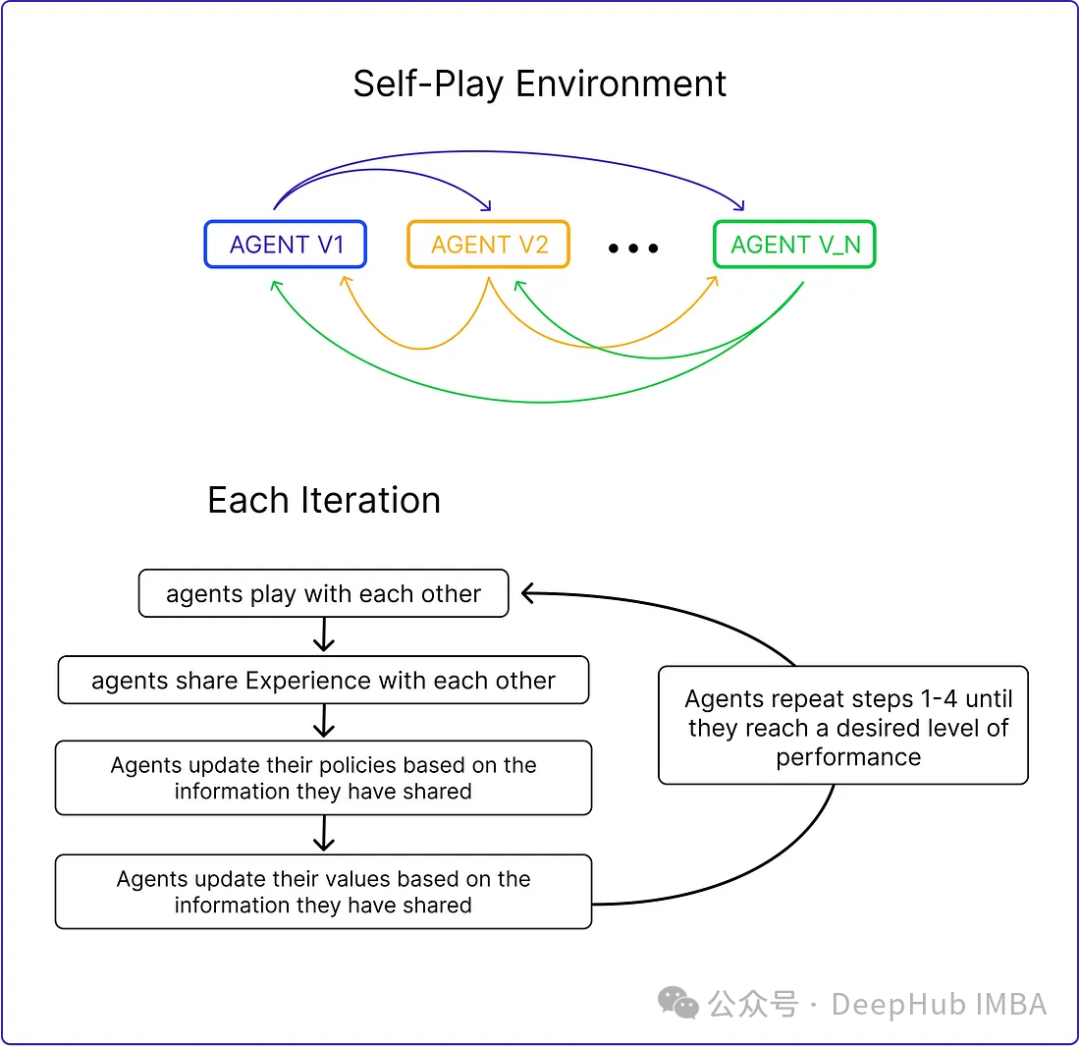


2024年是大型语言模型(llm)迅速发展的一年。在llm的训练中,对齐方法是一个重要的技术手段,其中包括监督微调(sft)和依赖人类偏好的人类反馈强化学习(rlhf)。这些方法在llm的发展中起到了至关重要的作用,但是对齐方法需要大量的人工注释数据。面对这一挑战,微调成为一个充满活力的研究领域,研…
-
揭开大型语言模型(LLM)的力量:初创企业如何通过精简集成彻底改变运营方式


大型语言模型 (LLM) 已成为各种规模企业的游戏规则改变者,但它们对初创企业的影响尤为显著。为了理解其中的原因,让我们来看看初创企业相对于老牌企业有哪些优势,以及为什么AI是它们的重要推动力。首先,与传统企业相比,初创企业有更大的灵活性。它们通常没有过多的层级和繁琐的决策程序,可以更迅速地适应市场…
-
AI代理平台选型与实施:五大关键步骤助你成功落地
ai代理构建平台正以前所未有的速度发展,选择合适的平台对企业至关重要。本文将为您提供一些建议,助您和团队以及供应商共同实现创新。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 如今,CIO和IT团队正从评估独立的AI软件包转向集成自定义AI…




