
火车头采集器
-
火车头采集器如何过滤重复数据项_火车头采集器重复过滤的去重算法




答案:火车头采集器可通过启用内置去重、自定义规则、数据库约束及外部脚本清洗四种方式过滤重复数据。首先在数据处理中开启重复过滤并设置唯一标识字段,其次通过高级条件判断结合变量或数据库查询实现精准去重,再者利用数据库主键防止重复入库,最后可用Python等脚本对导出文件批量清理,确保数据唯一性。 如果您…
-
LocoySpider如何集成自然语言处理_LocoySpiderNLP集成的文本分析


可通过集成NLP技术实现LocoySpider采集内容的智能语义识别与分类。一、调用外部API如百度AI、阿里云NLP等,通过HTTP请求发送采集文本,解析返回的JSON获取情感分析、关键词、实体等结果,并写入数据库,同时设置频率限制与重试机制防封禁。二、部署本地NLP模型,选用Jieba、HanL…
-
LocoySpider如何设置多任务并发_LocoySpider并发任务的队列管理

启用多任务并发需在系统设置中选择并发模式并设最大任务数,配置任务优先级确保关键任务优先执行,通过分组管理分类任务并限制各组并发量,调整每任务线程数优化性能,实时监控资源使用情况并动态调整运行状态以提升LocoySpider采集效率。 如果您在使用LocoySpider进行数据采集时希望提升效率,通过…
-
LocoySpider如何采集多页列表数据_LocoySpider分页采集的循环规则


首先确保分页规则正确,根据网站结构选择文本循环、URL参数递增或XPath提取下一页链接方式,配置循环逻辑并关联解析节点,实现多页数据完整抓取。 如果您在使用LocoySpider进行数据采集时遇到多页列表无法完整抓取的问题,通常是因为分页规则设置不正确或循环逻辑未匹配目标网站的翻页结构。以下是实现…
-
火车头采集器如何自定义数据清洗脚本_火车头采集器清洗脚本的正则替换
答案:通过自定义PHP脚本和正则替换组合清洗数据。先在火车头采集器中启用自定义处理脚本,使用strip_tags和preg_replace去除HTML标签与多余空格;再对特定字段应用正则替换,清除广告、页码等固定噪声;最后按顺序组合移除HTML、正则替换、去空白符及格式统一等多方式,确保数据整洁规范…
-
火车头采集器如何提取HTML标签属性_火车头采集器属性提取的规则定义



首先使用火车头采集器内置功能提取HTML标签属性,通过选中元素自动获取href、src等属性值;接着可手动编写XPath规则提高精度,如//img[@class=’thumb’]/@src提取特定图片地址;对于动态内容可用正则表达式捕获非标准属性,例如data-origina…
-
LocoySpider如何设置数据清洗规则_LocoySpider清洗规则的正则替换

答案:通过设置清洗规则优化LocoySpider采集数据。首先进入字段清洗界面,点击“清洗”按钮添加规则;接着使用正则替换删除冗余字符,如用s+匹配空白并留空替换实现去空格;也可选择内置模板快速去除HTML标签或换行符;最后支持多规则顺序执行,按需调整优先级确保清洗逻辑正确,保存后运行任务验证效果。…
-
LocoySpider如何调试爬虫脚本错误_LocoySpider脚本调试的排查方法

首先检查网页加载与元素定位是否准确,确认选择器有效且页面完全加载;接着验证脚本语法与变量定义,确保无拼写错误并正确声明变量;然后测试分页规则,保证翻页链接可提取并支持JavaScript翻页;再分析网络请求状态,核对请求头信息并应对反爬机制;最后启用调试模式逐步执行,观察数据提取结果与逻辑分支执行情…
-
火车头采集器如何批量采集列表页面_火车头采集器列表页面的循环抓取


首先配置起始URL并设置分页规则,启用“列表页循环抓取”,填写带页码变量的下一页网址规则如http://example.com/list_*.html,并设定页码范围;其次针对不规则分页结构,在高级选项中使用正则表达式提取链接,例如匹配模式,将所有列表页链接导入采集队列;最后通过XPath定位列表项…
-
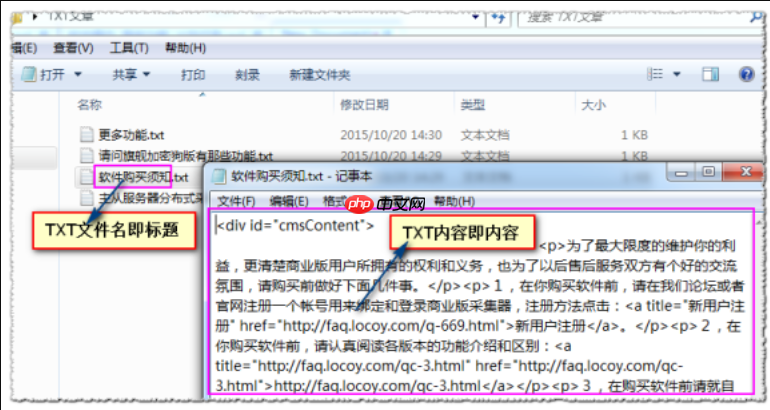
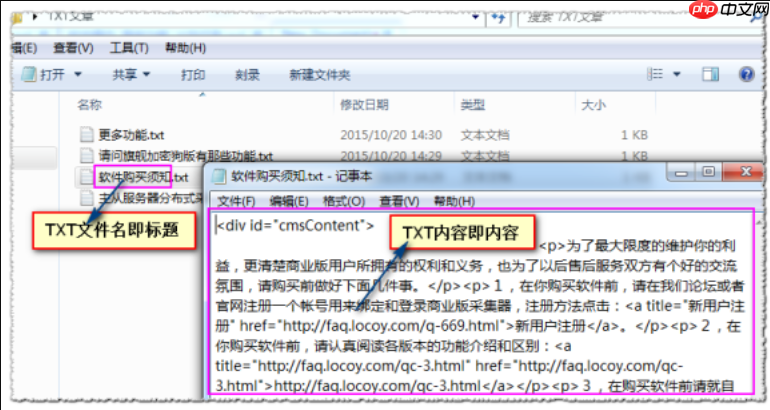
火车头采集器如何自定义导出格式模板_火车头采集器模板导出的字段映射
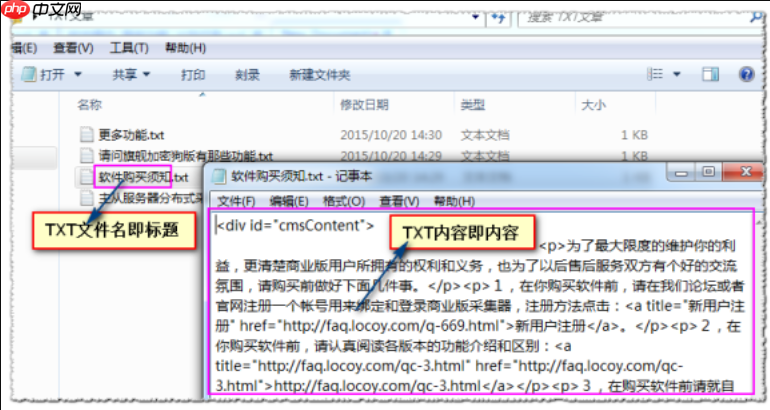

1、创建自定义导出模板需进入采集项目导出数据界面,选择“自定义导出模板”并新建,设置模板名称及格式类型(如JSON、CSV),在编辑区编写模板代码实现字段占位与格式控制,保存后选用该模板进行导出。2、配置字段映射关系时,在导出向导的字段设置页面编辑各字段别名,将采集器字段(如{article_tit…

