
感知
-
瑞声科技亮相 2024 吴声年度演讲:想象例外,感知解决方案刷新场景流




2024 年 8 月 4 日,新物种爆炸 · 吴声商业方法发布 2024 于北京如约启幕。现场,场景实验室创始人、新物种实验计划发起人吴声以 ” 成为自己 ” 为演讲主题,完成了多个场景品牌故事分享。作为新物种爆炸 2024 案例,瑞声科技感知解决方案进一步被推到台前,吸引了…
-
人形机器人首次打通视觉感知与运动断层,UC 伯克利华人博士让宇树 G1 现场演示




不用提前熟悉环境,一声令下,就能让宇树机器人坐在椅子上、桌子上、箱子上! 还能直接解锁 ” 跨过箱子 “、” 敲门 ” 等任务 ~ 这是来自 UC 伯克利、卡内基梅隆大学等团队的最新研究成果LeVERB 框架—— 基于模拟数据训练实现零样本部署,让人形…
-
钛媒体科股早知道:自动驾驶+人型机器人,该重要器件为感知的基础和核心




☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 重写后的内容:重要要闻一:自动驾驶和人型机器人,这两个领域的重要组成部分是感知技术的基础和核心 机构指出,GNSS/IMU的组合导航系统,可充分发挥GNSS长期高精度性能和IMU短期高精度性能的…
-
AI 视频是否符合物理规律,量化基准来了,实现人类感知对齐
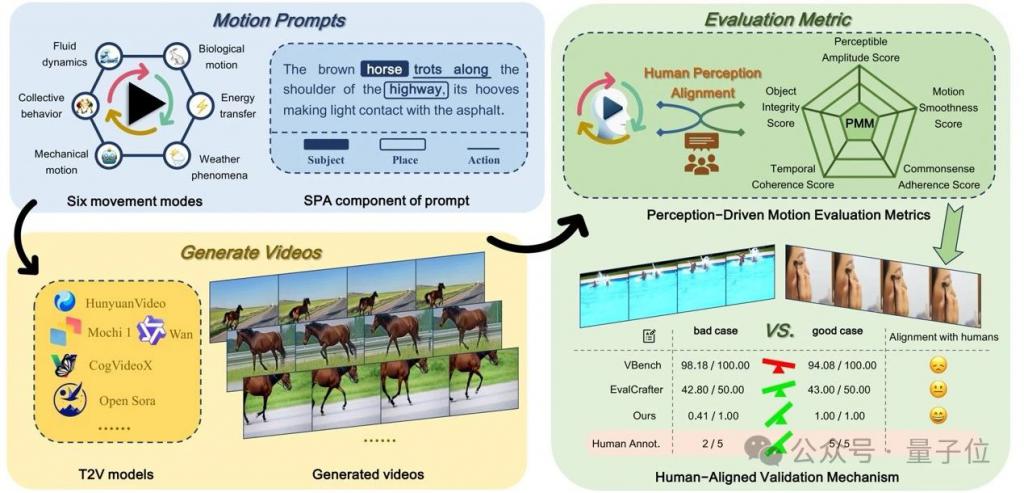

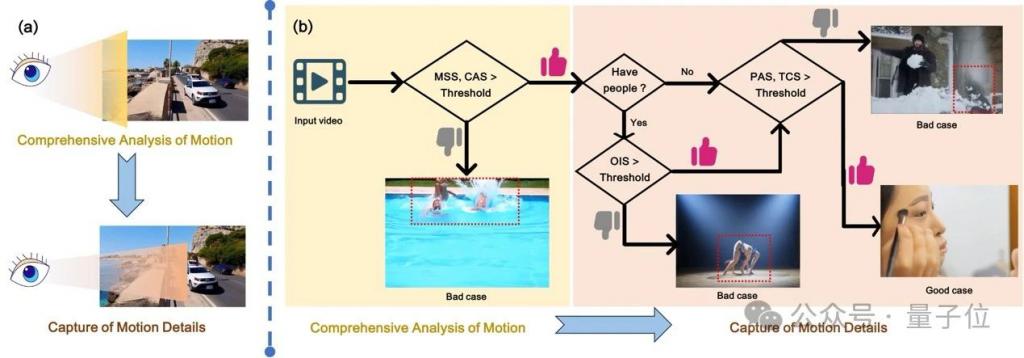
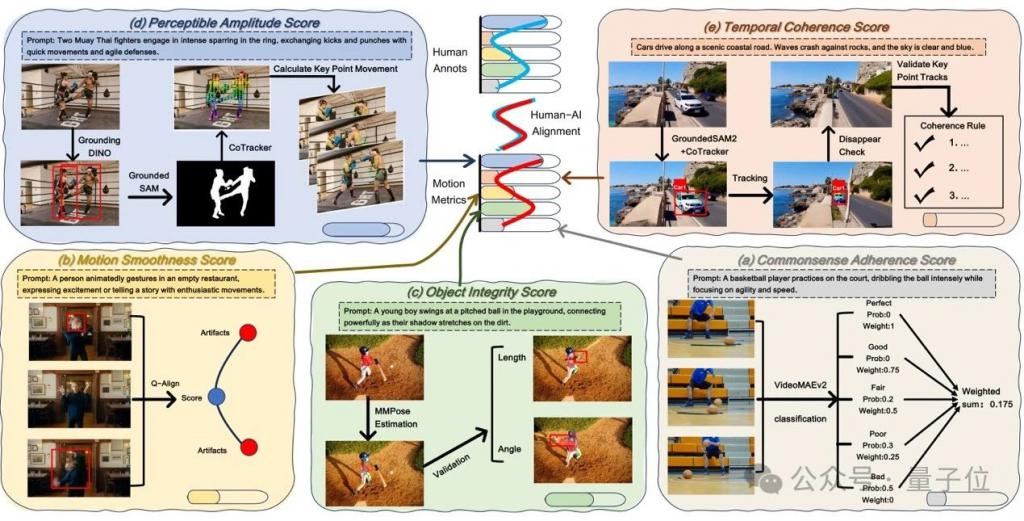
测一测现有 ai 生成视频是否符合物理运动规律! 来自阿里 – 高德、中科院的研究人员提出一个面向感知对齐的视频运动生成基准。 名为VMBench,是首个开源的运动质量评测基准,通过整合运动评估指标与人类感知对齐的评测方法,揭示现有模型在生成物理合理运动方面的不足。 △图 1 VMBen…
-
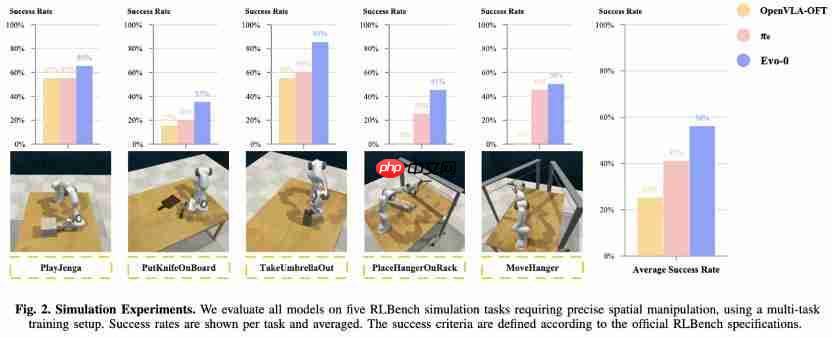
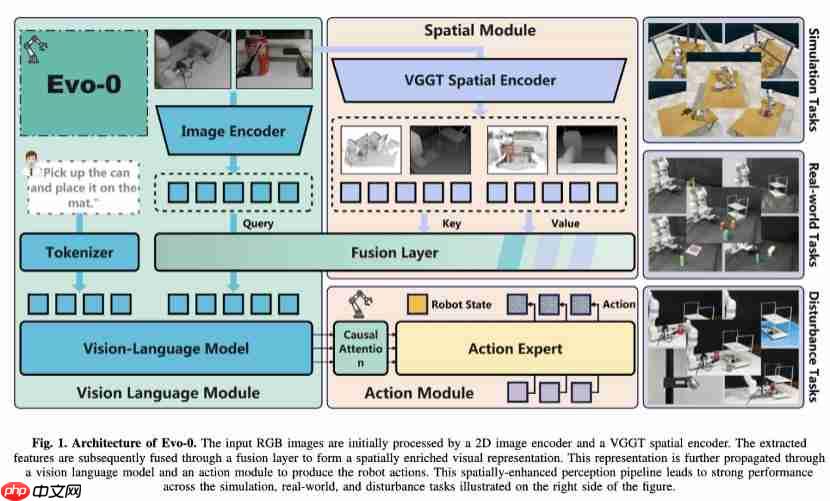
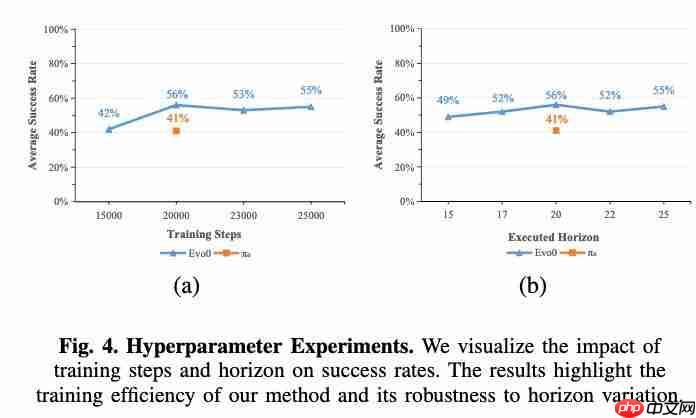
机器人感知大升级!轻量化注入几何先验,成功率提升 31%

在机器人学习领域,让 ai 真正“看懂”三维世界始终是一个核心挑战。 现有的视觉语言动作(VLA)模型大多基于预训练的视觉语言模型(VLM),仅利用 2D 图像-文本对进行训练,缺乏对真实操作至关重要的 3D 空间感知能力。 虽然当前一些方法通过引入显式深度信息来增强模型,但这类方案通常依赖额外的深…
